 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStage-Transition Dense Reward Modeling for Reinforcement Learning
Jun 30, 2026Reinforcement learning for long-horizon robotic manipulation is often limited by sparse and delayed rewards, while manually designing dense shaping signals is costly and brittle to changes in environments and object configurations. This work proposes Stage-Transition Dense Reward (STDR), a visual reward-learning framework that converts unstructured expert videos into logically grounded dense rewards for training RL agents from scratch. STDR leverages semantic understanding to infer a task's stage structure from demonstrations, and delivers two complementary learning signals during online training: (i) stage-transition feedback that provides goal-directed reward, and (ii) within-stage progress feedback that supplies fine-grained guidance toward completing each stage. Furthermore, an out-of-distribution (OOD) detection mechanism and a grasping regulation module are integrated to enhance robustness and prevent reward hacking. Experiments on 14 manipulation tasks across MetaWorld, ManiSkill, and Franka Kitchen show that STDR consistently improves sample efficiency and success rates over multiple baselines, and matches or surpasses handcrafted dense rewards on several challenging tasks. Real-robot evaluations further indicate that STDR assigns stable, progress-aligned rewards on successful executions while producing appropriately low rewards for failures, suggesting robustness to visual noise and better-calibrated reward assignment across settings.
Knowledge Index of Noah's Ark
Jun 04, 2026Knowledge benchmarks for LLMs face three issues: scaling-driven designs that do not operationalize disciplinary representativeness; flat-payment annotation that permits lazy consensus; and unaudited ranking instability under bounded test budgets. We introduce KINA, an 899-item benchmark across 261 fine-grained disciplines, with two formal results. First, we cast representativeness as a coverage-style objective over expert-elicited anchors and operationalize disciplinary representativeness through a proxy, yielding a (1-1/e) greedy approximation (Proposition 1); the guarantee applies to the proxy, not to population representativeness. Second, we prove a bonus-on-bar tournament weakly FOSD-dominates flat payment in released-review quality, with incentive-compatibility threshold B > Delta C / Delta p_min (Theorem 1). Evaluating 42 models from 13 labs, the top model, Gemini-3.1-Pro-Preview, reaches 53.17%, followed by Claude-Opus-4.6 at 49.92% and GPT-5.4 at 48.55%, leaving substantial headroom below saturation. The full leaderboard shows a tiered structure rather than a smooth total order: a small frontier tier lies above 48%, a dense strong-model tier spans roughly 38-45%, and low-performing models remain only modestly above the 10% chance baseline. Tool augmentation adds up to 5.17 points across the five tool-use evaluations, with gains varying substantially across models. We report bootstrap ranking-stability statistics to make bounded-budget variance explicit and to discourage over-interpretation of adjacent ranks.
Copilot-Assisted Second-Thought Framework for Brain-to-Robot Hand Motion Decoding
Mar 29, 2026Motor kinematics prediction (MKP) from electroencephalography (EEG) is an important research area for developing movement-related brain-computer interfaces (BCIs). While traditional methods often rely on convolutional neural networks (CNNs) or recurrent neural networks (RNNs), Transformer-based models have shown strong ability in modeling long sequential EEG data. In this study, we propose a CNN-attention hybrid model for decoding hand kinematics from EEG during grasp-and-lift tasks, achieving strong performance in within-subject experiments. We further extend this approach to EEG-EMG multimodal decoding, which yields substantially improved results. Within-subject tests achieve PCC values of 0.9854, 0.9946, and 0.9065 for the X, Y, and Z axes, respectively, computed on the midpoint trajectory between the thumb and index finger, while cross-subject tests result in 0.9643, 0.9795, and 0.5852. The decoded trajectories from both modalities are then used to control a Franka Panda robotic arm in a MuJoCo simulation. To enhance trajectory fidelity, we introduce a copilot framework that filters low-confidence decoded points using a motion-state-aware critic within a finite-state machine. This post-processing step improves the overall within-subject PCC of EEG-only decoding to 0.93 while excluding fewer than 20% of the data points.
PhaForce: Phase-Scheduled Visual-Force Policy Learning with Slow Planning and Fast Correction for Contact-Rich Manipulation
Mar 09, 2026Contact-rich manipulation requires not only vision-dominant task semantics but also closed-loop reactions to force/torque (F/T) transients. Yet, generative visuomotor policies are typically constrained to low-frequency updates due to inference latency and action chunking, underutilizing F/T for control-rate feedback. Furthermore, existing force-aware methods often inject force continuously and indiscriminately, lacking an explicit mechanism to schedule when / how much / where to apply force across different task phases. We propose PhaForce, a phase-scheduled visual--force policy that coordinates low-rate chunk-level planning and high-rate residual correction via a unified contact/phase schedule. PhaForce comprises (i) a contact-aware phase predictor (CAP) that estimates contact probability and phase belief, (ii) a Slow diffusion planner that performs dual-gated visual--force fusion with orthogonal residual injection to preserve vision semantics while conditioning on force, and (iii) a Fast corrector that applies control-rate phase-routed residuals in interpretable corrective subspaces for within-chunk micro-adjustments. Across multiple real-robot contact-rich tasks, PhaForce achieves an average success rate of 86% (+40 pp over baselines), while also substantially improving contact quality by regulating interaction forces and exhibiting robust adaptability to OOD geometric shifts.
CriticLean: Critic-Guided Reinforcement Learning for Mathematical Formalization
Jul 08, 2025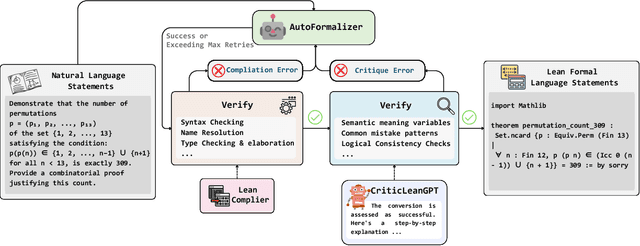

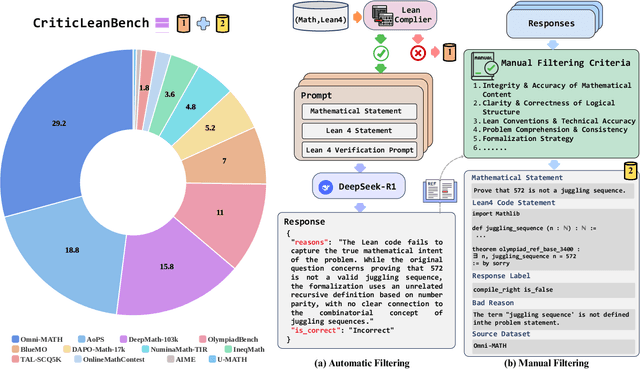
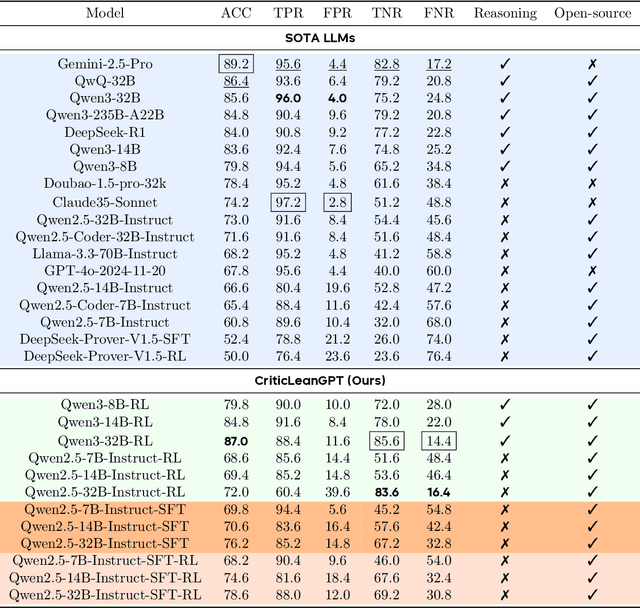
Translating natural language mathematical statements into formal, executable code is a fundamental challenge in automated theorem proving. While prior work has focused on generation and compilation success, little attention has been paid to the critic phase-the evaluation of whether generated formalizations truly capture the semantic intent of the original problem. In this paper, we introduce CriticLean, a novel critic-guided reinforcement learning framework that elevates the role of the critic from a passive validator to an active learning component. Specifically, first, we propose the CriticLeanGPT, trained via supervised fine-tuning and reinforcement learning, to rigorously assess the semantic fidelity of Lean 4 formalizations. Then, we introduce CriticLeanBench, a benchmark designed to measure models' ability to distinguish semantically correct from incorrect formalizations, and demonstrate that our trained CriticLeanGPT models can significantly outperform strong open- and closed-source baselines. Building on the CriticLean framework, we construct FineLeanCorpus, a dataset comprising over 285K problems that exhibits rich domain diversity, broad difficulty coverage, and high correctness based on human evaluation. Overall, our findings highlight that optimizing the critic phase is essential for producing reliable formalizations, and we hope our CriticLean will provide valuable insights for future advances in formal mathematical reasoning.
Time-Unified Diffusion Policy with Action Discrimination for Robotic Manipulation
Jun 11, 2025In many complex scenarios, robotic manipulation relies on generative models to estimate the distribution of multiple successful actions. As the diffusion model has better training robustness than other generative models, it performs well in imitation learning through successful robot demonstrations. However, the diffusion-based policy methods typically require significant time to iteratively denoise robot actions, which hinders real-time responses in robotic manipulation. Moreover, existing diffusion policies model a time-varying action denoising process, whose temporal complexity increases the difficulty of model training and leads to suboptimal action accuracy. To generate robot actions efficiently and accurately, we present the Time-Unified Diffusion Policy (TUDP), which utilizes action recognition capabilities to build a time-unified denoising process. On the one hand, we build a time-unified velocity field in action space with additional action discrimination information. By unifying all timesteps of action denoising, our velocity field reduces the difficulty of policy learning and speeds up action generation. On the other hand, we propose an action-wise training method, which introduces an action discrimination branch to supply additional action discrimination information. Through action-wise training, the TUDP implicitly learns the ability to discern successful actions to better denoising accuracy. Our method achieves state-of-the-art performance on RLBench with the highest success rate of 82.6% on a multi-view setup and 83.8% on a single-view setup. In particular, when using fewer denoising iterations, TUDP achieves a more significant improvement in success rate. Additionally, TUDP can produce accurate actions for a wide range of real-world tasks.
FormalMATH: Benchmarking Formal Mathematical Reasoning of Large Language Models
May 05, 2025



Formal mathematical reasoning remains a critical challenge for artificial intelligence, hindered by limitations of existing benchmarks in scope and scale. To address this, we present FormalMATH, a large-scale Lean4 benchmark comprising 5,560 formally verified problems spanning from high-school Olympiad challenges to undergraduate-level theorems across diverse domains (e.g., algebra, applied mathematics, calculus, number theory, and discrete mathematics). To mitigate the inefficiency of manual formalization, we introduce a novel human-in-the-loop autoformalization pipeline that integrates: (1) specialized large language models (LLMs) for statement autoformalization, (2) multi-LLM semantic verification, and (3) negation-based disproof filtering strategies using off-the-shelf LLM-based provers. This approach reduces expert annotation costs by retaining 72.09% of statements before manual verification while ensuring fidelity to the original natural-language problems. Our evaluation of state-of-the-art LLM-based theorem provers reveals significant limitations: even the strongest models achieve only 16.46% success rate under practical sampling budgets, exhibiting pronounced domain bias (e.g., excelling in algebra but failing in calculus) and over-reliance on simplified automation tactics. Notably, we identify a counterintuitive inverse relationship between natural-language solution guidance and proof success in chain-of-thought reasoning scenarios, suggesting that human-written informal reasoning introduces noise rather than clarity in the formal reasoning settings. We believe that FormalMATH provides a robust benchmark for benchmarking formal mathematical reasoning.
SuperGPQA: Scaling LLM Evaluation across 285 Graduate Disciplines
Feb 20, 2025Large language models (LLMs) have demonstrated remarkable proficiency in mainstream academic disciplines such as mathematics, physics, and computer science. However, human knowledge encompasses over 200 specialized disciplines, far exceeding the scope of existing benchmarks. The capabilities of LLMs in many of these specialized fields-particularly in light industry, agriculture, and service-oriented disciplines-remain inadequately evaluated. To address this gap, we present SuperGPQA, a comprehensive benchmark that evaluates graduate-level knowledge and reasoning capabilities across 285 disciplines. Our benchmark employs a novel Human-LLM collaborative filtering mechanism to eliminate trivial or ambiguous questions through iterative refinement based on both LLM responses and expert feedback. Our experimental results reveal significant room for improvement in the performance of current state-of-the-art LLMs across diverse knowledge domains (e.g., the reasoning-focused model DeepSeek-R1 achieved the highest accuracy of 61.82% on SuperGPQA), highlighting the considerable gap between current model capabilities and artificial general intelligence. Additionally, we present comprehensive insights from our management of a large-scale annotation process, involving over 80 expert annotators and an interactive Human-LLM collaborative system, offering valuable methodological guidance for future research initiatives of comparable scope.
DeepMF: Deep Motion Factorization for Closed-Loop Safety-Critical Driving Scenario Simulation
Dec 23, 2024



Safety-critical traffic scenarios are of great practical relevance to evaluating the robustness of autonomous driving (AD) systems. Given that these long-tail events are extremely rare in real-world traffic data, there is a growing body of work dedicated to the automatic traffic scenario generation. However, nearly all existing algorithms for generating safety-critical scenarios rely on snippets of previously recorded traffic events, transforming normal traffic flow into accident-prone situations directly. In other words, safety-critical traffic scenario generation is hindsight and not applicable to newly encountered and open-ended traffic events.In this paper, we propose the Deep Motion Factorization (DeepMF) framework, which extends static safety-critical driving scenario generation to closed-loop and interactive adversarial traffic simulation. DeepMF casts safety-critical traffic simulation as a Bayesian factorization that includes the assignment of hazardous traffic participants, the motion prediction of selected opponents, the reaction estimation of autonomous vehicle (AV) and the probability estimation of the accident occur. All the aforementioned terms are calculated using decoupled deep neural networks, with inputs limited to the current observation and historical states. Consequently, DeepMF can effectively and efficiently simulate safety-critical traffic scenarios at any triggered time and for any duration by maximizing the compounded posterior probability of traffic risk. Extensive experiments demonstrate that DeepMF excels in terms of risk management, flexibility, and diversity, showcasing outstanding performance in simulating a wide range of realistic, high-risk traffic scenarios.
Advancing Pre-trained Teacher: Towards Robust Feature Discrepancy for Anomaly Detection
May 03, 2024



With the wide application of knowledge distillation between an ImageNet pre-trained teacher model and a learnable student model, industrial anomaly detection has witnessed a significant achievement in the past few years. The success of knowledge distillation mainly relies on how to keep the feature discrepancy between the teacher and student model, in which it assumes that: (1) the teacher model can jointly represent two different distributions for the normal and abnormal patterns, while (2) the student model can only reconstruct the normal distribution. However, it still remains a challenging issue to maintain these ideal assumptions in practice. In this paper, we propose a simple yet effective two-stage industrial anomaly detection framework, termed as AAND, which sequentially performs Anomaly Amplification and Normality Distillation to obtain robust feature discrepancy. In the first anomaly amplification stage, we propose a novel Residual Anomaly Amplification (RAA) module to advance the pre-trained teacher encoder. With the exposure of synthetic anomalies, it amplifies anomalies via residual generation while maintaining the integrity of pre-trained model. It mainly comprises a Matching-guided Residual Gate and an Attribute-scaling Residual Generator, which can determine the residuals' proportion and characteristic, respectively. In the second normality distillation stage, we further employ a reverse distillation paradigm to train a student decoder, in which a novel Hard Knowledge Distillation (HKD) loss is built to better facilitate the reconstruction of normal patterns. Comprehensive experiments on the MvTecAD, VisA, and MvTec3D-RGB datasets show that our method achieves state-of-the-art performance.