 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoGUI-v2: A Comprehensive Multi-Modal GUI Functionality Understanding Benchmark
Apr 27, 2026Autonomous agents capable of navigating Graphical User Interfaces (GUIs) hold the potential to revolutionize digital productivity. However, achieving true digital autonomy extends beyond reactive element matching; it necessitates a predictive mental model of interface dynamics and the ability to foresee the "digital world state" resulting from interactions. Despite the perceptual capabilities of modern Vision-Language Models (VLMs), existing benchmarks remain bifurcated (focusing either on black-box task completion or static, shallow grounding), thereby failing to assess whether agents truly comprehend the implicit functionality and transition logic of GUIs. To bridge this gap, we introduce AutoGUI-v2, a comprehensive benchmark designed to evaluate deep GUI functionality understanding and interaction outcome prediction. We construct the benchmark using a novel VLM-human collaborative pipeline that recursively parses multi-platform screenshots into hierarchical functional regions to generate diverse evaluation tasks. Providing 2,753 tasks across six operating systems, AutoGUI-v2 rigorously tests agents on region and element-level semantics, grounding, and dynamic state prediction. Our evaluation reveals a striking dichotomy in VLMs: while open-source models fine-tuned on agent data (e.g., Qwen3-VL) excel at functional grounding, commercial models (e.g., Gemini-2.5-Pro-Thinking) dominate in functionality captioning. Crucially, all models struggle with complex interaction logic of uncommon actions, highlighting that deep functional understanding remains a significant hurdle. By systematically measuring these foundational capabilities, AutoGUI-v2 offers a new lens for advancing the next generation of GUI agents.
GoClick: Lightweight Element Grounding Model for Autonomous GUI Interaction
Apr 27, 2026Graphical User Interface (GUI) element grounding (precisely locating elements on screenshots based on natural language instructions) is fundamental for agents interacting with GUIs. Deploying this capability directly on resource-constrained devices like mobile phones is increasingly critical for GUI agents requiring low latency. However, this goal faces a significant challenge, as current visual grounding methods typically employ large vision-language model (VLM) (more than 2.5B parameters), making them impractical for on-device execution due to memory and computational constraints. To address this, this paper introduces GoClick, a lightweight GUI element grounding VLM with only 230M parameters that achieves excellent visual grounding accuracy, even on par with significantly larger models. Simply downsizing existing decoder-only VLMs is a straightforward way to design a lightweight model, but our experiments reveal that this approach yields suboptimal results. Instead, we select an encoder-decoder architecture, which outperforms decoder-only alternatives at small parameter scales for GUI grounding tasks. Additionally, the limited capacity of small VLMs encourages us to develop a Progressive Data Refinement pipeline that utilizes task type filtering and data ratio adjustment to extract a high-quality 3.8M-sample core set from a 10.8M raw dataset. Training GoClick using this core set brings notable grounding accuracy gains. Our experiments show that GoClick excels on multiple GUI element grounding benchmarks while maintaining a small size and high inference speed. GoClick also enhances GUI agent performance when integrated into a device-cloud collaboration framework, where GoClick helps cloud-based task planners perform precise element localization and achieve higher success rates. We hope our method serves as a meaningful exploration within the GUI agent community.
MiroFlow: Towards High-Performance and Robust Open-Source Agent Framework for General Deep Research Tasks
Feb 26, 2026Despite the remarkable progress of large language models (LLMs), the capabilities of standalone LLMs have begun to plateau when tackling real-world, complex tasks that require interaction with external tools and dynamic environments. Although recent agent frameworks aim to enhance model autonomy through tool integration and external interaction, they still suffer from naive workflows, unstable performance, limited support across diverse benchmarks and tasks, and heavy reliance on costly commercial APIs. In this work, we propose a high-performance and robust open-source agent framework, termed MiroFlow, which incorporates an agent graph for flexible orchestration, an optional deep reasoning mode to enhance performance, and a robust workflow execution to ensure stable and reproducible performance. Extensive experiments demonstrate that MiroFlow consistently achieves state-of-the-art performance across multiple agent benchmarks, including GAIA, BrowseComp-EN/ZH, HLE, xBench-DeepSearch, and notably FutureX. We hope it could serve as an easily accessible, reproducible, and comparable baseline for the deep research community.
MiroThinker: Pushing the Performance Boundaries of Open-Source Research Agents via Model, Context, and Interactive Scaling
Nov 18, 2025We present MiroThinker v1.0, an open-source research agent designed to advance tool-augmented reasoning and information-seeking capabilities. Unlike previous agents that only scale up model size or context length, MiroThinker explores interaction scaling at the model level, systematically training the model to handle deeper and more frequent agent-environment interactions as a third dimension of performance improvement. Unlike LLM test-time scaling, which operates in isolation and risks degradation with longer reasoning chains, interactive scaling leverages environment feedback and external information acquisition to correct errors and refine trajectories. Through reinforcement learning, the model achieves efficient interaction scaling: with a 256K context window, it can perform up to 600 tool calls per task, enabling sustained multi-turn reasoning and complex real-world research workflows. Across four representative benchmarks-GAIA, HLE, BrowseComp, and BrowseComp-ZH-the 72B variant achieves up to 81.9%, 37.7%, 47.1%, and 55.6% accuracy respectively, surpassing previous open-source agents and approaching commercial counterparts such as GPT-5-high. Our analysis reveals that MiroThinker benefits from interactive scaling consistently: research performance improves predictably as the model engages in deeper and more frequent agent-environment interactions, demonstrating that interaction depth exhibits scaling behaviors analogous to model size and context length. These findings establish interaction scaling as a third critical dimension for building next-generation open research agents, complementing model capacity and context windows.
DriveVLA-W0: World Models Amplify Data Scaling Law in Autonomous Driving
Oct 14, 2025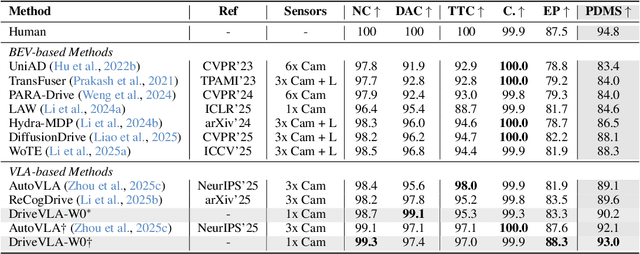
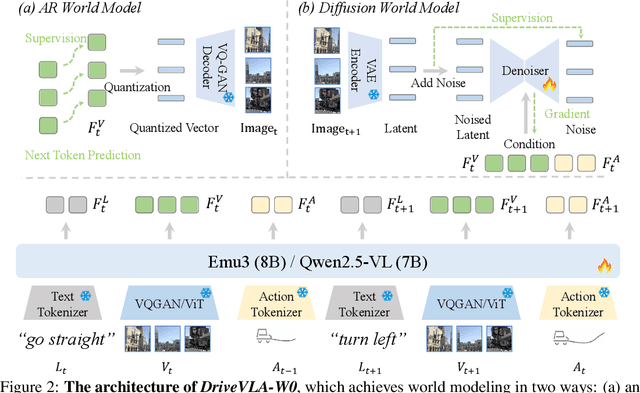

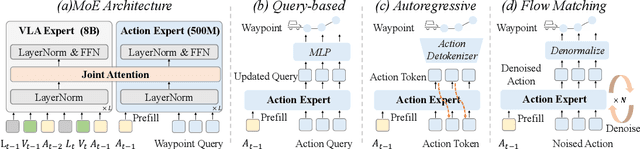
Scaling Vision-Language-Action (VLA) models on large-scale data offers a promising path to achieving a more generalized driving intelligence. However, VLA models are limited by a ``supervision deficit'': the vast model capacity is supervised by sparse, low-dimensional actions, leaving much of their representational power underutilized. To remedy this, we propose \textbf{DriveVLA-W0}, a training paradigm that employs world modeling to predict future images. This task generates a dense, self-supervised signal that compels the model to learn the underlying dynamics of the driving environment. We showcase the paradigm's versatility by instantiating it for two dominant VLA archetypes: an autoregressive world model for VLAs that use discrete visual tokens, and a diffusion world model for those operating on continuous visual features. Building on the rich representations learned from world modeling, we introduce a lightweight action expert to address the inference latency for real-time deployment. Extensive experiments on the NAVSIM v1/v2 benchmark and a 680x larger in-house dataset demonstrate that DriveVLA-W0 significantly outperforms BEV and VLA baselines. Crucially, it amplifies the data scaling law, showing that performance gains accelerate as the training dataset size increases.
Multi-Agent Tool-Integrated Policy Optimization
Oct 06, 2025



Large language models (LLMs) increasingly rely on multi-turn tool-integrated planning for knowledge-intensive and complex reasoning tasks. Existing implementations typically rely on a single agent, but they suffer from limited context length and noisy tool responses. A natural solution is to adopt a multi-agent framework with planner- and worker-agents to manage context. However, no existing methods support effective reinforcement learning post-training of tool-integrated multi-agent frameworks. To address this gap, we propose Multi-Agent Tool-Integrated Policy Optimization (MATPO), which enables distinct roles (planner and worker) to be trained within a single LLM instance using role-specific prompts via reinforcement learning. MATPO is derived from a principled credit assignment mechanism across planner and worker rollouts. This design eliminates the need to deploy multiple LLMs, which would be memory-intensive, while preserving the benefits of specialization. Experiments on GAIA-text, WebWalkerQA, and FRAMES show that MATPO consistently outperforms single-agent baselines by an average of 18.38% relative improvement in performance and exhibits greater robustness to noisy tool outputs. Our findings highlight the effectiveness of unifying multiple agent roles within a single LLM and provide practical insights for stable and efficient multi-agent RL training.
Unified Vision-Language-Action Model
Jun 24, 2025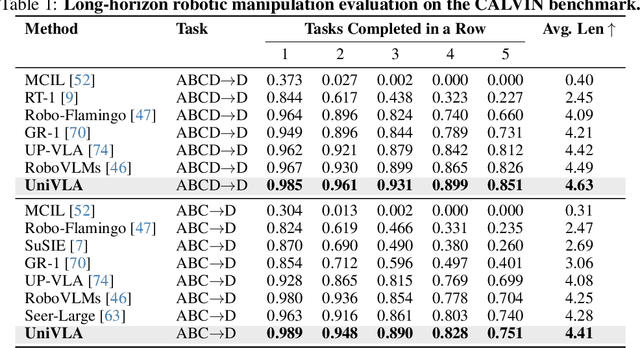
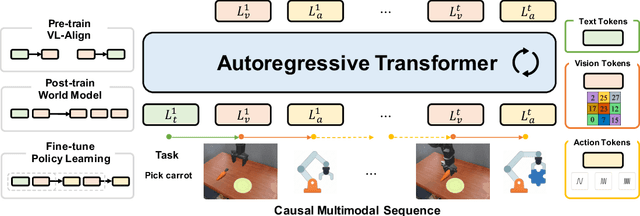
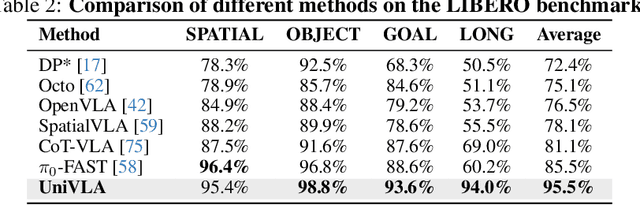
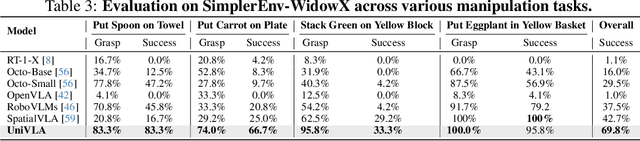
Vision-language-action models (VLAs) have garnered significant attention for their potential in advancing robotic manipulation. However, previous approaches predominantly rely on the general comprehension capabilities of vision-language models (VLMs) to generate action signals, often overlooking the rich temporal and causal structure embedded in visual observations. In this paper, we present UniVLA, a unified and native multimodal VLA model that autoregressively models vision, language, and action signals as discrete token sequences. This formulation enables flexible multimodal tasks learning, particularly from large-scale video data. By incorporating world modeling during post-training, UniVLA captures causal dynamics from videos, facilitating effective transfer to downstream policy learning--especially for long-horizon tasks. Our approach sets new state-of-the-art results across several widely used simulation benchmarks, including CALVIN, LIBERO, and Simplenv-Bridge, significantly surpassing previous methods. For example, UniVLA achieves 95.5% average success rate on LIBERO benchmark, surpassing pi0-FAST's 85.5%. We further demonstrate its broad applicability on real-world ALOHA manipulation and autonomous driving.
Dita: Scaling Diffusion Transformer for Generalist Vision-Language-Action Policy
Mar 25, 2025While recent vision-language-action models trained on diverse robot datasets exhibit promising generalization capabilities with limited in-domain data, their reliance on compact action heads to predict discretized or continuous actions constrains adaptability to heterogeneous action spaces. We present Dita, a scalable framework that leverages Transformer architectures to directly denoise continuous action sequences through a unified multimodal diffusion process. Departing from prior methods that condition denoising on fused embeddings via shallow networks, Dita employs in-context conditioning -- enabling fine-grained alignment between denoised actions and raw visual tokens from historical observations. This design explicitly models action deltas and environmental nuances. By scaling the diffusion action denoiser alongside the Transformer's scalability, Dita effectively integrates cross-embodiment datasets across diverse camera perspectives, observation scenes, tasks, and action spaces. Such synergy enhances robustness against various variances and facilitates the successful execution of long-horizon tasks. Evaluations across extensive benchmarks demonstrate state-of-the-art or comparative performance in simulation. Notably, Dita achieves robust real-world adaptation to environmental variances and complex long-horizon tasks through 10-shot finetuning, using only third-person camera inputs. The architecture establishes a versatile, lightweight and open-source baseline for generalist robot policy learning. Project Page: https://robodita.github.io.
AutoGUI: Scaling GUI Grounding with Automatic Functionality Annotations from LLMs
Feb 04, 2025



User interface understanding with vision-language models has received much attention due to its potential for enabling next-generation software automation. However, existing UI datasets either only provide large-scale context-free element annotations or contextualized functional descriptions for elements at a much smaller scale. In this work, we propose the \methodname{} pipeline for automatically annotating UI elements with detailed functionality descriptions at scale. Specifically, we leverage large language models (LLMs) to infer element functionality by comparing the UI content changes before and after simulated interactions with specific UI elements. To improve annotation quality, we propose LLM-aided rejection and verification, eliminating invalid and incorrect annotations without human labor. We construct an \methodname{}-704k dataset using the proposed pipeline, featuring multi-resolution, multi-device screenshots, diverse data domains, and detailed functionality annotations that have never been provided by previous datasets. Human evaluation shows that the AutoGUI pipeline achieves annotation correctness comparable to trained human annotators. Extensive experimental results show that our \methodname{}-704k dataset remarkably enhances VLM's UI grounding capabilities, exhibits significant scaling effects, and outperforms existing web pre-training data types. We envision AutoGUI as a scalable pipeline for generating massive data to build GUI-oriented VLMs. AutoGUI dataset can be viewed at this anonymous URL: https://autogui-project.github.io/.
DrivingGPT: Unifying Driving World Modeling and Planning with Multi-modal Autoregressive Transformers
Dec 24, 2024



World model-based searching and planning are widely recognized as a promising path toward human-level physical intelligence. However, current driving world models primarily rely on video diffusion models, which specialize in visual generation but lack the flexibility to incorporate other modalities like action. In contrast, autoregressive transformers have demonstrated exceptional capability in modeling multimodal data. Our work aims to unify both driving model simulation and trajectory planning into a single sequence modeling problem. We introduce a multimodal driving language based on interleaved image and action tokens, and develop DrivingGPT to learn joint world modeling and planning through standard next-token prediction. Our DrivingGPT demonstrates strong performance in both action-conditioned video generation and end-to-end planning, outperforming strong baselines on large-scale nuPlan and NAVSIM benchmarks.