 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorld Pilot: Steering Vision-Language-Action Models with World-Action Priors
Jun 10, 2026Vision-Language-Action (VLA) models inherit semantic grounding from large-scale pretraining and perform competently across in-distribution manipulation tasks. This grounding, however, is built on static image-text pairs, whereas manipulation is a continuous, contact-rich process whose dynamics this pretraining cannot capture. We present World Pilot, a VLA framework that augments the policy with priors from a World-Action Model (WAM), routed into the decision chain through two complementary pathways. Latent Steering conditions the perception layer on a scene-evolution latent, and Action Steering supplies an anticipated trajectory as a motion prior to the action generator. Together the two priors equip the VLA with an anticipated view of the scene and a trajectory-level motion hint alongside its semantic conditioning, and the scene-evolution prior remains effective even when supplied by a video-pretrained world model that has not been action-post-trained. World Pilot attains a state-of-the-art Total success rate of 84.7% on the LIBERO-Plus zero-shot OOD benchmark and the highest success rate on every real-robot setting across four manipulation tasks, with the largest margins under shifts in viewpoint, geometry, deformable state, and pose. Project Website: https://world-pilot.github.io/
MobileGym: A Verifiable and Highly Parallel Simulation Platform for Mobile GUI Agent Research
May 27, 2026We present MobileGym, a browser-hosted, lightweight, fully controllable environment for everyday mobile use, targeting interaction fidelity without replicating proprietary backends. It enables two capabilities previously out of reach for everyday apps: verifiable outcome signals through deterministic state-based judging over structured JSON state, and scalable online RL through low-cost parallel rollouts. The full environment state is captured, configured, forked, and compared as structured JSON, and a single server can host hundreds of parallel instances, with about 400 MB memory per instance and about 3 s cold start. A layered state model and a declarative task-definition framework keep state programmability and task creation practical at scale, and a single programmatic judging mechanism delivers both deterministic evaluation verdicts and dense RL rewards. The accompanying MobileGym-Bench provides 416 parameterized task templates, including 256 test and 160 train templates, over 28 apps, with deterministic judges and a structured AnswerSheet protocol that avoids free-text matching failures. In a Sim-to-Real case study, GRPO on Qwen3-VL-4B-Instruct gains +12.8 percentage points on the 256-task test set, and on a 59-task real-device signal subset, real-device execution retains 95.1% of the simulation-side training gain. Project page: https://mobilegym.github.io.
Claw-Anything: Benchmarking Always-On Personal Assistants with Broader Access to User's Digital World
May 25, 2026Large language model agents are increasingly envisioned as always-on personal assistants with access to anything relevant in the user's digital world. Yet current systems operate over only narrow slices of that world, limiting context-sensitive reasoning and effective assistance. Existing benchmarks similarly provide only partial user state and therefore fail to capture performance in such a broad, always-on setting. To address this gap, we introduce Claw-Anything, a benchmark that expands agent context along three dimensions: long-horizon activity histories, interdependent backend services, and integrated GUI and CLI interaction across multiple devices. To instantiate this setting, we simulate months of user activity through multi-round event injection, producing complex world states and realistic noise, including irrelevant events and conflicting signals. Agents must reason over rich contextual environments while remaining robust to such noise. This expanded scope also enables the evaluation of proactive assistance, requiring agents to anticipate user needs and deliver timely recommendations. Experiments show that GPT-5.5 achieves only 34.5% pass@1, substantially below prior benchmarks, underscoring a gap between current agent capabilities and the demands of always-on personal assistance. Alongside the benchmark, we release an automated data-generation pipeline that yields 2,000 training environments and improves the base model by 23.7%, demonstrating its utility of scalable data infrastructure.
ReinDriveGen: Reinforcement Post-Training for Out-of-Distribution Driving Scene Generation
Apr 01, 2026We present ReinDriveGen, a framework that enables full controllability over dynamic driving scenes, allowing users to freely edit actor trajectories to simulate safety-critical corner cases such as front-vehicle collisions, drifting cars, vehicles spinning out of control, pedestrians jaywalking, and cyclists cutting across lanes. Our approach constructs a dynamic 3D point cloud scene from multi-frame LiDAR data, introduces a vehicle completion module to reconstruct full 360° geometry from partial observations, and renders the edited scene into 2D condition images that guide a video diffusion model to synthesize realistic driving videos. Since such edited scenarios inevitably fall outside the training distribution, we further propose an RL-based post-training strategy with a pairwise preference model and a pairwise reward mechanism, enabling robust quality improvement under out-of-distribution conditions without ground-truth supervision. Extensive experiments demonstrate that ReinDriveGen outperforms existing approaches on edited driving scenarios and achieves state-of-the-art results on novel ego viewpoint synthesis.
DynVLA: Learning World Dynamics for Action Reasoning in Autonomous Driving
Mar 11, 2026We propose DynVLA, a driving VLA model that introduces a new CoT paradigm termed Dynamics CoT. DynVLA forecasts compact world dynamics before action generation, enabling more informed and physically grounded decision-making. To obtain compact dynamics representations, DynVLA introduces a Dynamics Tokenizer that compresses future evolution into a small set of dynamics tokens. Considering the rich environment dynamics in interaction-intensive driving scenarios, DynVLA decouples ego-centric and environment-centric dynamics, yielding more accurate world dynamics modeling. We then train DynVLA to generate dynamics tokens before actions through SFT and RFT, improving decision quality while maintaining latency-efficient inference. Compared to Textual CoT, which lacks fine-grained spatiotemporal understanding, and Visual CoT, which introduces substantial redundancy due to dense image prediction, Dynamics CoT captures the evolution of the world in a compact, interpretable, and efficient form. Extensive experiments on NAVSIM, Bench2Drive, and a large-scale in-house dataset demonstrate that DynVLA consistently outperforms Textual CoT and Visual CoT methods, validating the effectiveness and practical value of Dynamics CoT.
GA-Drive: Geometry-Appearance Decoupled Modeling for Free-viewpoint Driving Scene Generatio
Feb 24, 2026A free-viewpoint, editable, and high-fidelity driving simulator is crucial for training and evaluating end-to-end autonomous driving systems. In this paper, we present GA-Drive, a novel simulation framework capable of generating camera views along user-specified novel trajectories through Geometry-Appearance Decoupling and Diffusion-Based Generation. Given a set of images captured along a recorded trajectory and the corresponding scene geometry, GA-Drive synthesizes novel pseudo-views using geometry information. These pseudo-views are then transformed into photorealistic views using a trained video diffusion model. In this way, we decouple the geometry and appearance of scenes. An advantage of such decoupling is its support for appearance editing via state-of-the-art video-to-video editing techniques, while preserving the underlying geometry, enabling consistent edits across both original and novel trajectories. Extensive experiments demonstrate that GA-Drive substantially outperforms existing methods in terms of NTA-IoU, NTL-IoU, and FID scores.
CLI-Gym: Scalable CLI Task Generation via Agentic Environment Inversion
Feb 11, 2026Agentic coding requires agents to effectively interact with runtime environments, e.g., command line interfaces (CLI), so as to complete tasks like resolving dependency issues, fixing system problems, etc. But it remains underexplored how such environment-intensive tasks can be obtained at scale to enhance agents' capabilities. To address this, based on an analogy between the Dockerfile and the agentic task, we propose to employ agents to simulate and explore environment histories, guided by execution feedback. By tracing histories of a healthy environment, its state can be inverted to an earlier one with runtime failures, from which a task can be derived by packing the buggy state and the corresponding error messages. With our method, named CLI-Gym, a total of 1,655 environment-intensive tasks are derived, being the largest collection of its kind. Moreover, with curated successful trajectories, our fine-tuned model, named LiberCoder, achieves substantial absolute improvements of +21.1% (to 46.1%) on Terminal-Bench, outperforming various strong baselines. To our knowledge, this is the first public pipeline for scalable derivation of environment-intensive tasks.
FeatureBench: Benchmarking Agentic Coding for Complex Feature Development
Feb 11, 2026Agents powered by large language models (LLMs) are increasingly adopted in the software industry, contributing code as collaborators or even autonomous developers. As their presence grows, it becomes important to assess the current boundaries of their coding abilities. Existing agentic coding benchmarks, however, cover a limited task scope, e.g., bug fixing within a single pull request (PR), and often rely on non-executable evaluations or lack an automated approach for continually updating the evaluation coverage. To address such issues, we propose FeatureBench, a benchmark designed to evaluate agentic coding performance in end-to-end, feature-oriented software development. FeatureBench incorporates an execution-based evaluation protocol and a scalable test-driven method that automatically derives tasks from code repositories with minimal human effort. By tracing from unit tests along a dependency graph, our approach can identify feature-level coding tasks spanning multiple commits and PRs scattered across the development timeline, while ensuring the proper functioning of other features after the separation. Using this framework, we curated 200 challenging evaluation tasks and 3825 executable environments from 24 open-source repositories in the first version of our benchmark. Empirical evaluation reveals that the state-of-the-art agentic model, such as Claude 4.5 Opus, which achieves a 74.4% resolved rate on SWE-bench, succeeds on only 11.0% of tasks, opening new opportunities for advancing agentic coding. Moreover, benefiting from our automated task collection toolkit, FeatureBench can be easily scaled and updated over time to mitigate data leakage. The inherent verifiability of constructed environments also makes our method potentially valuable for agent training.
NeoVerse: Enhancing 4D World Model with in-the-wild Monocular Videos
Jan 01, 2026In this paper, we propose NeoVerse, a versatile 4D world model that is capable of 4D reconstruction, novel-trajectory video generation, and rich downstream applications. We first identify a common limitation of scalability in current 4D world modeling methods, caused either by expensive and specialized multi-view 4D data or by cumbersome training pre-processing. In contrast, our NeoVerse is built upon a core philosophy that makes the full pipeline scalable to diverse in-the-wild monocular videos. Specifically, NeoVerse features pose-free feed-forward 4D reconstruction, online monocular degradation pattern simulation, and other well-aligned techniques. These designs empower NeoVerse with versatility and generalization to various domains. Meanwhile, NeoVerse achieves state-of-the-art performance in standard reconstruction and generation benchmarks. Our project page is available at https://neoverse-4d.github.io
DriveVLA-W0: World Models Amplify Data Scaling Law in Autonomous Driving
Oct 14, 2025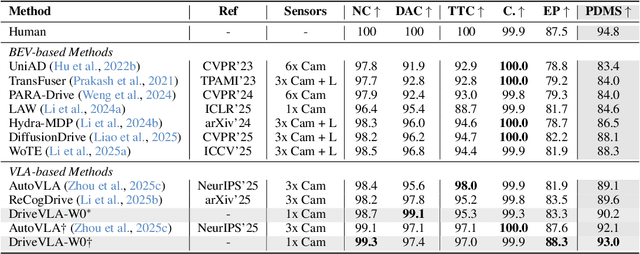
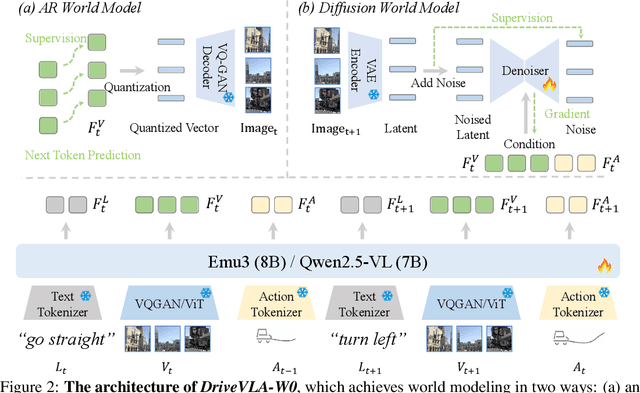

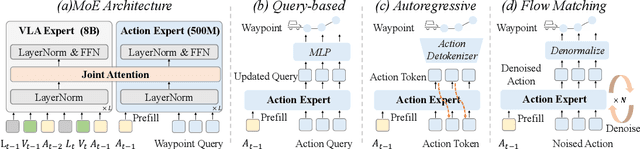
Scaling Vision-Language-Action (VLA) models on large-scale data offers a promising path to achieving a more generalized driving intelligence. However, VLA models are limited by a ``supervision deficit'': the vast model capacity is supervised by sparse, low-dimensional actions, leaving much of their representational power underutilized. To remedy this, we propose \textbf{DriveVLA-W0}, a training paradigm that employs world modeling to predict future images. This task generates a dense, self-supervised signal that compels the model to learn the underlying dynamics of the driving environment. We showcase the paradigm's versatility by instantiating it for two dominant VLA archetypes: an autoregressive world model for VLAs that use discrete visual tokens, and a diffusion world model for those operating on continuous visual features. Building on the rich representations learned from world modeling, we introduce a lightweight action expert to address the inference latency for real-time deployment. Extensive experiments on the NAVSIM v1/v2 benchmark and a 680x larger in-house dataset demonstrate that DriveVLA-W0 significantly outperforms BEV and VLA baselines. Crucially, it amplifies the data scaling law, showing that performance gains accelerate as the training dataset size increases.