 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforce to Learn, Elect to Reason: A Dual Paradigm for Video Reasoning
Apr 06, 2026Video reasoning has advanced with large multimodal models (LMMs), yet their inference is often a single pass that returns an answer without verifying whether the reasoning is evidence-aligned. We introduce Reinforce to Learn, Elect to Reason (RLER), a dual paradigm that decouples learning to produce evidence from obtaining a reliable answer. In RLER-Training, we optimize the policy with group-relative reinforcement learning (RL) and 3 novel task-driven rewards: Frame-sensitive reward grounds reasoning on explicit key frames, Think-transparency reward shapes readable and parsable reasoning traces, and Anti-repetition reward boosts information density. These signals teach the model to emit structured, machine-checkable evidence and potentiate reasoning capabilities. In RLER-Inference, we apply a train-free orchestrator that generates a small set of diverse candidates, parses their answers and cited frames, scores them by evidence consistency, confidence, transparency, and non-redundancy, and then performs a robust evidence-weighted election. This closes the loop between producing and using evidence, improving reliability and interpretability without enlarging the model. We comprehensively evaluate RLER against various open-source and RL-based LMMs on 8 representative benchmarks. RLER achieves state of the art across all benchmarks and delivers an average improvement of 6.3\% over base models, while using on average 3.1 candidates per question, indicating a favorable balance between compute and quality. The results support a simple thesis: making evidence explicit during learning and electing by evidence during inference is a robust path to trustworthy video reasoning.
Graph-to-Frame RAG: Visual-Space Knowledge Fusion for Training-Free and Auditable Video Reasoning
Apr 06, 2026When video reasoning requires external knowledge, many systems with large multimodal models (LMMs) adopt retrieval augmentation to supply the missing context. Appending textual or multi-clip evidence, however, forces heterogeneous signals into a single attention space. We observe diluted attention and higher cognitive load even on non-long videos. The bottleneck is not only what to retrieve but how to represent and fuse external knowledge with the video backbone.We present Graph-to-Frame RAG (G2F-RAG), a training free and auditable paradigm that delivers knowledge in the visual space. On the offline stage, an agent builds a problem-agnostic video knowledge graph that integrates entities, events, spatial relations, and linked world knowledge. On the online stage, a hierarchical multi-agent controller decides whether external knowledge is needed, retrieves a minimal sufficient subgraph, and renders it as a single reasoning frame appended to the video. LMMs then perform joint reasoning in a unified visual domain. This design reduces cognitive load and leaves an explicit, inspectable evidence trail.G2F-RAG is plug-and-play across backbones and scales. It yields consistent gains on diverse public benchmarks, with larger improvements in knowledge-intensive settings. Ablations further confirm that knowledge representation and delivery matter. G2F-RAG reframes retrieval as visual space knowledge fusion for robust and interpretable video reasoning.
AnyUser: Translating Sketched User Intent into Domestic Robots
Apr 06, 2026We introduce AnyUser, a unified robotic instruction system for intuitive domestic task instruction via free-form sketches on camera images, optionally with language. AnyUser interprets multimodal inputs (sketch, vision, language) as spatial-semantic primitives to generate executable robot actions requiring no prior maps or models. Novel components include multimodal fusion for understanding and a hierarchical policy for robust action generation. Efficacy is shown via extensive evaluations: (1) Quantitative benchmarks on the large-scale dataset showing high accuracy in interpreting diverse sketch-based commands across various simulated domestic scenes. (2) Real-world validation on two distinct robotic platforms, a statically mounted 7-DoF assistive arm (KUKA LBR iiwa) and a dual-arm mobile manipulator (Realman RMC-AIDAL), performing representative tasks like targeted wiping and area cleaning, confirming the system's ability to ground instructions and execute them reliably in physical environments. (3) A comprehensive user study involving diverse demographics (elderly, simulated non-verbal, low technical literacy) demonstrating significant improvements in usability and task specification efficiency, achieving high task completion rates (85.7%-96.4%) and user satisfaction. AnyUser bridges the gap between advanced robotic capabilities and the need for accessible non-expert interaction, laying the foundation for practical assistive robots adaptable to real-world human environments.
Detecting Unobserved Confounders: A Kernelized Regression Approach
Jan 01, 2026Detecting unobserved confounders is crucial for reliable causal inference in observational studies. Existing methods require either linearity assumptions or multiple heterogeneous environments, limiting applicability to nonlinear single-environment settings. To bridge this gap, we propose Kernel Regression Confounder Detection (KRCD), a novel method for detecting unobserved confounding in nonlinear observational data under single-environment conditions. KRCD leverages reproducing kernel Hilbert spaces to model complex dependencies. By comparing standard and higherorder kernel regressions, we derive a test statistic whose significant deviation from zero indicates unobserved confounding. Theoretically, we prove two key results: First, in infinite samples, regression coefficients coincide if and only if no unobserved confounders exist. Second, finite-sample differences converge to zero-mean Gaussian distributions with tractable variance. Extensive experiments on synthetic benchmarks and the Twins dataset demonstrate that KRCD not only outperforms existing baselines but also achieves superior computational efficiency.
BeyondFacial: Identity-Preserving Personalized Generation Beyond Facial Close-ups
Nov 15, 2025



Identity-Preserving Personalized Generation (IPPG) has advanced film production and artistic creation, yet existing approaches overemphasize facial regions, resulting in outputs dominated by facial close-ups.These methods suffer from weak visual narrativity and poor semantic consistency under complex text prompts, with the core limitation rooted in identity (ID) feature embeddings undermining the semantic expressiveness of generative models. To address these issues, this paper presents an IPPG method that breaks the constraint of facial close-ups, achieving synergistic optimization of identity fidelity and scene semantic creation. Specifically, we design a Dual-Line Inference (DLI) pipeline with identity-semantic separation, resolving the representation conflict between ID and semantics inherent in traditional single-path architectures. Further, we propose an Identity Adaptive Fusion (IdAF) strategy that defers ID-semantic fusion to the noise prediction stage, integrating adaptive attention fusion and noise decision masking to avoid ID embedding interference on semantics without manual masking. Finally, an Identity Aggregation Prepending (IdAP) module is introduced to aggregate ID information and replace random initializations, further enhancing identity preservation. Experimental results validate that our method achieves stable and effective performance in IPPG tasks beyond facial close-ups, enabling efficient generation without manual masking or fine-tuning. As a plug-and-play component, it can be rapidly deployed in existing IPPG frameworks, addressing the over-reliance on facial close-ups, facilitating film-level character-scene creation, and providing richer personalized generation capabilities for related domains.
Breaking the Gradient Barrier: Unveiling Large Language Models for Strategic Classification
Nov 10, 2025Strategic classification~(SC) explores how individuals or entities modify their features strategically to achieve favorable classification outcomes. However, existing SC methods, which are largely based on linear models or shallow neural networks, face significant limitations in terms of scalability and capacity when applied to real-world datasets with significantly increasing scale, especially in financial services and the internet sector. In this paper, we investigate how to leverage large language models to design a more scalable and efficient SC framework, especially in the case of growing individuals engaged with decision-making processes. Specifically, we introduce GLIM, a gradient-free SC method grounded in in-context learning. During the feed-forward process of self-attention, GLIM implicitly simulates the typical bi-level optimization process of SC, including both the feature manipulation and decision rule optimization. Without fine-tuning the LLMs, our proposed GLIM enjoys the advantage of cost-effective adaptation in dynamic strategic environments. Theoretically, we prove GLIM can support pre-trained LLMs to adapt to a broad range of strategic manipulations. We validate our approach through experiments with a collection of pre-trained LLMs on real-world and synthetic datasets in financial and internet domains, demonstrating that our GLIM exhibits both robustness and efficiency, and offering an effective solution for large-scale SC tasks.
ClusterUCB: Efficient Gradient-Based Data Selection for Targeted Fine-Tuning of LLMs
Jun 12, 2025Gradient-based data influence approximation has been leveraged to select useful data samples in the supervised fine-tuning of large language models. However, the computation of gradients throughout the fine-tuning process requires too many resources to be feasible in practice. In this paper, we propose an efficient gradient-based data selection framework with clustering and a modified Upper Confidence Bound (UCB) algorithm. Based on the intuition that data samples with similar gradient features will have similar influences, we first perform clustering on the training data pool. Then, we frame the inter-cluster data selection as a constrained computing budget allocation problem and consider it a multi-armed bandit problem. A modified UCB algorithm is leveraged to solve this problem. Specifically, during the iterative sampling process, historical data influence information is recorded to directly estimate the distributions of each cluster, and a cold start is adopted to balance exploration and exploitation. Experimental results on various benchmarks show that our proposed framework, ClusterUCB, can achieve comparable results to the original gradient-based data selection methods while greatly reducing computing consumption.
OmniEarth-Bench: Towards Holistic Evaluation of Earth's Six Spheres and Cross-Spheres Interactions with Multimodal Observational Earth Data
May 29, 2025Existing benchmarks for Earth science multimodal learning exhibit critical limitations in systematic coverage of geosystem components and cross-sphere interactions, often constrained to isolated subsystems (only in Human-activities sphere or atmosphere) with limited evaluation dimensions (less than 16 tasks). To address these gaps, we introduce OmniEarth-Bench, the first comprehensive multimodal benchmark spanning all six Earth science spheres (atmosphere, lithosphere, Oceansphere, cryosphere, biosphere and Human-activities sphere) and cross-spheres with one hundred expert-curated evaluation dimensions. Leveraging observational data from satellite sensors and in-situ measurements, OmniEarth-Bench integrates 29,779 annotations across four tiers: perception, general reasoning, scientific knowledge reasoning and chain-of-thought (CoT) reasoning. This involves the efforts of 2-5 experts per sphere to establish authoritative evaluation dimensions and curate relevant observational datasets, 40 crowd-sourcing annotators to assist experts for annotations, and finally, OmniEarth-Bench is validated via hybrid expert-crowd workflows to reduce label ambiguity. Experiments on 9 state-of-the-art MLLMs reveal that even the most advanced models struggle with our benchmarks, where none of them reach 35\% accuracy. Especially, in some cross-spheres tasks, the performance of leading models like GPT-4o drops to 0.0\%. OmniEarth-Bench sets a new standard for geosystem-aware AI, advancing both scientific discovery and practical applications in environmental monitoring and disaster prediction. The dataset, source code, and trained models were released.
MME-VideoOCR: Evaluating OCR-Based Capabilities of Multimodal LLMs in Video Scenarios
May 27, 2025Multimodal Large Language Models (MLLMs) have achieved considerable accuracy in Optical Character Recognition (OCR) from static images. However, their efficacy in video OCR is significantly diminished due to factors such as motion blur, temporal variations, and visual effects inherent in video content. To provide clearer guidance for training practical MLLMs, we introduce the MME-VideoOCR benchmark, which encompasses a comprehensive range of video OCR application scenarios. MME-VideoOCR features 10 task categories comprising 25 individual tasks and spans 44 diverse scenarios. These tasks extend beyond text recognition to incorporate deeper comprehension and reasoning of textual content within videos. The benchmark consists of 1,464 videos with varying resolutions, aspect ratios, and durations, along with 2,000 meticulously curated, manually annotated question-answer pairs. We evaluate 18 state-of-the-art MLLMs on MME-VideoOCR, revealing that even the best-performing model (Gemini-2.5 Pro) achieves an accuracy of only 73.7%. Fine-grained analysis indicates that while existing MLLMs demonstrate strong performance on tasks where relevant texts are contained within a single or few frames, they exhibit limited capability in effectively handling tasks that demand holistic video comprehension. These limitations are especially evident in scenarios that require spatio-temporal reasoning, cross-frame information integration, or resistance to language prior bias. Our findings also highlight the importance of high-resolution visual input and sufficient temporal coverage for reliable OCR in dynamic video scenarios.
GeoLLaVA-8K: Scaling Remote-Sensing Multimodal Large Language Models to 8K Resolution
May 27, 2025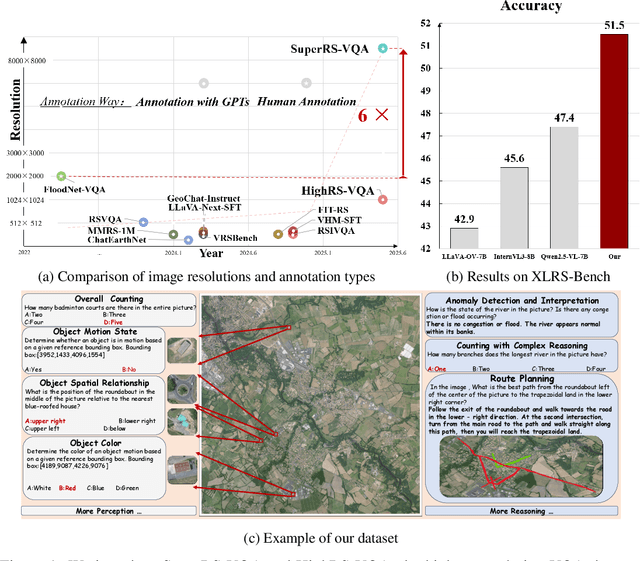

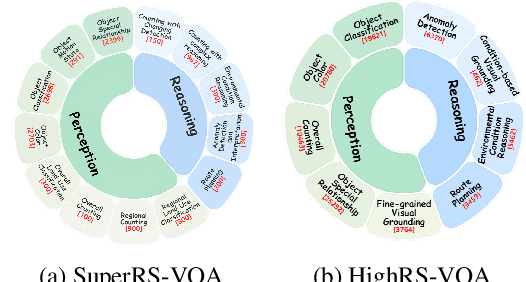

Ultra-high-resolution (UHR) remote sensing (RS) imagery offers valuable data for Earth observation but pose challenges for existing multimodal foundation models due to two key bottlenecks: (1) limited availability of UHR training data, and (2) token explosion caused by the large image size. To address data scarcity, we introduce SuperRS-VQA (avg. 8,376$\times$8,376) and HighRS-VQA (avg. 2,000$\times$1,912), the highest-resolution vision-language datasets in RS to date, covering 22 real-world dialogue tasks. To mitigate token explosion, our pilot studies reveal significant redundancy in RS images: crucial information is concentrated in a small subset of object-centric tokens, while pruning background tokens (e.g., ocean or forest) can even improve performance. Motivated by these findings, we propose two strategies: Background Token Pruning and Anchored Token Selection, to reduce the memory footprint while preserving key semantics.Integrating these techniques, we introduce GeoLLaVA-8K, the first RS-focused multimodal large language model capable of handling inputs up to 8K$\times$8K resolution, built on the LLaVA framework. Trained on SuperRS-VQA and HighRS-VQA, GeoLLaVA-8K sets a new state-of-the-art on the XLRS-Bench.