 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMA-ProofBench: A Two-Tiered Evaluation of LLMs for Theorem Proving in Mathematical Analysis
Jun 11, 2026Large Language Models (LLMs) have made notable progress in automated theorem proving, yet existing formal benchmarks remain limited in both mathematical coverage and difficulty. Most are concentrated in areas that are easier to formalize, such as algebra and elementary number theory, and provide limited coverage of subfields that require deeper reasoning, including mathematical analysis. To address this gap, we introduce MA-ProofBench, to the best of our knowledge, the first formal theorem-proving benchmark dedicated to Mathematical Analysis. The benchmark contains 200 formalized theorems covering 6 core topics and 27 subcategories, including measure and integration theory, complex analysis, and functional analysis. The problems are divided into two difficulty levels, an undergraduate level (Level I, 100 problems) and a Ph.D. qualifying level (Level II, 100 problems), to evaluate how well LLMs perform formal reasoning at different mathematical depths. Each problem is constructed through a human-led, LLM-assisted formalization pipeline followed by independent expert review, ensuring that the formal statements remain faithful to the original mathematics. We evaluate a range of recent general-purpose reasoning models and formal theorem provers on MA-ProofBench. However, most models perform poorly: even the best-performing model, GPT-5.5, achieves only 16% Pass@8 on Level I and 5% on Level II, while most models stay close to 0% on Level II. Further analysis identifies Mathlib hallucinations and incomplete proofs as the two dominant failure modes, while an evaluation on the natural-language version of the benchmark exposes a clear gap between informal and formal reasoning. MA-ProofBench is intended to serve as a reliable reference for tracking progress in formal mathematical reasoning in advanced domains.
Frames2Residual: Spatiotemporal Decoupling for Self-Supervised Video Denoising
Mar 11, 2026Self-supervised video denoising methods typically extend image-based frameworks into the temporal dimension, yet they often struggle to integrate inter-frame temporal consistency with intra-frame spatial specificity. Existing Video Blind-Spot Networks (BSNs) require noise independence by masking the center pixel, this constraint prevents the use of spatial evidence for texture recovery, thereby severing spatiotemporal correlations and causing texture loss. To address this, we propose Frames2Residual (F2R), a spatiotemporal decoupling framework that explicitly divides self-supervised training into two distinct stages: blind temporal consistency modeling and non-blind spatial texture recovery. In Stage 1, a blind temporal estimator learns inter-frame consistency using a frame-wise blind strategy, producing a temporally consistent anchor. In Stage 2, a non-blind spatial refiner leverages this anchor to safely reintroduce the center frame and recover intra-frame high-frequency spatial residuals while preserving temporal stability. Extensive experiments demonstrate that our decoupling strategy allows F2R to outperform existing self-supervised methods on both sRGB and raw video benchmarks.
How Far Can Unsupervised RLVR Scale LLM Training?
Mar 09, 2026Unsupervised reinforcement learning with verifiable rewards (URLVR) offers a pathway to scale LLM training beyond the supervision bottleneck by deriving rewards without ground truth labels. Recent works leverage model intrinsic signals, showing promising early gains, yet their potential and limitations remain unclear. In this work, we revisit URLVR and provide a comprehensive analysis spanning taxonomy, theory and extensive experiments. We first classify URLVR methods into intrinsic versus external based on reward sources, then establish a unified theoretical framework revealing that all intrinsic methods converge toward sharpening the model's initial distribution This sharpening mechanism succeeds when initial confidence aligns with correctness but fails catastrophically when misaligned. Through systematic experiments, we show intrinsic rewards consistently follow a rise-then-fall pattern across methods, with collapse timing determined by model prior rather than engineering choices. Despite these scaling limits, we find intrinsic rewards remain valuable in test-time training on small datasets, and propose Model Collapse Step to measure model prior, serving as a practical indicator for RL trainability. Finally, we explore external reward methods that ground verification in computational asymmetries, showing preliminary evidence they may escape the confidence-correctness ceiling. Our findings chart boundaries for intrinsic URLVR while motivating paths toward scalable alternatives.
Data Science and Technology Towards AGI Part I: Tiered Data Management
Feb 09, 2026The development of artificial intelligence can be viewed as an evolution of data-driven learning paradigms, with successive shifts in data organization and utilization continuously driving advances in model capability. Current LLM research is dominated by a paradigm that relies heavily on unidirectional scaling of data size, increasingly encountering bottlenecks in data availability, acquisition cost, and training efficiency. In this work, we argue that the development of AGI is entering a new phase of data-model co-evolution, in which models actively guide data management while high-quality data, in turn, amplifies model capabilities. To implement this vision, we propose a tiered data management framework, designed to support the full LLM training lifecycle across heterogeneous learning objectives and cost constraints. Specifically, we introduce an L0-L4 tiered data management framework, ranging from raw uncurated resources to organized and verifiable knowledge. Importantly, LLMs are fully used in data management processes, such as quality scoring and content editing, to refine data across tiers. Each tier is characterized by distinct data properties, management strategies, and training roles, enabling data to be strategically allocated across LLM training stages, including pre-training, mid-training, and alignment. The framework balances data quality, acquisition cost, and marginal training benefit, providing a systematic approach to scalable and sustainable data management. We validate the effectiveness of the proposed framework through empirical studies, in which tiered datasets are constructed from raw corpora and used across multiple training phases. Experimental results demonstrate that tier-aware data utilization significantly improves training efficiency and model performance. To facilitate further research, we release our tiered datasets and processing tools to the community.
CPMobius: Iterative Coach-Player Reasoning for Data-Free Reinforcement Learning
Feb 03, 2026Large Language Models (LLMs) have demonstrated strong potential in complex reasoning, yet their progress remains fundamentally constrained by reliance on massive high-quality human-curated tasks and labels, either through supervised fine-tuning (SFT) or reinforcement learning (RL) on reasoning-specific data. This dependence renders supervision-heavy training paradigms increasingly unsustainable, with signs of diminishing scalability already evident in practice. To overcome this limitation, we introduce CPMöbius (CPMobius), a collaborative Coach-Player paradigm for data-free reinforcement learning of reasoning models. Unlike traditional adversarial self-play, CPMöbius, inspired by real world human sports collaboration and multi-agent collaboration, treats the Coach and Player as independent but cooperative roles. The Coach proposes instructions targeted at the Player's capability and receives rewards based on changes in the Player's performance, while the Player is rewarded for solving the increasingly instructive tasks generated by the Coach. This cooperative optimization loop is designed to directly enhance the Player's mathematical reasoning ability. Remarkably, CPMöbius achieves substantial improvement without relying on any external training data, outperforming existing unsupervised approaches. For example, on Qwen2.5-Math-7B-Instruct, our method improves accuracy by an overall average of +4.9 and an out-of-distribution average of +5.4, exceeding RENT by +1.5 on overall accuracy and R-zero by +4.2 on OOD accuracy.
Improving Flexible Image Tokenizers for Autoregressive Image Generation
Jan 04, 2026Flexible image tokenizers aim to represent an image using an ordered 1D variable-length token sequence. This flexible tokenization is typically achieved through nested dropout, where a portion of trailing tokens is randomly truncated during training, and the image is reconstructed using the remaining preceding sequence. However, this tail-truncation strategy inherently concentrates the image information in the early tokens, limiting the effectiveness of downstream AutoRegressive (AR) image generation as the token length increases. To overcome these limitations, we propose \textbf{ReToK}, a flexible tokenizer with \underline{Re}dundant \underline{Tok}en Padding and Hierarchical Semantic Regularization, designed to fully exploit all tokens for enhanced latent modeling. Specifically, we introduce \textbf{Redundant Token Padding} to activate tail tokens more frequently, thereby alleviating information over-concentration in the early tokens. In addition, we apply \textbf{Hierarchical Semantic Regularization} to align the decoding features of earlier tokens with those from a pre-trained vision foundation model, while progressively reducing the regularization strength toward the tail to allow finer low-level detail reconstruction. Extensive experiments demonstrate the effectiveness of ReTok: on ImageNet 256$\times$256, our method achieves superior generation performance compared with both flexible and fixed-length tokenizers. Code will be available at: \href{https://github.com/zfu006/ReTok}{https://github.com/zfu006/ReTok}
FADE: Adversarial Concept Erasure in Flow Models
Jul 16, 2025

Diffusion models have demonstrated remarkable image generation capabilities, but also pose risks in privacy and fairness by memorizing sensitive concepts or perpetuating biases. We propose a novel \textbf{concept erasure} method for text-to-image diffusion models, designed to remove specified concepts (e.g., a private individual or a harmful stereotype) from the model's generative repertoire. Our method, termed \textbf{FADE} (Fair Adversarial Diffusion Erasure), combines a trajectory-aware fine-tuning strategy with an adversarial objective to ensure the concept is reliably removed while preserving overall model fidelity. Theoretically, we prove a formal guarantee that our approach minimizes the mutual information between the erased concept and the model's outputs, ensuring privacy and fairness. Empirically, we evaluate FADE on Stable Diffusion and FLUX, using benchmarks from prior work (e.g., object, celebrity, explicit content, and style erasure tasks from MACE). FADE achieves state-of-the-art concept removal performance, surpassing recent baselines like ESD, UCE, MACE, and ANT in terms of removal efficacy and image quality. Notably, FADE improves the harmonic mean of concept removal and fidelity by 5--10\% over the best prior method. We also conduct an ablation study to validate each component of FADE, confirming that our adversarial and trajectory-preserving objectives each contribute to its superior performance. Our work sets a new standard for safe and fair generative modeling by unlearning specified concepts without retraining from scratch.
MiniCPM4: Ultra-Efficient LLMs on End Devices
Jun 09, 2025



This paper introduces MiniCPM4, a highly efficient large language model (LLM) designed explicitly for end-side devices. We achieve this efficiency through systematic innovation in four key dimensions: model architecture, training data, training algorithms, and inference systems. Specifically, in terms of model architecture, we propose InfLLM v2, a trainable sparse attention mechanism that accelerates both prefilling and decoding phases for long-context processing. Regarding training data, we propose UltraClean, an efficient and accurate pre-training data filtering and generation strategy, and UltraChat v2, a comprehensive supervised fine-tuning dataset. These datasets enable satisfactory model performance to be achieved using just 8 trillion training tokens. Regarding training algorithms, we propose ModelTunnel v2 for efficient pre-training strategy search, and improve existing post-training methods by introducing chunk-wise rollout for load-balanced reinforcement learning and data-efficient tenary LLM, BitCPM. Regarding inference systems, we propose CPM.cu that integrates sparse attention, model quantization, and speculative sampling to achieve efficient prefilling and decoding. To meet diverse on-device requirements, MiniCPM4 is available in two versions, with 0.5B and 8B parameters, respectively. Sufficient evaluation results show that MiniCPM4 outperforms open-source models of similar size across multiple benchmarks, highlighting both its efficiency and effectiveness. Notably, MiniCPM4-8B demonstrates significant speed improvements over Qwen3-8B when processing long sequences. Through further adaptation, MiniCPM4 successfully powers diverse applications, including trustworthy survey generation and tool use with model context protocol, clearly showcasing its broad usability.
Ultra-FineWeb: Efficient Data Filtering and Verification for High-Quality LLM Training Data
May 08, 2025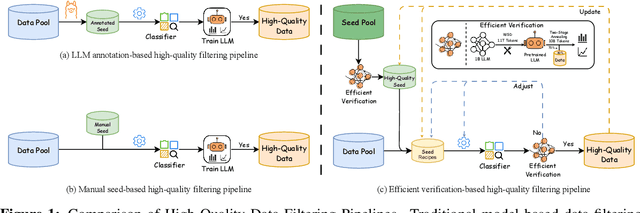



Data quality has become a key factor in enhancing model performance with the rapid development of large language models (LLMs). Model-driven data filtering has increasingly become a primary approach for acquiring high-quality data. However, it still faces two main challenges: (1) the lack of an efficient data verification strategy makes it difficult to provide timely feedback on data quality; and (2) the selection of seed data for training classifiers lacks clear criteria and relies heavily on human expertise, introducing a degree of subjectivity. To address the first challenge, we introduce an efficient verification strategy that enables rapid evaluation of the impact of data on LLM training with minimal computational cost. To tackle the second challenge, we build upon the assumption that high-quality seed data is beneficial for LLM training, and by integrating the proposed verification strategy, we optimize the selection of positive and negative samples and propose an efficient data filtering pipeline. This pipeline not only improves filtering efficiency, classifier quality, and robustness, but also significantly reduces experimental and inference costs. In addition, to efficiently filter high-quality data, we employ a lightweight classifier based on fastText, and successfully apply the filtering pipeline to two widely-used pre-training corpora, FineWeb and Chinese FineWeb datasets, resulting in the creation of the higher-quality Ultra-FineWeb dataset. Ultra-FineWeb contains approximately 1 trillion English tokens and 120 billion Chinese tokens. Empirical results demonstrate that the LLMs trained on Ultra-FineWeb exhibit significant performance improvements across multiple benchmark tasks, validating the effectiveness of our pipeline in enhancing both data quality and training efficiency.
AIR: A Systematic Analysis of Annotations, Instructions, and Response Pairs in Preference Dataset
Apr 04, 2025



Preference learning is critical for aligning large language models (LLMs) with human values, yet its success hinges on high-quality datasets comprising three core components: Preference \textbf{A}nnotations, \textbf{I}nstructions, and \textbf{R}esponse Pairs. Current approaches conflate these components, obscuring their individual impacts and hindering systematic optimization. In this work, we propose \textbf{AIR}, a component-wise analysis framework that systematically isolates and optimizes each component while evaluating their synergistic effects. Through rigorous experimentation, AIR reveals actionable principles: annotation simplicity (point-wise generative scoring), instruction inference stability (variance-based filtering across LLMs), and response pair quality (moderate margins + high absolute scores). When combined, these principles yield +5.3 average gains over baseline method, even with only 14k high-quality pairs. Our work shifts preference dataset design from ad hoc scaling to component-aware optimization, offering a blueprint for efficient, reproducible alignment.