 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMA-ProofBench: A Two-Tiered Evaluation of LLMs for Theorem Proving in Mathematical Analysis
Jun 11, 2026Large Language Models (LLMs) have made notable progress in automated theorem proving, yet existing formal benchmarks remain limited in both mathematical coverage and difficulty. Most are concentrated in areas that are easier to formalize, such as algebra and elementary number theory, and provide limited coverage of subfields that require deeper reasoning, including mathematical analysis. To address this gap, we introduce MA-ProofBench, to the best of our knowledge, the first formal theorem-proving benchmark dedicated to Mathematical Analysis. The benchmark contains 200 formalized theorems covering 6 core topics and 27 subcategories, including measure and integration theory, complex analysis, and functional analysis. The problems are divided into two difficulty levels, an undergraduate level (Level I, 100 problems) and a Ph.D. qualifying level (Level II, 100 problems), to evaluate how well LLMs perform formal reasoning at different mathematical depths. Each problem is constructed through a human-led, LLM-assisted formalization pipeline followed by independent expert review, ensuring that the formal statements remain faithful to the original mathematics. We evaluate a range of recent general-purpose reasoning models and formal theorem provers on MA-ProofBench. However, most models perform poorly: even the best-performing model, GPT-5.5, achieves only 16% Pass@8 on Level I and 5% on Level II, while most models stay close to 0% on Level II. Further analysis identifies Mathlib hallucinations and incomplete proofs as the two dominant failure modes, while an evaluation on the natural-language version of the benchmark exposes a clear gap between informal and formal reasoning. MA-ProofBench is intended to serve as a reliable reference for tracking progress in formal mathematical reasoning in advanced domains.
MiniCPM-SALA: Hybridizing Sparse and Linear Attention for Efficient Long-Context Modeling
Feb 12, 2026The evolution of large language models (LLMs) towards applications with ultra-long contexts faces challenges posed by the high computational and memory costs of the Transformer architecture. While existing sparse and linear attention mechanisms attempt to mitigate these issues, they typically involve a trade-off between memory efficiency and model performance. This paper introduces MiniCPM-SALA, a 9B-parameter hybrid architecture that integrates the high-fidelity long-context modeling of sparse attention (InfLLM-V2) with the global efficiency of linear attention (Lightning Attention). By employing a layer selection algorithm to integrate these mechanisms in a 1:3 ratio and utilizing a hybrid positional encoding (HyPE), the model maintains efficiency and performance for long-context tasks. Furthermore, we introduce a cost-effective continual training framework that transforms pre-trained Transformer-based models into hybrid models, which reduces training costs by approximately 75% compared to training from scratch. Extensive experiments show that MiniCPM-SALA maintains general capabilities comparable to full-attention models while offering improved efficiency. On a single NVIDIA A6000D GPU, the model achieves up to 3.5x the inference speed of the full-attention model at the sequence length of 256K tokens and supports context lengths of up to 1M tokens, a scale where traditional full-attention 8B models fail because of memory constraints.
Data Science and Technology Towards AGI Part I: Tiered Data Management
Feb 09, 2026The development of artificial intelligence can be viewed as an evolution of data-driven learning paradigms, with successive shifts in data organization and utilization continuously driving advances in model capability. Current LLM research is dominated by a paradigm that relies heavily on unidirectional scaling of data size, increasingly encountering bottlenecks in data availability, acquisition cost, and training efficiency. In this work, we argue that the development of AGI is entering a new phase of data-model co-evolution, in which models actively guide data management while high-quality data, in turn, amplifies model capabilities. To implement this vision, we propose a tiered data management framework, designed to support the full LLM training lifecycle across heterogeneous learning objectives and cost constraints. Specifically, we introduce an L0-L4 tiered data management framework, ranging from raw uncurated resources to organized and verifiable knowledge. Importantly, LLMs are fully used in data management processes, such as quality scoring and content editing, to refine data across tiers. Each tier is characterized by distinct data properties, management strategies, and training roles, enabling data to be strategically allocated across LLM training stages, including pre-training, mid-training, and alignment. The framework balances data quality, acquisition cost, and marginal training benefit, providing a systematic approach to scalable and sustainable data management. We validate the effectiveness of the proposed framework through empirical studies, in which tiered datasets are constructed from raw corpora and used across multiple training phases. Experimental results demonstrate that tier-aware data utilization significantly improves training efficiency and model performance. To facilitate further research, we release our tiered datasets and processing tools to the community.
MiniCPM4: Ultra-Efficient LLMs on End Devices
Jun 09, 2025



This paper introduces MiniCPM4, a highly efficient large language model (LLM) designed explicitly for end-side devices. We achieve this efficiency through systematic innovation in four key dimensions: model architecture, training data, training algorithms, and inference systems. Specifically, in terms of model architecture, we propose InfLLM v2, a trainable sparse attention mechanism that accelerates both prefilling and decoding phases for long-context processing. Regarding training data, we propose UltraClean, an efficient and accurate pre-training data filtering and generation strategy, and UltraChat v2, a comprehensive supervised fine-tuning dataset. These datasets enable satisfactory model performance to be achieved using just 8 trillion training tokens. Regarding training algorithms, we propose ModelTunnel v2 for efficient pre-training strategy search, and improve existing post-training methods by introducing chunk-wise rollout for load-balanced reinforcement learning and data-efficient tenary LLM, BitCPM. Regarding inference systems, we propose CPM.cu that integrates sparse attention, model quantization, and speculative sampling to achieve efficient prefilling and decoding. To meet diverse on-device requirements, MiniCPM4 is available in two versions, with 0.5B and 8B parameters, respectively. Sufficient evaluation results show that MiniCPM4 outperforms open-source models of similar size across multiple benchmarks, highlighting both its efficiency and effectiveness. Notably, MiniCPM4-8B demonstrates significant speed improvements over Qwen3-8B when processing long sequences. Through further adaptation, MiniCPM4 successfully powers diverse applications, including trustworthy survey generation and tool use with model context protocol, clearly showcasing its broad usability.
Ultra-FineWeb: Efficient Data Filtering and Verification for High-Quality LLM Training Data
May 08, 2025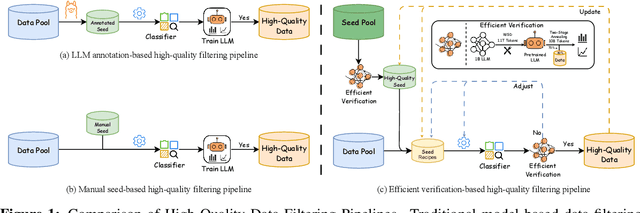



Data quality has become a key factor in enhancing model performance with the rapid development of large language models (LLMs). Model-driven data filtering has increasingly become a primary approach for acquiring high-quality data. However, it still faces two main challenges: (1) the lack of an efficient data verification strategy makes it difficult to provide timely feedback on data quality; and (2) the selection of seed data for training classifiers lacks clear criteria and relies heavily on human expertise, introducing a degree of subjectivity. To address the first challenge, we introduce an efficient verification strategy that enables rapid evaluation of the impact of data on LLM training with minimal computational cost. To tackle the second challenge, we build upon the assumption that high-quality seed data is beneficial for LLM training, and by integrating the proposed verification strategy, we optimize the selection of positive and negative samples and propose an efficient data filtering pipeline. This pipeline not only improves filtering efficiency, classifier quality, and robustness, but also significantly reduces experimental and inference costs. In addition, to efficiently filter high-quality data, we employ a lightweight classifier based on fastText, and successfully apply the filtering pipeline to two widely-used pre-training corpora, FineWeb and Chinese FineWeb datasets, resulting in the creation of the higher-quality Ultra-FineWeb dataset. Ultra-FineWeb contains approximately 1 trillion English tokens and 120 billion Chinese tokens. Empirical results demonstrate that the LLMs trained on Ultra-FineWeb exhibit significant performance improvements across multiple benchmark tasks, validating the effectiveness of our pipeline in enhancing both data quality and training efficiency.