 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind to Hand: Purposeful Robotic Control via Embodied Reasoning
Dec 10, 2025Humans act with context and intention, with reasoning playing a central role. While internet-scale data has enabled broad reasoning capabilities in AI systems, grounding these abilities in physical action remains a major challenge. We introduce Lumo-1, a generalist vision-language-action (VLA) model that unifies robot reasoning ("mind") with robot action ("hand"). Our approach builds upon the general multi-modal reasoning capabilities of pre-trained vision-language models (VLMs), progressively extending them to embodied reasoning and action prediction, and ultimately towards structured reasoning and reasoning-action alignment. This results in a three-stage pre-training pipeline: (1) Continued VLM pre-training on curated vision-language data to enhance embodied reasoning skills such as planning, spatial understanding, and trajectory prediction; (2) Co-training on cross-embodiment robot data alongside vision-language data; and (3) Action training with reasoning process on trajectories collected on Astribot S1, a bimanual mobile manipulator with human-like dexterity and agility. Finally, we integrate reinforcement learning to further refine reasoning-action consistency and close the loop between semantic inference and motor control. Extensive experiments demonstrate that Lumo-1 achieves significant performance improvements in embodied vision-language reasoning, a critical component for generalist robotic control. Real-world evaluations further show that Lumo-1 surpasses strong baselines across a wide range of challenging robotic tasks, with strong generalization to novel objects and environments, excelling particularly in long-horizon tasks and responding to human-natural instructions that require reasoning over strategy, concepts and space.
MiniCPM4: Ultra-Efficient LLMs on End Devices
Jun 09, 2025



This paper introduces MiniCPM4, a highly efficient large language model (LLM) designed explicitly for end-side devices. We achieve this efficiency through systematic innovation in four key dimensions: model architecture, training data, training algorithms, and inference systems. Specifically, in terms of model architecture, we propose InfLLM v2, a trainable sparse attention mechanism that accelerates both prefilling and decoding phases for long-context processing. Regarding training data, we propose UltraClean, an efficient and accurate pre-training data filtering and generation strategy, and UltraChat v2, a comprehensive supervised fine-tuning dataset. These datasets enable satisfactory model performance to be achieved using just 8 trillion training tokens. Regarding training algorithms, we propose ModelTunnel v2 for efficient pre-training strategy search, and improve existing post-training methods by introducing chunk-wise rollout for load-balanced reinforcement learning and data-efficient tenary LLM, BitCPM. Regarding inference systems, we propose CPM.cu that integrates sparse attention, model quantization, and speculative sampling to achieve efficient prefilling and decoding. To meet diverse on-device requirements, MiniCPM4 is available in two versions, with 0.5B and 8B parameters, respectively. Sufficient evaluation results show that MiniCPM4 outperforms open-source models of similar size across multiple benchmarks, highlighting both its efficiency and effectiveness. Notably, MiniCPM4-8B demonstrates significant speed improvements over Qwen3-8B when processing long sequences. Through further adaptation, MiniCPM4 successfully powers diverse applications, including trustworthy survey generation and tool use with model context protocol, clearly showcasing its broad usability.
Ultra-FineWeb: Efficient Data Filtering and Verification for High-Quality LLM Training Data
May 08, 2025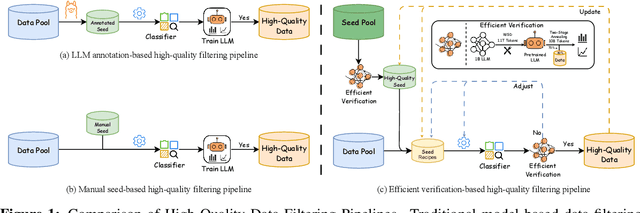



Data quality has become a key factor in enhancing model performance with the rapid development of large language models (LLMs). Model-driven data filtering has increasingly become a primary approach for acquiring high-quality data. However, it still faces two main challenges: (1) the lack of an efficient data verification strategy makes it difficult to provide timely feedback on data quality; and (2) the selection of seed data for training classifiers lacks clear criteria and relies heavily on human expertise, introducing a degree of subjectivity. To address the first challenge, we introduce an efficient verification strategy that enables rapid evaluation of the impact of data on LLM training with minimal computational cost. To tackle the second challenge, we build upon the assumption that high-quality seed data is beneficial for LLM training, and by integrating the proposed verification strategy, we optimize the selection of positive and negative samples and propose an efficient data filtering pipeline. This pipeline not only improves filtering efficiency, classifier quality, and robustness, but also significantly reduces experimental and inference costs. In addition, to efficiently filter high-quality data, we employ a lightweight classifier based on fastText, and successfully apply the filtering pipeline to two widely-used pre-training corpora, FineWeb and Chinese FineWeb datasets, resulting in the creation of the higher-quality Ultra-FineWeb dataset. Ultra-FineWeb contains approximately 1 trillion English tokens and 120 billion Chinese tokens. Empirical results demonstrate that the LLMs trained on Ultra-FineWeb exhibit significant performance improvements across multiple benchmark tasks, validating the effectiveness of our pipeline in enhancing both data quality and training efficiency.
Grounding DINO 1.5: Advance the "Edge" of Open-Set Object Detection
May 16, 2024



This paper introduces Grounding DINO 1.5, a suite of advanced open-set object detection models developed by IDEA Research, which aims to advance the "Edge" of open-set object detection. The suite encompasses two models: Grounding DINO 1.5 Pro, a high-performance model designed for stronger generalization capability across a wide range of scenarios, and Grounding DINO 1.5 Edge, an efficient model optimized for faster speed demanded in many applications requiring edge deployment. The Grounding DINO 1.5 Pro model advances its predecessor by scaling up the model architecture, integrating an enhanced vision backbone, and expanding the training dataset to over 20 million images with grounding annotations, thereby achieving a richer semantic understanding. The Grounding DINO 1.5 Edge model, while designed for efficiency with reduced feature scales, maintains robust detection capabilities by being trained on the same comprehensive dataset. Empirical results demonstrate the effectiveness of Grounding DINO 1.5, with the Grounding DINO 1.5 Pro model attaining a 54.3 AP on the COCO detection benchmark and a 55.7 AP on the LVIS-minival zero-shot transfer benchmark, setting new records for open-set object detection. Furthermore, the Grounding DINO 1.5 Edge model, when optimized with TensorRT, achieves a speed of 75.2 FPS while attaining a zero-shot performance of 36.2 AP on the LVIS-minival benchmark, making it more suitable for edge computing scenarios. Model examples and demos with API will be released at https://github.com/IDEA-Research/Grounding-DINO-1.5-API
AcademicGPT: Empowering Academic Research
Nov 21, 2023



Large Language Models (LLMs) have demonstrated exceptional capabilities across various natural language processing tasks. Yet, many of these advanced LLMs are tailored for broad, general-purpose applications. In this technical report, we introduce AcademicGPT, designed specifically to empower academic research. AcademicGPT is a continual training model derived from LLaMA2-70B. Our training corpus mainly consists of academic papers, thesis, content from some academic domain, high-quality Chinese data and others. While it may not be extensive in data scale, AcademicGPT marks our initial venture into a domain-specific GPT tailored for research area. We evaluate AcademicGPT on several established public benchmarks such as MMLU and CEval, as well as on some specialized academic benchmarks like PubMedQA, SCIEval, and our newly-created ComputerScienceQA, to demonstrate its ability from general knowledge ability, to Chinese ability, and to academic ability. Building upon AcademicGPT's foundation model, we also developed several applications catered to the academic area, including General Academic Question Answering, AI-assisted Paper Reading, Paper Review, and AI-assisted Title and Abstract Generation.
Unsupervised domain adaptation via coarse-to-fine feature alignment method using contrastive learning
Mar 23, 2021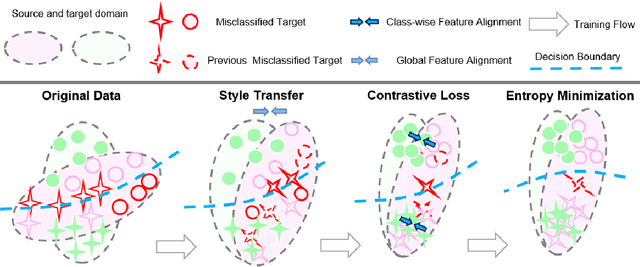

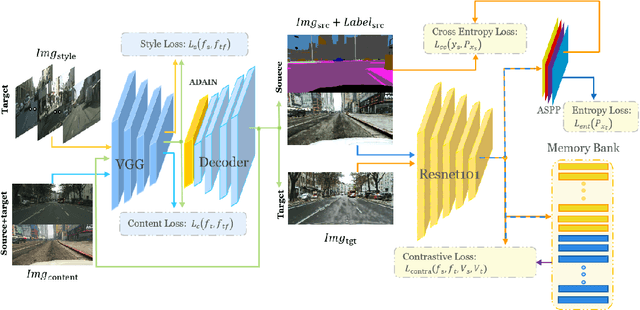

Previous feature alignment methods in Unsupervised domain adaptation(UDA) mostly only align global features without considering the mismatch between class-wise features. In this work, we propose a new coarse-to-fine feature alignment method using contrastive learning called CFContra. It draws class-wise features closer than coarse feature alignment or class-wise feature alignment only, therefore improves the model's performance to a great extent. We build it upon one of the most effective methods of UDA called entropy minimization to further improve performance. In particular, to prevent excessive memory occupation when applying contrastive loss in semantic segmentation, we devise a new way to build and update the memory bank. In this way, we make the algorithm more efficient and viable with limited memory. Extensive experiments show the effectiveness of our method and model trained on the GTA5 to Cityscapes dataset has boost mIOU by 3.5 compared to the MinEnt algorithm. Our code will be publicly available.
Contrastive Disentanglement in Generative Adversarial Networks
Mar 05, 2021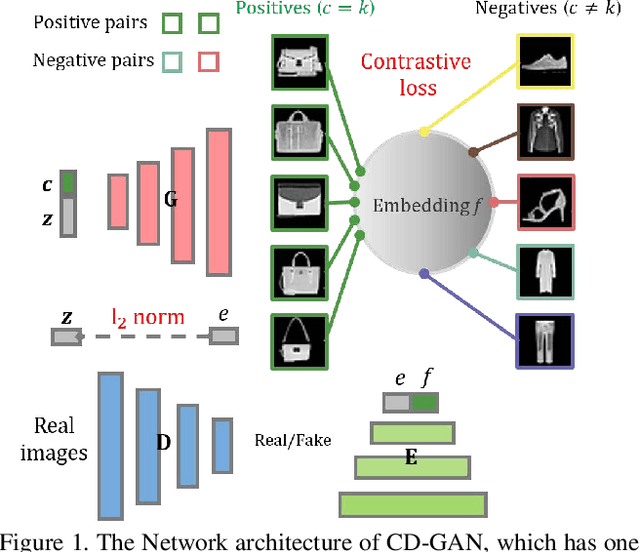
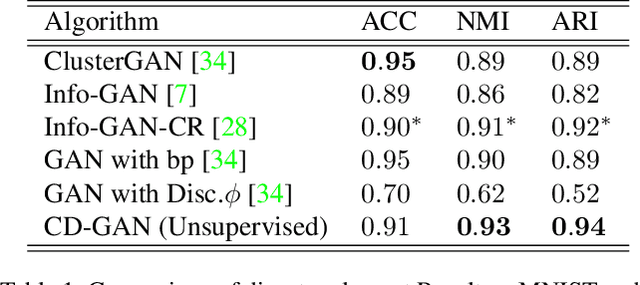

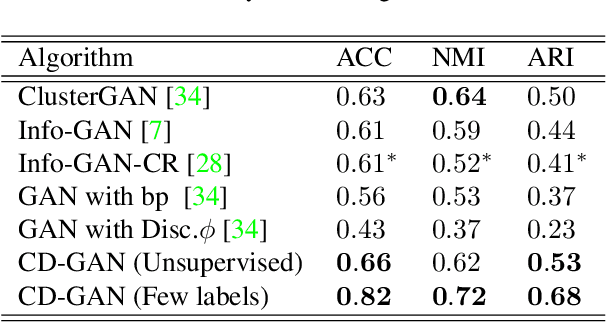
Disentanglement is defined as the problem of learninga representation that can separate the distinct, informativefactors of variations of data. Learning such a representa-tion may be critical for developing explainable and human-controllable Deep Generative Models (DGMs) in artificialintelligence. However, disentanglement in GANs is not a triv-ial task, as the absence of sample likelihood and posteriorinference for latent variables seems to prohibit the forwardstep. Inspired by contrastive learning (CL), this paper, froma new perspective, proposes contrastive disentanglement ingenerative adversarial networks (CD-GAN). It aims at dis-entangling the factors of inter-class variation of visual datathrough contrasting image features, since the same factorvalues produce images in the same class. More importantly,we probe a novel way to make use of limited amount ofsupervision to the largest extent, to promote inter-class dis-entanglement performance. Extensive experimental resultson many well-known datasets demonstrate the efficacy ofCD-GAN for disentangling inter-class variation.