 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynVLA: Learning World Dynamics for Action Reasoning in Autonomous Driving
Mar 11, 2026We propose DynVLA, a driving VLA model that introduces a new CoT paradigm termed Dynamics CoT. DynVLA forecasts compact world dynamics before action generation, enabling more informed and physically grounded decision-making. To obtain compact dynamics representations, DynVLA introduces a Dynamics Tokenizer that compresses future evolution into a small set of dynamics tokens. Considering the rich environment dynamics in interaction-intensive driving scenarios, DynVLA decouples ego-centric and environment-centric dynamics, yielding more accurate world dynamics modeling. We then train DynVLA to generate dynamics tokens before actions through SFT and RFT, improving decision quality while maintaining latency-efficient inference. Compared to Textual CoT, which lacks fine-grained spatiotemporal understanding, and Visual CoT, which introduces substantial redundancy due to dense image prediction, Dynamics CoT captures the evolution of the world in a compact, interpretable, and efficient form. Extensive experiments on NAVSIM, Bench2Drive, and a large-scale in-house dataset demonstrate that DynVLA consistently outperforms Textual CoT and Visual CoT methods, validating the effectiveness and practical value of Dynamics CoT.
DriveVLA-W0: World Models Amplify Data Scaling Law in Autonomous Driving
Oct 14, 2025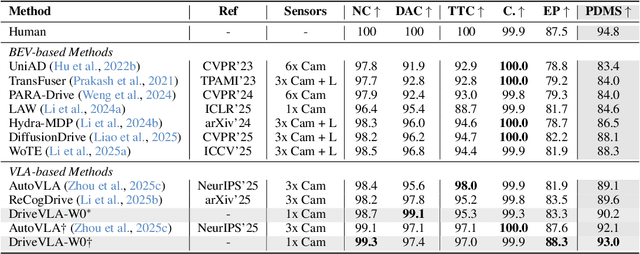
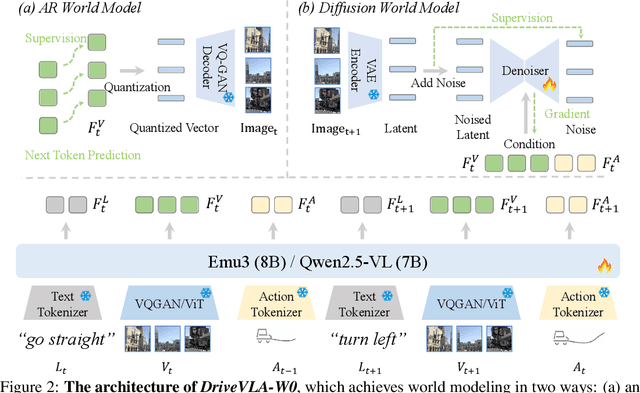

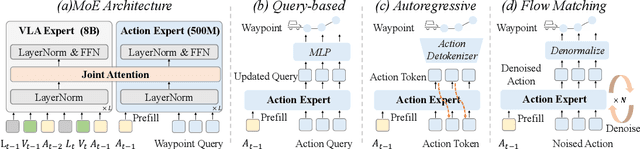
Scaling Vision-Language-Action (VLA) models on large-scale data offers a promising path to achieving a more generalized driving intelligence. However, VLA models are limited by a ``supervision deficit'': the vast model capacity is supervised by sparse, low-dimensional actions, leaving much of their representational power underutilized. To remedy this, we propose \textbf{DriveVLA-W0}, a training paradigm that employs world modeling to predict future images. This task generates a dense, self-supervised signal that compels the model to learn the underlying dynamics of the driving environment. We showcase the paradigm's versatility by instantiating it for two dominant VLA archetypes: an autoregressive world model for VLAs that use discrete visual tokens, and a diffusion world model for those operating on continuous visual features. Building on the rich representations learned from world modeling, we introduce a lightweight action expert to address the inference latency for real-time deployment. Extensive experiments on the NAVSIM v1/v2 benchmark and a 680x larger in-house dataset demonstrate that DriveVLA-W0 significantly outperforms BEV and VLA baselines. Crucially, it amplifies the data scaling law, showing that performance gains accelerate as the training dataset size increases.
WiFi-based Multi-task Sensing
Nov 26, 2021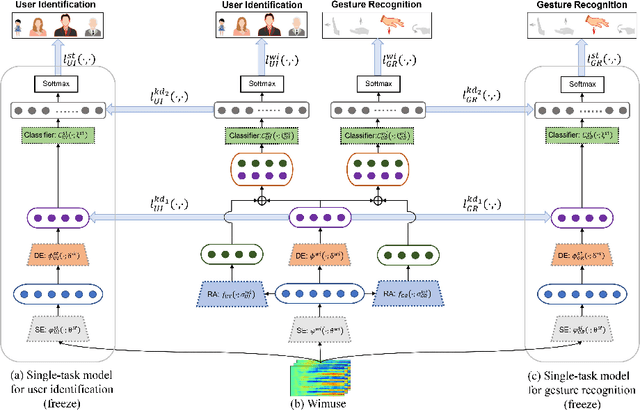
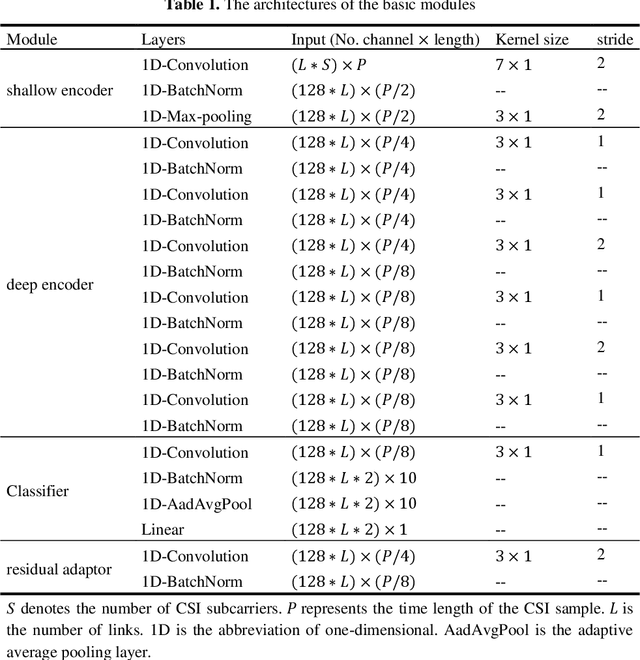
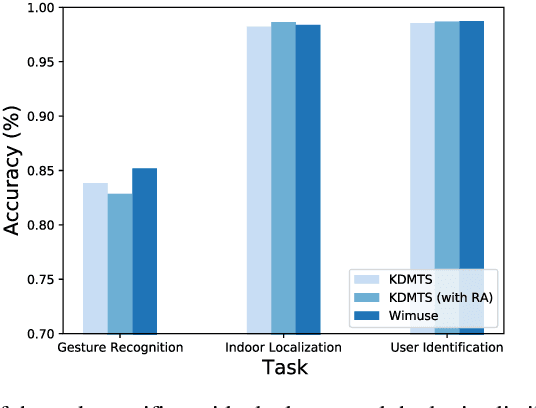
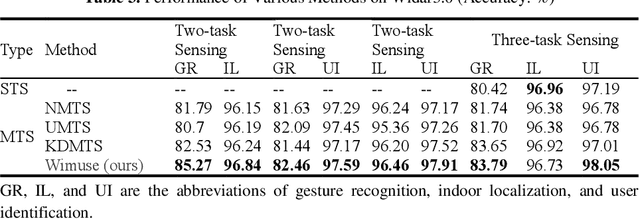
WiFi-based sensing has aroused immense attention over recent years. The rationale is that the signal fluctuations caused by humans carry the information of human behavior which can be extracted from the channel state information of WiFi. Still, the prior studies mainly focus on single-task sensing (STS), e.g., gesture recognition, indoor localization, user identification. Since the fluctuations caused by gestures are highly coupling with body features and the user's location, we propose a WiFi-based multi-task sensing model (Wimuse) to perform gesture recognition, indoor localization, and user identification tasks simultaneously. However, these tasks have different difficulty levels (i.e., imbalance issue) and need task-specific information (i.e., discrepancy issue). To address these issues, the knowledge distillation technique and task-specific residual adaptor are adopted in Wimuse. We first train the STS model for each task. Then, for solving the imbalance issue, the extracted common feature in Wimuse is encouraged to get close to the counterpart features of the STS models. Further, for each task, a task-specific residual adaptor is applied to extract the task-specific compensation feature which is fused with the common feature to address the discrepancy issue. We conduct comprehensive experiments on three public datasets and evaluation suggests that Wimuse achieves state-of-the-art performance with the average accuracy of 85.20%, 98.39%, and 98.725% on the joint task of gesture recognition, indoor localization, and user identification, respectively.