 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFreeSpec: Training-Free Long Video Generation via Singular-Spectrum Reconstruction
May 07, 2026Video diffusion models perform well in short-video synthesis, but their training-free extension to long videos often suffers from content drift, temporal inconsistency, and over-smoothed dynamics. Existing methods improve temporal consistency by combining a global branch with a local branch, but they often further decompose appearance consistency and temporal dynamics within each branch using predefined criteria. This assignment is unreliable when appearance and action progression are tightly coupled, such as in camera motion and sequential motion. We analyze the video temporal extension issue from a singular-spectrum perspective and show that enlarged self-attention windows induce spectral concentration: spectral energy becomes dominated by a few low-rank singular directions, preserving coarse structure but suppressing high-rank spatial details and motion-rich temporal variations. To mitigate this problem, we propose FreeSpec, a training-free spectral reconstruction framework for long-video generation. FreeSpec decomposes global and local features with singular value decomposition, and uses the global branch as low-rank spectral guidance and the local branch as a high-rank reconstruction basis. This spectrum-level fusion avoids the rigid feature partitioning of previous decomposition rules, preserving long-range consistency while better retaining spatial details and temporal dynamics. Experiments on Wan2.1 and LTX-Video demonstrate that FreeSpec improves long-video generation, especially for temporal dynamics, while maintaining strong visual quality and temporal consistency. Project demo: https://fdchen24.github.io/FreeSpec-Website/.
Semantic-Geometric Dual Compression: Training-Free Visual Token Reduction for Ultra-High-Resolution Remote Sensing Understanding
Apr 13, 2026Multimodal Large Language Models (MLLMs) have demonstrated immense potential in Earth observation. However, the massive visual tokens generated when processing Ultra-High-Resolution (UHR) imagery introduce prohibitive computational overhead, severely bottlenecking their inference efficiency. Existing visual token compression methods predominantly adopt static and uniform compression strategies, neglecting the inherent "Semantic-Geometric Duality" in remote sensing interpretation tasks. Specifically, object semantic tasks focus on the abstract semantics of objects and benefit from aggressive background pruning, whereas scene geometric tasks critically rely on the integrity of spatial topology. To address this challenge, we propose DualComp, a task-adaptive dual-stream token compression framework. Dynamically guided by a lightweight pre-trained router, DualComp decouples feature processing into two dedicated pathways. In the object semantic stream, the Spatially-Contiguous Semantic Aggregator (SCSA) utilizes size-adaptive clustering to aggregates redundant background while protecting small object. In the scene geometric stream, the Instruction-Guided Structure Recoverer (IGSR) introduces a greedy path-tracing topology completion mechanism to reconstruct spatial skeletons. Experiments on the UHR remote sensing benchmark XLRS-Bench demonstrate that DualComp accomplishes high-fidelity remote sensing interpretation at an exceptionally low computational cost, achieving simultaneous improvements in both efficiency and accuracy.
GeoEyes: On-Demand Visual Focusing for Evidence-Grounded Understanding of Ultra-High-Resolution Remote Sensing Imagery
Feb 15, 2026The "thinking-with-images" paradigm enables multimodal large language models (MLLMs) to actively explore visual scenes via zoom-in tools. This is essential for ultra-high-resolution (UHR) remote sensing VQA, where task-relevant cues are sparse and tiny. However, we observe a consistent failure mode in existing zoom-enabled MLLMs: Tool Usage Homogenization, where tool calls collapse into task-agnostic patterns, limiting effective evidence acquisition. To address this, we propose GeoEyes, a staged training framework consisting of (1) a cold-start SFT dataset, UHR Chain-of-Zoom (UHR-CoZ), which covers diverse zooming regimes, and (2) an agentic reinforcement learning method, AdaZoom-GRPO, that explicitly rewards evidence gain and answer improvement during zoom interactions. The resulting model learns on-demand zooming with proper stopping behavior and achieves substantial improvements on UHR remote sensing benchmarks, with 54.23% accuracy on XLRS-Bench.
Text Before Vision: Staged Knowledge Injection Matters for Agentic RLVR in Ultra-High-Resolution Remote Sensing Understanding
Feb 15, 2026Multimodal reasoning for ultra-high-resolution (UHR) remote sensing (RS) is usually bottlenecked by visual evidence acquisition: the model necessitates localizing tiny task-relevant regions in massive pixel spaces. While Agentic Reinforcement Learning with Verifiable Rewards (RLVR) using zoom-in tools offers a path forward, we find that standard reinforcement learning struggles to navigate these vast visual spaces without structured domain priors. In this paper, we investigate the interplay between post-training paradigms: comparing Cold-start Supervised Fine-Tuning (SFT), RLVR, and Agentic RLVR on the UHR RS benchmark.Our controlled studies yield a counter-intuitive finding: high-quality Earth-science text-only QA is a primary driver of UHR visual reasoning gains. Despite lacking images, domain-specific text injects the concepts, mechanistic explanations, and decision rules necessary to guide visual evidence retrieval.Based on this, we propose a staged knowledge injection recipe: (1) cold-starting with scalable, knowledge-graph-verified Earth-science text QA to instill reasoning structures;and (2) "pre-warming" on the same hard UHR image-text examples during SFT to stabilize and amplify subsequent tool-based RL. This approach achieves a 60.40% Pass@1 on XLRS-Bench, significantly outperforming larger general purpose models (e.g., GPT-5.2, Gemini 3.0 Pro, Intern-S1) and establishing a new state-of-the-art.
FOUND: Fourier-based von Mises Distribution for Robust Single Domain Generalization in Object Detection
Nov 13, 2025Single Domain Generalization (SDG) for object detection aims to train a model on a single source domain that can generalize effectively to unseen target domains. While recent methods like CLIP-based semantic augmentation have shown promise, they often overlook the underlying structure of feature distributions and frequency-domain characteristics that are critical for robustness. In this paper, we propose a novel framework that enhances SDG object detection by integrating the von Mises-Fisher (vMF) distribution and Fourier transformation into a CLIP-guided pipeline. Specifically, we model the directional features of object representations using vMF to better capture domain-invariant semantic structures in the embedding space. Additionally, we introduce a Fourier-based augmentation strategy that perturbs amplitude and phase components to simulate domain shifts in the frequency domain, further improving feature robustness. Our method not only preserves the semantic alignment benefits of CLIP but also enriches feature diversity and structural consistency across domains. Extensive experiments on the diverse weather-driving benchmark demonstrate that our approach outperforms the existing state-of-the-art method.
Breaking the Gradient Barrier: Unveiling Large Language Models for Strategic Classification
Nov 10, 2025Strategic classification~(SC) explores how individuals or entities modify their features strategically to achieve favorable classification outcomes. However, existing SC methods, which are largely based on linear models or shallow neural networks, face significant limitations in terms of scalability and capacity when applied to real-world datasets with significantly increasing scale, especially in financial services and the internet sector. In this paper, we investigate how to leverage large language models to design a more scalable and efficient SC framework, especially in the case of growing individuals engaged with decision-making processes. Specifically, we introduce GLIM, a gradient-free SC method grounded in in-context learning. During the feed-forward process of self-attention, GLIM implicitly simulates the typical bi-level optimization process of SC, including both the feature manipulation and decision rule optimization. Without fine-tuning the LLMs, our proposed GLIM enjoys the advantage of cost-effective adaptation in dynamic strategic environments. Theoretically, we prove GLIM can support pre-trained LLMs to adapt to a broad range of strategic manipulations. We validate our approach through experiments with a collection of pre-trained LLMs on real-world and synthetic datasets in financial and internet domains, demonstrating that our GLIM exhibits both robustness and efficiency, and offering an effective solution for large-scale SC tasks.
OmniEarth-Bench: Towards Holistic Evaluation of Earth's Six Spheres and Cross-Spheres Interactions with Multimodal Observational Earth Data
May 29, 2025Existing benchmarks for Earth science multimodal learning exhibit critical limitations in systematic coverage of geosystem components and cross-sphere interactions, often constrained to isolated subsystems (only in Human-activities sphere or atmosphere) with limited evaluation dimensions (less than 16 tasks). To address these gaps, we introduce OmniEarth-Bench, the first comprehensive multimodal benchmark spanning all six Earth science spheres (atmosphere, lithosphere, Oceansphere, cryosphere, biosphere and Human-activities sphere) and cross-spheres with one hundred expert-curated evaluation dimensions. Leveraging observational data from satellite sensors and in-situ measurements, OmniEarth-Bench integrates 29,779 annotations across four tiers: perception, general reasoning, scientific knowledge reasoning and chain-of-thought (CoT) reasoning. This involves the efforts of 2-5 experts per sphere to establish authoritative evaluation dimensions and curate relevant observational datasets, 40 crowd-sourcing annotators to assist experts for annotations, and finally, OmniEarth-Bench is validated via hybrid expert-crowd workflows to reduce label ambiguity. Experiments on 9 state-of-the-art MLLMs reveal that even the most advanced models struggle with our benchmarks, where none of them reach 35\% accuracy. Especially, in some cross-spheres tasks, the performance of leading models like GPT-4o drops to 0.0\%. OmniEarth-Bench sets a new standard for geosystem-aware AI, advancing both scientific discovery and practical applications in environmental monitoring and disaster prediction. The dataset, source code, and trained models were released.
GeoLLaVA-8K: Scaling Remote-Sensing Multimodal Large Language Models to 8K Resolution
May 27, 2025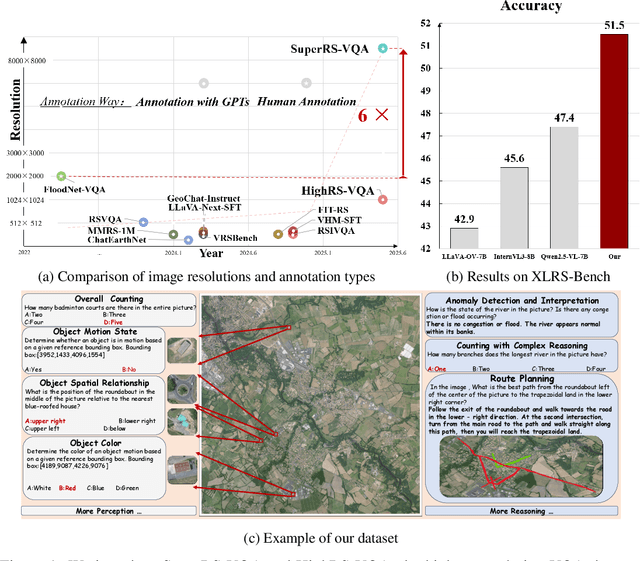

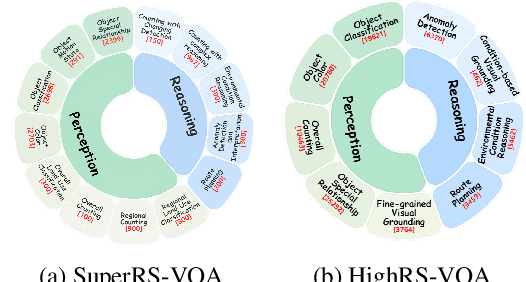

Ultra-high-resolution (UHR) remote sensing (RS) imagery offers valuable data for Earth observation but pose challenges for existing multimodal foundation models due to two key bottlenecks: (1) limited availability of UHR training data, and (2) token explosion caused by the large image size. To address data scarcity, we introduce SuperRS-VQA (avg. 8,376$\times$8,376) and HighRS-VQA (avg. 2,000$\times$1,912), the highest-resolution vision-language datasets in RS to date, covering 22 real-world dialogue tasks. To mitigate token explosion, our pilot studies reveal significant redundancy in RS images: crucial information is concentrated in a small subset of object-centric tokens, while pruning background tokens (e.g., ocean or forest) can even improve performance. Motivated by these findings, we propose two strategies: Background Token Pruning and Anchored Token Selection, to reduce the memory footprint while preserving key semantics.Integrating these techniques, we introduce GeoLLaVA-8K, the first RS-focused multimodal large language model capable of handling inputs up to 8K$\times$8K resolution, built on the LLaVA framework. Trained on SuperRS-VQA and HighRS-VQA, GeoLLaVA-8K sets a new state-of-the-art on the XLRS-Bench.
TransMedSeg: A Transferable Semantic Framework for Semi-Supervised Medical Image Segmentation
May 20, 2025Semi-supervised learning (SSL) has achieved significant progress in medical image segmentation (SSMIS) through effective utilization of limited labeled data. While current SSL methods for medical images predominantly rely on consistency regularization and pseudo-labeling, they often overlook transferable semantic relationships across different clinical domains and imaging modalities. To address this, we propose TransMedSeg, a novel transferable semantic framework for semi-supervised medical image segmentation. Our approach introduces a Transferable Semantic Augmentation (TSA) module, which implicitly enhances feature representations by aligning domain-invariant semantics through cross-domain distribution matching and intra-domain structural preservation. Specifically, TransMedSeg constructs a unified feature space where teacher network features are adaptively augmented towards student network semantics via a lightweight memory module, enabling implicit semantic transformation without explicit data generation. Interestingly, this augmentation is implicitly realized through an expected transferable cross-entropy loss computed over the augmented teacher distribution. An upper bound of the expected loss is theoretically derived and minimized during training, incurring negligible computational overhead. Extensive experiments on medical image datasets demonstrate that TransMedSeg outperforms existing semi-supervised methods, establishing a new direction for transferable representation learning in medical image analysis.
Towards Efficient Partially Relevant Video Retrieval with Active Moment Discovering
Apr 15, 2025



Partially relevant video retrieval (PRVR) is a practical yet challenging task in text-to-video retrieval, where videos are untrimmed and contain much background content. The pursuit here is of both effective and efficient solutions to capture the partial correspondence between text queries and untrimmed videos. Existing PRVR methods, which typically focus on modeling multi-scale clip representations, however, suffer from content independence and information redundancy, impairing retrieval performance. To overcome these limitations, we propose a simple yet effective approach with active moment discovering (AMDNet). We are committed to discovering video moments that are semantically consistent with their queries. By using learnable span anchors to capture distinct moments and applying masked multi-moment attention to emphasize salient moments while suppressing redundant backgrounds, we achieve more compact and informative video representations. To further enhance moment modeling, we introduce a moment diversity loss to encourage different moments of distinct regions and a moment relevance loss to promote semantically query-relevant moments, which cooperate with a partially relevant retrieval loss for end-to-end optimization. Extensive experiments on two large-scale video datasets (\ie, TVR and ActivityNet Captions) demonstrate the superiority and efficiency of our AMDNet. In particular, AMDNet is about 15.5 times smaller (\#parameters) while 6.0 points higher (SumR) than the up-to-date method GMMFormer on TVR.