 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToLeaP: Rethinking Development of Tool Learning with Large Language Models
May 17, 2025



Tool learning, which enables large language models (LLMs) to utilize external tools effectively, has garnered increasing attention for its potential to revolutionize productivity across industries. Despite rapid development in tool learning, key challenges and opportunities remain understudied, limiting deeper insights and future advancements. In this paper, we investigate the tool learning ability of 41 prevalent LLMs by reproducing 33 benchmarks and enabling one-click evaluation for seven of them, forming a Tool Learning Platform named ToLeaP. We also collect 21 out of 33 potential training datasets to facilitate future exploration. After analyzing over 3,000 bad cases of 41 LLMs based on ToLeaP, we identify four main critical challenges: (1) benchmark limitations induce both the neglect and lack of (2) autonomous learning, (3) generalization, and (4) long-horizon task-solving capabilities of LLMs. To aid future advancements, we take a step further toward exploring potential directions, namely (1) real-world benchmark construction, (2) compatibility-aware autonomous learning, (3) rationale learning by thinking, and (4) identifying and recalling key clues. The preliminary experiments demonstrate their effectiveness, highlighting the need for further research and exploration.
Search and Refine During Think: Autonomous Retrieval-Augmented Reasoning of LLMs
May 16, 2025Large language models have demonstrated impressive reasoning capabilities but are inherently limited by their knowledge reservoir. Retrieval-augmented reasoning mitigates this limitation by allowing LLMs to query external resources, but existing methods often retrieve irrelevant or noisy information, hindering accurate reasoning. In this paper, we propose AutoRefine, a reinforcement learning post-training framework that adopts a new ``search-and-refine-during-think'' paradigm. AutoRefine introduces explicit knowledge refinement steps between successive search calls, enabling the model to iteratively filter, distill, and organize evidence before generating an answer. Furthermore, we incorporate tailored retrieval-specific rewards alongside answer correctness rewards using group relative policy optimization. Experiments on single-hop and multi-hop QA benchmarks demonstrate that AutoRefine significantly outperforms existing approaches, particularly in complex, multi-hop reasoning scenarios. Detailed analysis shows that AutoRefine issues frequent, higher-quality searches and synthesizes evidence effectively.
Ultra-FineWeb: Efficient Data Filtering and Verification for High-Quality LLM Training Data
May 08, 2025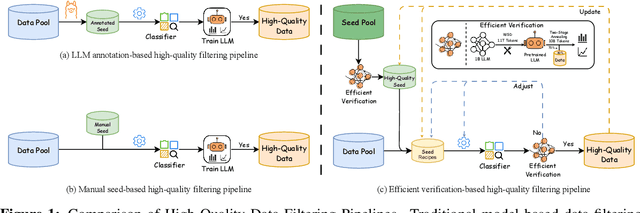



Data quality has become a key factor in enhancing model performance with the rapid development of large language models (LLMs). Model-driven data filtering has increasingly become a primary approach for acquiring high-quality data. However, it still faces two main challenges: (1) the lack of an efficient data verification strategy makes it difficult to provide timely feedback on data quality; and (2) the selection of seed data for training classifiers lacks clear criteria and relies heavily on human expertise, introducing a degree of subjectivity. To address the first challenge, we introduce an efficient verification strategy that enables rapid evaluation of the impact of data on LLM training with minimal computational cost. To tackle the second challenge, we build upon the assumption that high-quality seed data is beneficial for LLM training, and by integrating the proposed verification strategy, we optimize the selection of positive and negative samples and propose an efficient data filtering pipeline. This pipeline not only improves filtering efficiency, classifier quality, and robustness, but also significantly reduces experimental and inference costs. In addition, to efficiently filter high-quality data, we employ a lightweight classifier based on fastText, and successfully apply the filtering pipeline to two widely-used pre-training corpora, FineWeb and Chinese FineWeb datasets, resulting in the creation of the higher-quality Ultra-FineWeb dataset. Ultra-FineWeb contains approximately 1 trillion English tokens and 120 billion Chinese tokens. Empirical results demonstrate that the LLMs trained on Ultra-FineWeb exhibit significant performance improvements across multiple benchmark tasks, validating the effectiveness of our pipeline in enhancing both data quality and training efficiency.
LecEval: An Automated Metric for Multimodal Knowledge Acquisition in Multimedia Learning
May 04, 2025Evaluating the quality of slide-based multimedia instruction is challenging. Existing methods like manual assessment, reference-based metrics, and large language model evaluators face limitations in scalability, context capture, or bias. In this paper, we introduce LecEval, an automated metric grounded in Mayer's Cognitive Theory of Multimedia Learning, to evaluate multimodal knowledge acquisition in slide-based learning. LecEval assesses effectiveness using four rubrics: Content Relevance (CR), Expressive Clarity (EC), Logical Structure (LS), and Audience Engagement (AE). We curate a large-scale dataset of over 2,000 slides from more than 50 online course videos, annotated with fine-grained human ratings across these rubrics. A model trained on this dataset demonstrates superior accuracy and adaptability compared to existing metrics, bridging the gap between automated and human assessments. We release our dataset and toolkits at https://github.com/JoylimJY/LecEval.
IDDM: Bridging Synthetic-to-Real Domain Gap from Physics-Guided Diffusion for Real-world Image Dehazing
Apr 30, 2025Due to the domain gap between real-world and synthetic hazy images, current data-driven dehazing algorithms trained on synthetic datasets perform well on synthetic data but struggle to generalize to real-world scenarios. To address this challenge, we propose \textbf{I}mage \textbf{D}ehazing \textbf{D}iffusion \textbf{M}odels (IDDM), a novel diffusion process that incorporates the atmospheric scattering model into noise diffusion. IDDM aims to use the gradual haze formation process to help the denoising Unet robustly learn the distribution of clear images from the conditional input hazy images. We design a specialized training strategy centered around IDDM. Diffusion models are leveraged to bridge the domain gap from synthetic to real-world, while the atmospheric scattering model provides physical guidance for haze formation. During the forward process, IDDM simultaneously introduces haze and noise into clear images, and then robustly separates them during the sampling process. By training with physics-guided information, IDDM shows the ability of domain generalization, and effectively restores the real-world hazy images despite being trained on synthetic datasets. Extensive experiments demonstrate the effectiveness of our method through both quantitative and qualitative comparisons with state-of-the-art approaches.
An LMM for Efficient Video Understanding via Reinforced Compression of Video Cubes
Apr 21, 2025



Large Multimodal Models (LMMs) uniformly perceive video frames, creating computational inefficiency for videos with inherently varying temporal information density. This paper present \textbf{Quicksviewer}, an LMM with new perceiving paradigm that partitions a video of nonuniform density into varying cubes using Gumbel Softmax, followed by a unified resampling for each cube to achieve efficient video understanding. This simple and intuitive approach dynamically compress video online based on its temporal density, significantly reducing spatiotemporal redundancy (overall 45$\times$ compression rate), while enabling efficient training with large receptive field. We train the model from a language backbone through three progressive stages, each incorporating lengthy videos on average of 420s/1fps thanks to the perceiving efficiency. With only 0.8M total video-text samples for training, our model outperforms the direct baseline employing a fixed partitioning strategy by a maximum of 8.72 in accuracy, demonstrating the effectiveness in performance. On Video-MME, Quicksviewer achieves SOTA under modest sequence lengths using just up to 5\% of tokens per frame required by baselines. With this paradigm, scaling up the number of input frames reveals a clear power law of the model capabilities. It is also empirically verified that the segments generated by the cubing network can help for analyzing continuous events in videos.
MM-STFlowNet: A Transportation Hub-Oriented Multi-Mode Passenger Flow Prediction Method via Spatial-Temporal Dynamic Graph Modeling
Apr 08, 2025Accurate and refined passenger flow prediction is essential for optimizing the collaborative management of multiple collection and distribution modes in large-scale transportation hubs. Traditional methods often focus only on the overall passenger volume, neglecting the interdependence between different modes within the hub. To address this limitation, we propose MM-STFlowNet, a comprehensive multi-mode prediction framework grounded in dynamic spatial-temporal graph modeling. Initially, an integrated temporal feature processing strategy is implemented using signal decomposition and convolution techniques to address data spikes and high volatility. Subsequently, we introduce the Spatial-Temporal Dynamic Graph Convolutional Recurrent Network (STDGCRN) to capture detailed spatial-temporal dependencies across multiple traffic modes, enhanced by an adaptive channel attention mechanism. Finally, the self-attention mechanism is applied to incorporate various external factors, further enhancing prediction accuracy. Experiments on a real-world dataset from Guangzhounan Railway Station in China demonstrate that MM-STFlowNet achieves state-of-the-art performance, particularly during peak periods, providing valuable insight for transportation hub management.
LLM$\times$MapReduce-V2: Entropy-Driven Convolutional Test-Time Scaling for Generating Long-Form Articles from Extremely Long Resources
Apr 08, 2025Long-form generation is crucial for a wide range of practical applications, typically categorized into short-to-long and long-to-long generation. While short-to-long generations have received considerable attention, generating long texts from extremely long resources remains relatively underexplored. The primary challenge in long-to-long generation lies in effectively integrating and analyzing relevant information from extensive inputs, which remains difficult for current large language models (LLMs). In this paper, we propose LLM$\times$MapReduce-V2, a novel test-time scaling strategy designed to enhance the ability of LLMs to process extremely long inputs. Drawing inspiration from convolutional neural networks, which iteratively integrate local features into higher-level global representations, LLM$\times$MapReduce-V2 utilizes stacked convolutional scaling layers to progressively expand the understanding of input materials. Both quantitative and qualitative experimental results demonstrate that our approach substantially enhances the ability of LLMs to process long inputs and generate coherent, informative long-form articles, outperforming several representative baselines.
AIR: A Systematic Analysis of Annotations, Instructions, and Response Pairs in Preference Dataset
Apr 04, 2025



Preference learning is critical for aligning large language models (LLMs) with human values, yet its success hinges on high-quality datasets comprising three core components: Preference \textbf{A}nnotations, \textbf{I}nstructions, and \textbf{R}esponse Pairs. Current approaches conflate these components, obscuring their individual impacts and hindering systematic optimization. In this work, we propose \textbf{AIR}, a component-wise analysis framework that systematically isolates and optimizes each component while evaluating their synergistic effects. Through rigorous experimentation, AIR reveals actionable principles: annotation simplicity (point-wise generative scoring), instruction inference stability (variance-based filtering across LLMs), and response pair quality (moderate margins + high absolute scores). When combined, these principles yield +5.3 average gains over baseline method, even with only 14k high-quality pairs. Our work shifts preference dataset design from ad hoc scaling to component-aware optimization, offering a blueprint for efficient, reproducible alignment.
XLRS-Bench: Could Your Multimodal LLMs Understand Extremely Large Ultra-High-Resolution Remote Sensing Imagery?
Mar 31, 2025The astonishing breakthrough of multimodal large language models (MLLMs) has necessitated new benchmarks to quantitatively assess their capabilities, reveal their limitations, and indicate future research directions. However, this is challenging in the context of remote sensing (RS), since the imagery features ultra-high resolution that incorporates extremely complex semantic relationships. Existing benchmarks usually adopt notably smaller image sizes than real-world RS scenarios, suffer from limited annotation quality, and consider insufficient dimensions of evaluation. To address these issues, we present XLRS-Bench: a comprehensive benchmark for evaluating the perception and reasoning capabilities of MLLMs in ultra-high-resolution RS scenarios. XLRS-Bench boasts the largest average image size (8500$\times$8500) observed thus far, with all evaluation samples meticulously annotated manually, assisted by a novel semi-automatic captioner on ultra-high-resolution RS images. On top of the XLRS-Bench, 16 sub-tasks are defined to evaluate MLLMs' 10 kinds of perceptual capabilities and 6 kinds of reasoning capabilities, with a primary emphasis on advanced cognitive processes that facilitate real-world decision-making and the capture of spatiotemporal changes. The results of both general and RS-focused MLLMs on XLRS-Bench indicate that further efforts are needed for real-world RS applications. We have open-sourced XLRS-Bench to support further research in developing more powerful MLLMs for remote sensing.