 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWebCompass: Towards Multimodal Web Coding Evaluation for Code Language Models
Apr 20, 2026Large language models are rapidly evolving into interactive coding agents capable of end-to-end web coding, yet existing benchmarks evaluate only narrow slices of this capability, typically text-conditioned generation with static-correctness metrics, leaving visual fidelity, interaction quality, and codebase-level reasoning largely unmeasured. We introduce WebCompass, a multimodal benchmark that provides unified lifecycle evaluation of web engineering capability. Recognizing that real-world web coding is an iterative cycle of generation, editing, and repair, WebCompass spans three input modalities (text, image, video) and three task types (generation, editing, repair), yielding seven task categories that mirror professional workflows. Through a multi-stage, human-in-the-loop pipeline, we curate instances covering 15 generation domains, 16 editing operation types, and 11 repair defect types, each annotated at Easy/Medium/Hard levels. For evaluation, we adopt a checklist-guided LLM-as-a-Judge protocol for editing and repair, and propose a novel Agent-as-a-Judge paradigm for generation that autonomously executes generated websites in a real browser, explores interactive behaviors via the Model Context Protocol (MCP), and iteratively synthesizes targeted test cases, closely approximating human acceptance testing. We evaluate representative closed-source and open-source models and observe that: (1) closed-source models remain substantially stronger and more balanced; (2) editing and repair exhibit distinct difficulty profiles, with repair preserving interactivity better but remaining execution-challenging; (3) aesthetics is the most persistent bottleneck, especially for open-source models; and (4) framework choice materially affects outcomes, with Vue consistently challenging while React and Vanilla/HTML perform more strongly depending on task type.
CodeTracer: Towards Traceable Agent States
Apr 14, 2026Code agents are advancing rapidly, but debugging them is becoming increasingly difficult. As frameworks orchestrate parallel tool calls and multi-stage workflows over complex tasks, making the agent's state transitions and error propagation hard to observe. In these runs, an early misstep can trap the agent in unproductive loops or even cascade into fundamental errors, forming hidden error chains that make it hard to tell when the agent goes off track and why. Existing agent tracing analyses either focus on simple interaction or rely on small-scale manual inspection, which limits their scalability and usefulness for real coding workflows. We present CodeTracer, a tracing architecture that parses heterogeneous run artifacts through evolving extractors, reconstructs the full state transition history as a hierarchical trace tree with persistent memory, and performs failure onset localization to pinpoint the failure origin and its downstream chain. To enable systematic evaluation, we construct CodeTraceBench from a large collection of executed trajectories generated by four widely used code agent frameworks on diverse code tasks (e.g., bug fixing, refactoring, and terminal interaction), with supervision at both the stage and step levels for failure localization. Experiments show that CodeTracer substantially outperforms direct prompting and lightweight baselines, and that replaying its diagnostic signals consistently recovers originally failed runs under matched budgets. Our code and data are publicly available.
Seedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model
Dec 23, 2025Recent strides in video generation have paved the way for unified audio-visual generation. In this work, we present Seedance 1.5 pro, a foundational model engineered specifically for native, joint audio-video generation. Leveraging a dual-branch Diffusion Transformer architecture, the model integrates a cross-modal joint module with a specialized multi-stage data pipeline, achieving exceptional audio-visual synchronization and superior generation quality. To ensure practical utility, we implement meticulous post-training optimizations, including Supervised Fine-Tuning (SFT) on high-quality datasets and Reinforcement Learning from Human Feedback (RLHF) with multi-dimensional reward models. Furthermore, we introduce an acceleration framework that boosts inference speed by over 10X. Seedance 1.5 pro distinguishes itself through precise multilingual and dialect lip-syncing, dynamic cinematic camera control, and enhanced narrative coherence, positioning it as a robust engine for professional-grade content creation. Seedance 1.5 pro is now accessible on Volcano Engine at https://console.volcengine.com/ark/region:ark+cn-beijing/experience/vision?type=GenVideo.
SWE-Compass: Towards Unified Evaluation of Agentic Coding Abilities for Large Language Models
Nov 07, 2025Evaluating large language models (LLMs) for software engineering has been limited by narrow task coverage, language bias, and insufficient alignment with real-world developer workflows. Existing benchmarks often focus on algorithmic problems or Python-centric bug fixing, leaving critical dimensions of software engineering underexplored. To address these gaps, we introduce SWE-Compass1, a comprehensive benchmark that unifies heterogeneous code-related evaluations into a structured and production-aligned framework. SWE-Compass spans 8 task types, 8 programming scenarios, and 10 programming languages, with 2000 high-quality instances curated from authentic GitHub pull requests and refined through systematic filtering and validation. We benchmark ten state-of-the-art LLMs under two agentic frameworks, SWE-Agent and Claude Code, revealing a clear hierarchy of difficulty across task types, languages, and scenarios. Moreover, by aligning evaluation with real-world developer practices, SWE-Compass provides a rigorous and reproducible foundation for diagnosing and advancing agentic coding capabilities in large language models.
CriticLean: Critic-Guided Reinforcement Learning for Mathematical Formalization
Jul 08, 2025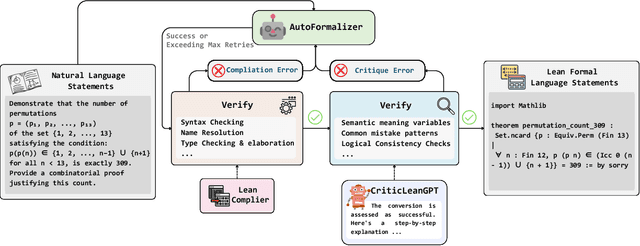

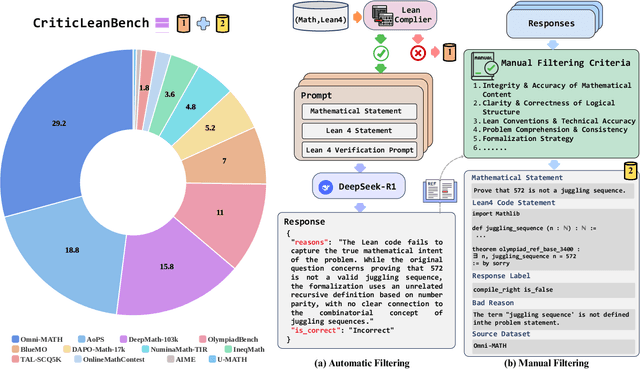
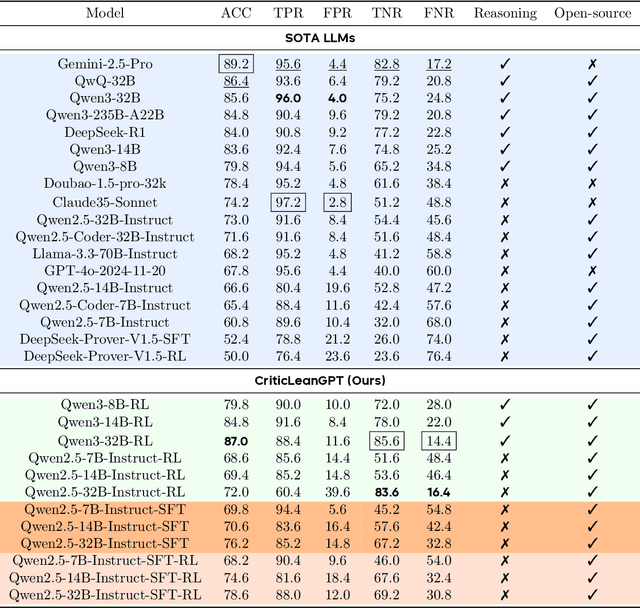
Translating natural language mathematical statements into formal, executable code is a fundamental challenge in automated theorem proving. While prior work has focused on generation and compilation success, little attention has been paid to the critic phase-the evaluation of whether generated formalizations truly capture the semantic intent of the original problem. In this paper, we introduce CriticLean, a novel critic-guided reinforcement learning framework that elevates the role of the critic from a passive validator to an active learning component. Specifically, first, we propose the CriticLeanGPT, trained via supervised fine-tuning and reinforcement learning, to rigorously assess the semantic fidelity of Lean 4 formalizations. Then, we introduce CriticLeanBench, a benchmark designed to measure models' ability to distinguish semantically correct from incorrect formalizations, and demonstrate that our trained CriticLeanGPT models can significantly outperform strong open- and closed-source baselines. Building on the CriticLean framework, we construct FineLeanCorpus, a dataset comprising over 285K problems that exhibits rich domain diversity, broad difficulty coverage, and high correctness based on human evaluation. Overall, our findings highlight that optimizing the critic phase is essential for producing reliable formalizations, and we hope our CriticLean will provide valuable insights for future advances in formal mathematical reasoning.
KORGym: A Dynamic Game Platform for LLM Reasoning Evaluation
May 21, 2025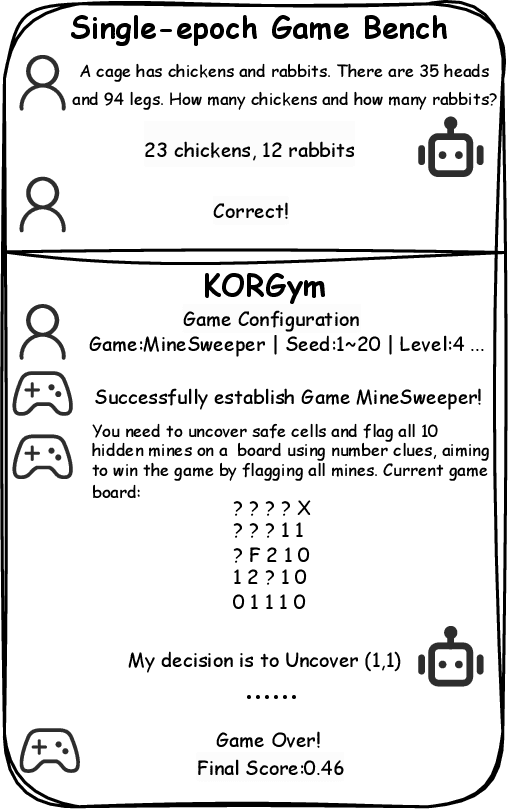
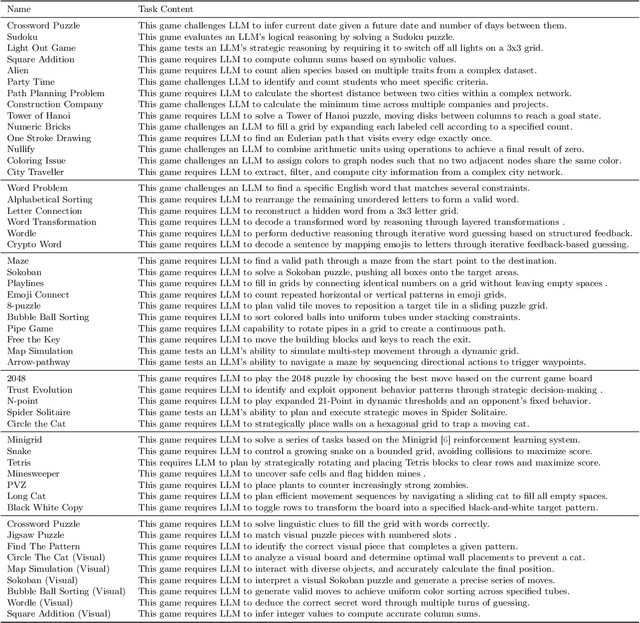
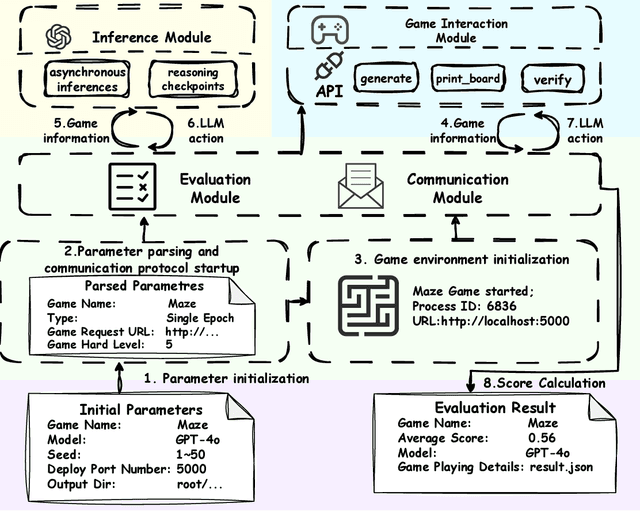

Recent advancements in large language models (LLMs) underscore the need for more comprehensive evaluation methods to accurately assess their reasoning capabilities. Existing benchmarks are often domain-specific and thus cannot fully capture an LLM's general reasoning potential. To address this limitation, we introduce the Knowledge Orthogonal Reasoning Gymnasium (KORGym), a dynamic evaluation platform inspired by KOR-Bench and Gymnasium. KORGym offers over fifty games in either textual or visual formats and supports interactive, multi-turn assessments with reinforcement learning scenarios. Using KORGym, we conduct extensive experiments on 19 LLMs and 8 VLMs, revealing consistent reasoning patterns within model families and demonstrating the superior performance of closed-source models. Further analysis examines the effects of modality, reasoning strategies, reinforcement learning techniques, and response length on model performance. We expect KORGym to become a valuable resource for advancing LLM reasoning research and developing evaluation methodologies suited to complex, interactive environments.
IV-Bench: A Benchmark for Image-Grounded Video Perception and Reasoning in Multimodal LLMs
Apr 21, 2025Existing evaluation frameworks for Multimodal Large Language Models (MLLMs) primarily focus on image reasoning or general video understanding tasks, largely overlooking the significant role of image context in video comprehension. To bridge this gap, we propose IV-Bench, the first comprehensive benchmark for evaluating Image-Grounded Video Perception and Reasoning. IV-Bench consists of 967 videos paired with 2,585 meticulously annotated image-text queries across 13 tasks (7 perception and 6 reasoning tasks) and 5 representative categories. Extensive evaluations of state-of-the-art open-source (e.g., InternVL2.5, Qwen2.5-VL) and closed-source (e.g., GPT-4o, Gemini2-Flash and Gemini2-Pro) MLLMs demonstrate that current models substantially underperform in image-grounded video Perception and Reasoning, merely achieving at most 28.9% accuracy. Further analysis reveals key factors influencing model performance on IV-Bench, including inference pattern, frame number, and resolution. Additionally, through a simple data synthesis approach, we demonstratethe challenges of IV- Bench extend beyond merely aligning the data format in the training proecss. These findings collectively provide valuable insights for future research. Our codes and data are released in https://github.com/multimodal-art-projection/IV-Bench.
SuperGPQA: Scaling LLM Evaluation across 285 Graduate Disciplines
Feb 20, 2025Large language models (LLMs) have demonstrated remarkable proficiency in mainstream academic disciplines such as mathematics, physics, and computer science. However, human knowledge encompasses over 200 specialized disciplines, far exceeding the scope of existing benchmarks. The capabilities of LLMs in many of these specialized fields-particularly in light industry, agriculture, and service-oriented disciplines-remain inadequately evaluated. To address this gap, we present SuperGPQA, a comprehensive benchmark that evaluates graduate-level knowledge and reasoning capabilities across 285 disciplines. Our benchmark employs a novel Human-LLM collaborative filtering mechanism to eliminate trivial or ambiguous questions through iterative refinement based on both LLM responses and expert feedback. Our experimental results reveal significant room for improvement in the performance of current state-of-the-art LLMs across diverse knowledge domains (e.g., the reasoning-focused model DeepSeek-R1 achieved the highest accuracy of 61.82% on SuperGPQA), highlighting the considerable gap between current model capabilities and artificial general intelligence. Additionally, we present comprehensive insights from our management of a large-scale annotation process, involving over 80 expert annotators and an interactive Human-LLM collaborative system, offering valuable methodological guidance for future research initiatives of comparable scope.
A Survey on Large Language Model Security and Privacy: The Good, the Bad, and the Ugly
Dec 04, 2023



Large Language Models (LLMs), such as GPT-3 and BERT, have revolutionized natural language understanding and generation. They possess deep language comprehension, human-like text generation capabilities, contextual awareness, and robust problem-solving skills, making them invaluable in various domains (e.g., search engines, customer support, translation). In the meantime, LLMs have also gained traction in the security community, revealing security vulnerabilities and showcasing their potential in security-related tasks. This paper explores the intersection of LLMs with security and privacy. Specifically, we investigate how LLMs positively impact security and privacy, potential risks and threats associated with their use, and inherent vulnerabilities within LLMs. Through a comprehensive literature review, the paper categorizes findings into "The Good" (beneficial LLM applications), "The Bad" (offensive applications), and "The Ugly" (vulnerabilities and their defenses). We have some interesting findings. For example, LLMs have proven to enhance code and data security, outperforming traditional methods. However, they can also be harnessed for various attacks (particularly user-level attacks) due to their human-like reasoning abilities. We have identified areas that require further research efforts. For example, research on model and parameter extraction attacks is limited and often theoretical, hindered by LLM parameter scale and confidentiality. Safe instruction tuning, a recent development, requires more exploration. We hope that our work can shed light on the LLMs' potential to both bolster and jeopardize cybersecurity.
Towards Few-shot Out-of-Distribution Detection
Nov 20, 2023



Out-of-distribution (OOD) detection is critical for ensuring the reliability of open-world intelligent systems. Despite the notable advancements in existing OOD detection methodologies, our study identifies a significant performance drop under the scarcity of training samples. In this context, we introduce a novel few-shot OOD detection benchmark, carefully constructed to address this gap. Our empirical analysis reveals the superiority of ParameterEfficient Fine-Tuning (PEFT) strategies, such as visual prompt tuning and visual adapter tuning, over conventional techniques, including fully fine-tuning and linear probing tuning in the few-shot OOD detection task. Recognizing some crucial information from the pre-trained model, which is pivotal for OOD detection, may be lost during the fine-tuning process, we propose a method termed DomainSpecific and General Knowledge Fusion (DSGF). This approach is designed to be compatible with diverse fine-tuning frameworks. Our experiments show that the integration of DSGF significantly enhances the few-shot OOD detection capabilities across various methods and fine-tuning methodologies, including fully fine-tuning, visual adapter tuning, and visual prompt tuning. The code will be released.