 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSWE-Compass: Towards Unified Evaluation of Agentic Coding Abilities for Large Language Models
Nov 07, 2025Evaluating large language models (LLMs) for software engineering has been limited by narrow task coverage, language bias, and insufficient alignment with real-world developer workflows. Existing benchmarks often focus on algorithmic problems or Python-centric bug fixing, leaving critical dimensions of software engineering underexplored. To address these gaps, we introduce SWE-Compass1, a comprehensive benchmark that unifies heterogeneous code-related evaluations into a structured and production-aligned framework. SWE-Compass spans 8 task types, 8 programming scenarios, and 10 programming languages, with 2000 high-quality instances curated from authentic GitHub pull requests and refined through systematic filtering and validation. We benchmark ten state-of-the-art LLMs under two agentic frameworks, SWE-Agent and Claude Code, revealing a clear hierarchy of difficulty across task types, languages, and scenarios. Moreover, by aligning evaluation with real-world developer practices, SWE-Compass provides a rigorous and reproducible foundation for diagnosing and advancing agentic coding capabilities in large language models.
Grasp Any Region: Towards Precise, Contextual Pixel Understanding for Multimodal LLMs
Oct 22, 2025While Multimodal Large Language Models (MLLMs) excel at holistic understanding, they struggle in capturing the dense world with complex scenes, requiring fine-grained analysis of intricate details and object inter-relationships. Region-level MLLMs have been a promising step. However, previous attempts are generally optimized to understand given regions in isolation, neglecting crucial global contexts. To address this, we introduce Grasp Any Region (GAR) for comprehen- sive region-level visual understanding. Empowered by an effective RoI-aligned feature replay technique, GAR supports (1) precise perception by leveraging necessary global contexts, and (2) modeling interactions between multiple prompts. Together, it then naturally achieves (3) advanced compositional reasoning to answer specific free-form questions about any region, shifting the paradigm from passive description to active dialogue. Moreover, we construct GAR-Bench, which not only provides a more accurate evaluation of single-region comprehension, but also, more importantly, measures interactions and complex reasoning across multiple regions. Extensive experiments have demonstrated that GAR-1B not only maintains the state-of-the-art captioning capabilities, e.g., outperforming DAM-3B +4.5 on DLC-Bench, but also excels at modeling relationships between multiple prompts with advanced comprehension capabilities, even surpassing InternVL3-78B on GAR-Bench-VQA. More importantly, our zero-shot GAR-8B even outperforms in-domain VideoRefer-7B on VideoRefer-BenchQ, indicating its strong capabilities can be easily transferred to videos.
MCOP: Multi-UAV Collaborative Occupancy Prediction
Oct 14, 2025Unmanned Aerial Vehicle (UAV) swarm systems necessitate efficient collaborative perception mechanisms for diverse operational scenarios. Current Bird's Eye View (BEV)-based approaches exhibit two main limitations: bounding-box representations fail to capture complete semantic and geometric information of the scene, and their performance significantly degrades when encountering undefined or occluded objects. To address these limitations, we propose a novel multi-UAV collaborative occupancy prediction framework. Our framework effectively preserves 3D spatial structures and semantics through integrating a Spatial-Aware Feature Encoder and Cross-Agent Feature Integration. To enhance efficiency, we further introduce Altitude-Aware Feature Reduction to compactly represent scene information, along with a Dual-Mask Perceptual Guidance mechanism to adaptively select features and reduce communication overhead. Due to the absence of suitable benchmark datasets, we extend three datasets for evaluation: two virtual datasets (Air-to-Pred-Occ and UAV3D-Occ) and one real-world dataset (GauUScene-Occ). Experiments results demonstrate that our method achieves state-of-the-art accuracy, significantly outperforming existing collaborative methods while reducing communication overhead to only a fraction of previous approaches.
DriveVLA-W0: World Models Amplify Data Scaling Law in Autonomous Driving
Oct 14, 2025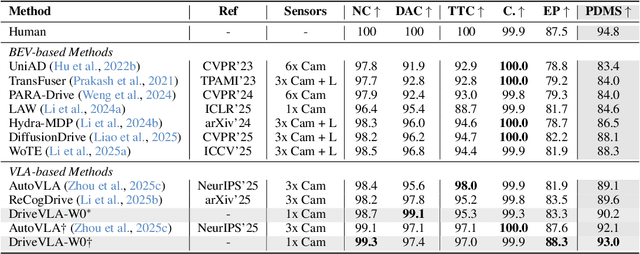
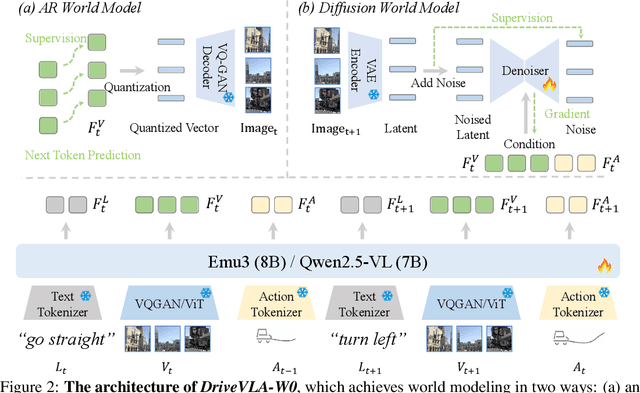

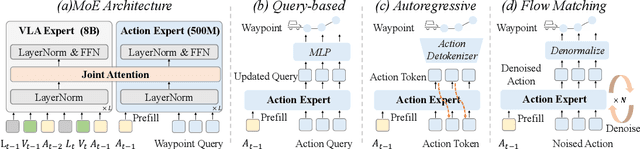
Scaling Vision-Language-Action (VLA) models on large-scale data offers a promising path to achieving a more generalized driving intelligence. However, VLA models are limited by a ``supervision deficit'': the vast model capacity is supervised by sparse, low-dimensional actions, leaving much of their representational power underutilized. To remedy this, we propose \textbf{DriveVLA-W0}, a training paradigm that employs world modeling to predict future images. This task generates a dense, self-supervised signal that compels the model to learn the underlying dynamics of the driving environment. We showcase the paradigm's versatility by instantiating it for two dominant VLA archetypes: an autoregressive world model for VLAs that use discrete visual tokens, and a diffusion world model for those operating on continuous visual features. Building on the rich representations learned from world modeling, we introduce a lightweight action expert to address the inference latency for real-time deployment. Extensive experiments on the NAVSIM v1/v2 benchmark and a 680x larger in-house dataset demonstrate that DriveVLA-W0 significantly outperforms BEV and VLA baselines. Crucially, it amplifies the data scaling law, showing that performance gains accelerate as the training dataset size increases.
SpatialVID: A Large-Scale Video Dataset with Spatial Annotations
Sep 11, 2025Significant progress has been made in spatial intelligence, spanning both spatial reconstruction and world exploration. However, the scalability and real-world fidelity of current models remain severely constrained by the scarcity of large-scale, high-quality training data. While several datasets provide camera pose information, they are typically limited in scale, diversity, and annotation richness, particularly for real-world dynamic scenes with ground-truth camera motion. To this end, we collect \textbf{SpatialVID}, a dataset consists of a large corpus of in-the-wild videos with diverse scenes, camera movements and dense 3D annotations such as per-frame camera poses, depth, and motion instructions. Specifically, we collect more than 21,000 hours of raw video, and process them into 2.7 million clips through a hierarchical filtering pipeline, totaling 7,089 hours of dynamic content. A subsequent annotation pipeline enriches these clips with detailed spatial and semantic information, including camera poses, depth maps, dynamic masks, structured captions, and serialized motion instructions. Analysis of SpatialVID's data statistics reveals a richness and diversity that directly foster improved model generalization and performance, establishing it as a key asset for the video and 3D vision research community.
HLG: Comprehensive 3D Room Construction via Hierarchical Layout Generation
Aug 25, 2025Realistic 3D indoor scene generation is crucial for virtual reality, interior design, embodied intelligence, and scene understanding. While existing methods have made progress in coarse-scale furniture arrangement, they struggle to capture fine-grained object placements, limiting the realism and utility of generated environments. This gap hinders immersive virtual experiences and detailed scene comprehension for embodied AI applications. To address these issues, we propose Hierarchical Layout Generation (HLG), a novel method for fine-grained 3D scene generation. HLG is the first to adopt a coarse-to-fine hierarchical approach, refining scene layouts from large-scale furniture placement to intricate object arrangements. Specifically, our fine-grained layout alignment module constructs a hierarchical layout through vertical and horizontal decoupling, effectively decomposing complex 3D indoor scenes into multiple levels of granularity. Additionally, our trainable layout optimization network addresses placement issues, such as incorrect positioning, orientation errors, and object intersections, ensuring structurally coherent and physically plausible scene generation. We demonstrate the effectiveness of our approach through extensive experiments, showing superior performance in generating realistic indoor scenes compared to existing methods. This work advances the field of scene generation and opens new possibilities for applications requiring detailed 3D environments. We will release our code upon publication to encourage future research.
Traceable Evidence Enhanced Visual Grounded Reasoning: Evaluation and Methodology
Jul 10, 2025

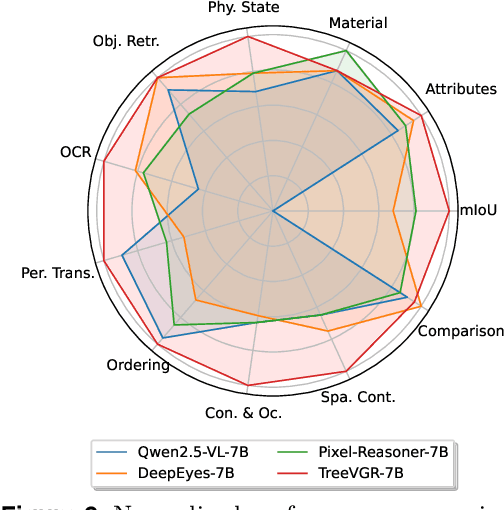

Models like OpenAI-o3 pioneer visual grounded reasoning by dynamically referencing visual regions, just like human "thinking with images". However, no benchmark exists to evaluate these capabilities holistically. To bridge this gap, we propose TreeBench (Traceable Evidence Evaluation Benchmark), a diagnostic benchmark built on three principles: (1) focused visual perception of subtle targets in complex scenes, (2) traceable evidence via bounding box evaluation, and (3) second-order reasoning to test object interactions and spatial hierarchies beyond simple object localization. Prioritizing images with dense objects, we initially sample 1K high-quality images from SA-1B, and incorporate eight LMM experts to manually annotate questions, candidate options, and answers for each image. After three stages of quality control, TreeBench consists of 405 challenging visual question-answering pairs, even the most advanced models struggle with this benchmark, where none of them reach 60% accuracy, e.g., OpenAI-o3 scores only 54.87. Furthermore, we introduce TreeVGR (Traceable Evidence Enhanced Visual Grounded Reasoning), a training paradigm to supervise localization and reasoning jointly with reinforcement learning, enabling accurate localizations and explainable reasoning pathways. Initialized from Qwen2.5-VL-7B, it improves V* Bench (+16.8), MME-RealWorld (+12.6), and TreeBench (+13.4), proving traceability is key to advancing vision-grounded reasoning. The code is available at https://github.com/Haochen-Wang409/TreeVGR.
A Survey on Latent Reasoning
Jul 08, 2025



Large Language Models (LLMs) have demonstrated impressive reasoning capabilities, especially when guided by explicit chain-of-thought (CoT) reasoning that verbalizes intermediate steps. While CoT improves both interpretability and accuracy, its dependence on natural language reasoning limits the model's expressive bandwidth. Latent reasoning tackles this bottleneck by performing multi-step inference entirely in the model's continuous hidden state, eliminating token-level supervision. To advance latent reasoning research, this survey provides a comprehensive overview of the emerging field of latent reasoning. We begin by examining the foundational role of neural network layers as the computational substrate for reasoning, highlighting how hierarchical representations support complex transformations. Next, we explore diverse latent reasoning methodologies, including activation-based recurrence, hidden state propagation, and fine-tuning strategies that compress or internalize explicit reasoning traces. Finally, we discuss advanced paradigms such as infinite-depth latent reasoning via masked diffusion models, which enable globally consistent and reversible reasoning processes. By unifying these perspectives, we aim to clarify the conceptual landscape of latent reasoning and chart future directions for research at the frontier of LLM cognition. An associated GitHub repository collecting the latest papers and repos is available at: https://github.com/multimodal-art-projection/LatentCoT-Horizon/.
CriticLean: Critic-Guided Reinforcement Learning for Mathematical Formalization
Jul 08, 2025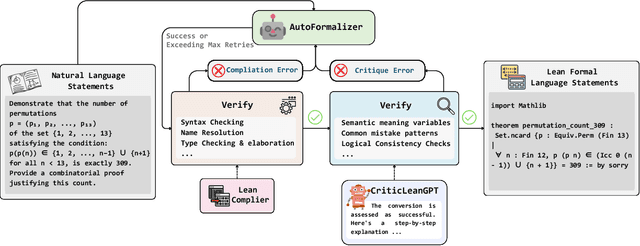

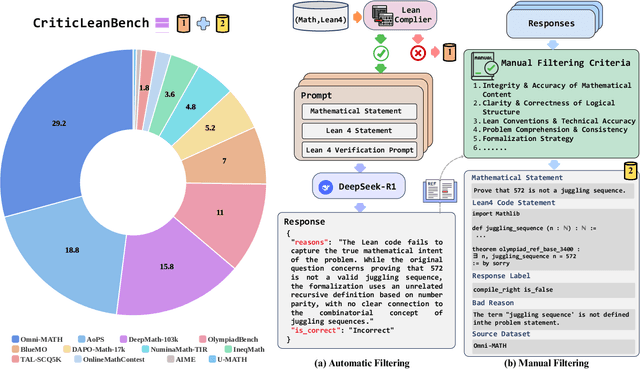
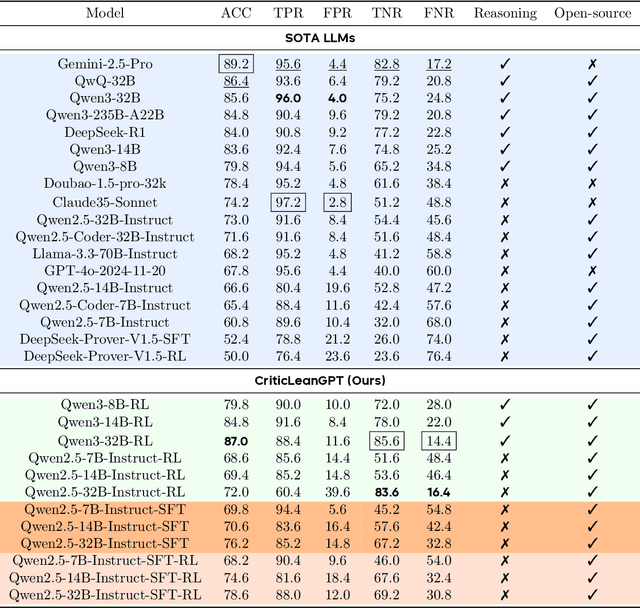
Translating natural language mathematical statements into formal, executable code is a fundamental challenge in automated theorem proving. While prior work has focused on generation and compilation success, little attention has been paid to the critic phase-the evaluation of whether generated formalizations truly capture the semantic intent of the original problem. In this paper, we introduce CriticLean, a novel critic-guided reinforcement learning framework that elevates the role of the critic from a passive validator to an active learning component. Specifically, first, we propose the CriticLeanGPT, trained via supervised fine-tuning and reinforcement learning, to rigorously assess the semantic fidelity of Lean 4 formalizations. Then, we introduce CriticLeanBench, a benchmark designed to measure models' ability to distinguish semantically correct from incorrect formalizations, and demonstrate that our trained CriticLeanGPT models can significantly outperform strong open- and closed-source baselines. Building on the CriticLean framework, we construct FineLeanCorpus, a dataset comprising over 285K problems that exhibits rich domain diversity, broad difficulty coverage, and high correctness based on human evaluation. Overall, our findings highlight that optimizing the critic phase is essential for producing reliable formalizations, and we hope our CriticLean will provide valuable insights for future advances in formal mathematical reasoning.
DexVLG: Dexterous Vision-Language-Grasp Model at Scale
Jul 03, 2025As large models gain traction, vision-language-action (VLA) systems are enabling robots to tackle increasingly complex tasks. However, limited by the difficulty of data collection, progress has mainly focused on controlling simple gripper end-effectors. There is little research on functional grasping with large models for human-like dexterous hands. In this paper, we introduce DexVLG, a large Vision-Language-Grasp model for Dexterous grasp pose prediction aligned with language instructions using single-view RGBD input. To accomplish this, we generate a dataset of 170 million dexterous grasp poses mapped to semantic parts across 174,000 objects in simulation, paired with detailed part-level captions. This large-scale dataset, named DexGraspNet 3.0, is used to train a VLM and flow-matching-based pose head capable of producing instruction-aligned grasp poses for tabletop objects. To assess DexVLG's performance, we create benchmarks in physics-based simulations and conduct real-world experiments. Extensive testing demonstrates DexVLG's strong zero-shot generalization capabilities-achieving over 76% zero-shot execution success rate and state-of-the-art part-grasp accuracy in simulation-and successful part-aligned grasps on physical objects in real-world scenarios.