 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiniCPM-SALA: Hybridizing Sparse and Linear Attention for Efficient Long-Context Modeling
Feb 12, 2026The evolution of large language models (LLMs) towards applications with ultra-long contexts faces challenges posed by the high computational and memory costs of the Transformer architecture. While existing sparse and linear attention mechanisms attempt to mitigate these issues, they typically involve a trade-off between memory efficiency and model performance. This paper introduces MiniCPM-SALA, a 9B-parameter hybrid architecture that integrates the high-fidelity long-context modeling of sparse attention (InfLLM-V2) with the global efficiency of linear attention (Lightning Attention). By employing a layer selection algorithm to integrate these mechanisms in a 1:3 ratio and utilizing a hybrid positional encoding (HyPE), the model maintains efficiency and performance for long-context tasks. Furthermore, we introduce a cost-effective continual training framework that transforms pre-trained Transformer-based models into hybrid models, which reduces training costs by approximately 75% compared to training from scratch. Extensive experiments show that MiniCPM-SALA maintains general capabilities comparable to full-attention models while offering improved efficiency. On a single NVIDIA A6000D GPU, the model achieves up to 3.5x the inference speed of the full-attention model at the sequence length of 256K tokens and supports context lengths of up to 1M tokens, a scale where traditional full-attention 8B models fail because of memory constraints.
AgentCPM-Report: Interleaving Drafting and Deepening for Open-Ended Deep Research
Feb 06, 2026Generating deep research reports requires large-scale information acquisition and the synthesis of insight-driven analysis, posing a significant challenge for current language models. Most existing approaches follow a plan-then-write paradigm, whose performance heavily depends on the quality of the initial outline. However, constructing a comprehensive outline itself demands strong reasoning ability, causing current deep research systems to rely almost exclusively on closed-source or online large models. This reliance raises practical barriers to deployment and introduces safety and privacy concerns for user-authored data. In this work, we present AgentCPM-Report, a lightweight yet high-performing local solution composed of a framework that mirrors the human writing process and an 8B-parameter deep research agent. Our framework uses a Writing As Reasoning Policy (WARP), which enables models to dynamically revise outlines during report generation. Under this policy, the agent alternates between Evidence-Based Drafting and Reasoning-Driven Deepening, jointly supporting information acquisition, knowledge refinement, and iterative outline evolution. To effectively equip small models with this capability, we introduce a Multi-Stage Agentic Training strategy, consisting of cold-start, atomic skill RL, and holistic pipeline RL. Experiments on DeepResearch Bench, DeepConsult, and DeepResearch Gym demonstrate that AgentCPM-Report outperforms leading closed-source systems, with substantial gains in Insight.
Monocle: Hybrid Local-Global In-Context Evaluation for Long-Text Generation with Uncertainty-Based Active Learning
May 27, 2025Assessing the quality of long-form, model-generated text is challenging, even with advanced LLM-as-a-Judge methods, due to performance degradation as input length increases. To address this issue, we propose a divide-and-conquer approach, which breaks down the comprehensive evaluation task into a series of localized scoring tasks, followed by a final global assessment. This strategy allows for more granular and manageable evaluations, ensuring that each segment of the text is assessed in isolation for both coherence and quality, while also accounting for the overall structure and consistency of the entire piece. Moreover, we introduce a hybrid in-context learning approach that leverages human annotations to enhance the performance of both local and global evaluations. By incorporating human-generated feedback directly into the evaluation process, this method allows the model to better align with human judgment. Finally, we develop an uncertainty-based active learning algorithm that efficiently selects data samples for human annotation, thereby reducing annotation costs in practical scenarios. Experimental results show that the proposed evaluation framework outperforms several representative baselines, highlighting the effectiveness of our approach.
LLM$\times$MapReduce-V2: Entropy-Driven Convolutional Test-Time Scaling for Generating Long-Form Articles from Extremely Long Resources
Apr 08, 2025Long-form generation is crucial for a wide range of practical applications, typically categorized into short-to-long and long-to-long generation. While short-to-long generations have received considerable attention, generating long texts from extremely long resources remains relatively underexplored. The primary challenge in long-to-long generation lies in effectively integrating and analyzing relevant information from extensive inputs, which remains difficult for current large language models (LLMs). In this paper, we propose LLM$\times$MapReduce-V2, a novel test-time scaling strategy designed to enhance the ability of LLMs to process extremely long inputs. Drawing inspiration from convolutional neural networks, which iteratively integrate local features into higher-level global representations, LLM$\times$MapReduce-V2 utilizes stacked convolutional scaling layers to progressively expand the understanding of input materials. Both quantitative and qualitative experimental results demonstrate that our approach substantially enhances the ability of LLMs to process long inputs and generate coherent, informative long-form articles, outperforming several representative baselines.
Energy and Carbon Considerations of Fine-Tuning BERT
Nov 17, 2023



Despite the popularity of the `pre-train then fine-tune' paradigm in the NLP community, existing work quantifying energy costs and associated carbon emissions has largely focused on language model pre-training. Although a single pre-training run draws substantially more energy than fine-tuning, fine-tuning is performed more frequently by many more individual actors, and thus must be accounted for when considering the energy and carbon footprint of NLP. In order to better characterize the role of fine-tuning in the landscape of energy and carbon emissions in NLP, we perform a careful empirical study of the computational costs of fine-tuning across tasks, datasets, hardware infrastructure and measurement modalities. Our experimental results allow us to place fine-tuning energy and carbon costs into perspective with respect to pre-training and inference, and outline recommendations to NLP researchers and practitioners who wish to improve their fine-tuning energy efficiency.
One Hyper-Initializer for All Network Architectures in Medical Image Analysis
Jun 08, 2022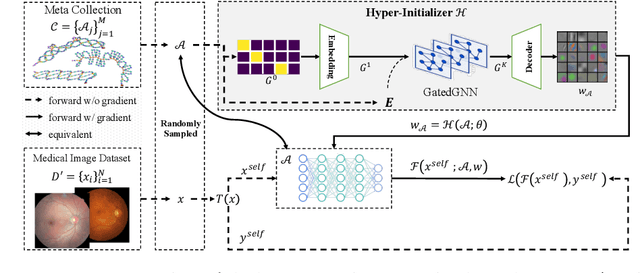
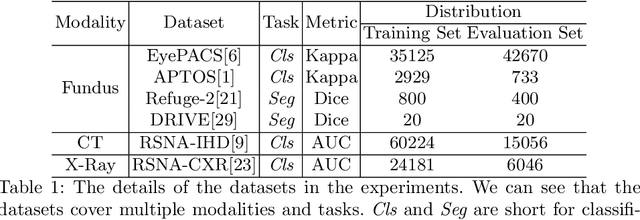
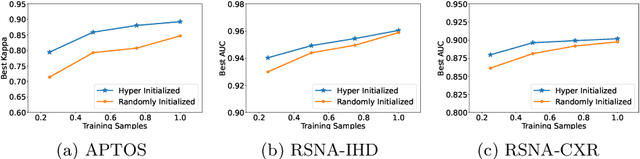
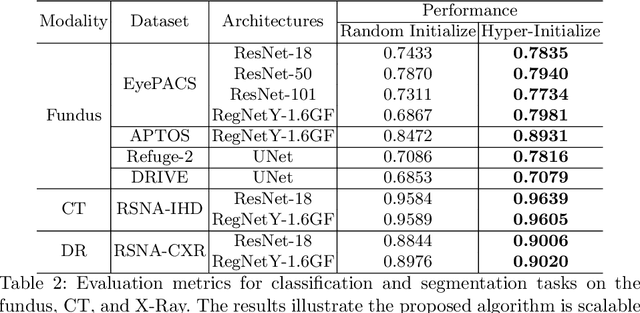
Pre-training is essential to deep learning model performance, especially in medical image analysis tasks where limited training data are available. However, existing pre-training methods are inflexible as the pre-trained weights of one model cannot be reused by other network architectures. In this paper, we propose an architecture-irrelevant hyper-initializer, which can initialize any given network architecture well after being pre-trained for only once. The proposed initializer is a hypernetwork which takes a downstream architecture as input graphs and outputs the initialization parameters of the respective architecture. We show the effectiveness and efficiency of the hyper-initializer through extensive experimental results on multiple medical imaging modalities, especially in data-limited fields. Moreover, we prove that the proposed algorithm can be reused as a favorable plug-and-play initializer for any downstream architecture and task (both classification and segmentation) of the same modality.
Contrastive Centroid Supervision Alleviates Domain Shift in Medical Image Classification
May 31, 2022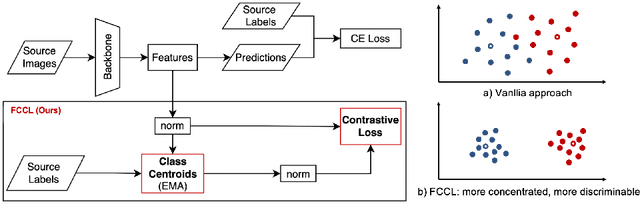
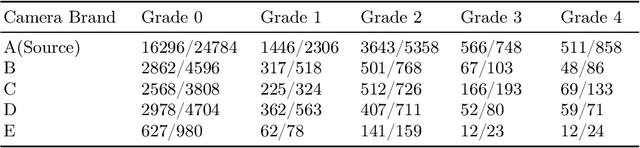


Deep learning based medical imaging classification models usually suffer from the domain shift problem, where the classification performance drops when training data and real-world data differ in imaging equipment manufacturer, image acquisition protocol, patient populations, etc. We propose Feature Centroid Contrast Learning (FCCL), which can improve target domain classification performance by extra supervision during training with contrastive loss between instance and class centroid. Compared with current unsupervised domain adaptation and domain generalization methods, FCCL performs better while only requires labeled image data from a single source domain and no target domain. We verify through extensive experiments that FCCL can achieve superior performance on at least three imaging modalities, i.e. fundus photographs, dermatoscopic images, and H & E tissue images.