 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoCoGEC: Counterfactual Generation for Robust Grammatical Error Correction
Jun 13, 2026Grammatical error correction (GEC) systems are usually trained and evaluated on GEC benchmarks, but their performance often drops sharply once the surrounding context is slightly perturbed or extended. This indicates that the existing GEC models usually fail to understand the error patterns in the varying contexts. In this paper, we thoroughly investigate the counterfactuals for GEC tasks, where the subtle changes to the contexts could lead to the label flipping issue. We propose CoCoGEC, a counterfactual generation framework that creates copies of training instances with error-irrelevant contexts altered. Our framework systematically generates counterfactuals by (1) generating intra- and inter-sentence counterfactuals that maintain the error patterns as well as syntax of the original instances by altering the word-level and sentence-level contexts; (2) revising the generated counterfactuals by selecting the instances with flipped labels and high GEC Mutual Information (MI) coefficient. Extensive experiments show that our method substantially improves the stability of GEC models, outperforming a set of data augmentation baselines. Particularly, it could achieve absolute F0.5 gains of +9.9, +11.3, and +20.8 points on the perturbed BEA-19*,CoNLL-14*, and TEM-8* data set.Our code is released at https://github.com/Quinnok/CoCoGEC
EviProp: Seeded Relevance Diffusion on Chunk-Page Graphs for Long Multimodal Document Retrieval
Jun 08, 2026Retrieving evidence pages from visually rich long documents is a key challenge in document question answering. Existing page-level visual retrievers operate under an independent matching paradigm: each page is scored in isolation based on query-page similarity. This paradigm can under-rank evidence pages whose signals are localized in fine-grained chunks or depend on document-internal associations. We propose EviProp, a retrieval method that recovers such pages via seeded relevance diffusion. EviProp models each document as a multimodal Chunk-Page graph with hierarchical, sequential, and similarity links. Given a query, it combines dense visual page priors with sparse chunk seeds, then runs Personalized PageRank to diffuse relevance over the graph. Experiments on MMLongBench-Doc and LongDocURL show consistent gains in evidence-page retrieval over independent visual retrieval and text-visual fusion baselines. Downstream QA results further show that improved retrieval translates into better answer accuracy, with negligible online retrieval overhead. Our code is released at https://github.com/Flyecnu/EviProp.
Progress-SQL: Improving Reinforcement Learning for Text-to-SQL via Progressive Rewards
Jun 05, 2026Reinforcement learning has recently shown promise in improving large language models for Text-to-SQL generation, yet existing methods typically optimize one-shot rewards defined over a single SQL state. Such rewards provide limited guidance for iterative SQL correction and are insufficient to capture the improvement of multi-turn SQL refinement. In this paper, we propose Progress-SQL, a multi-turn reinforcement learning framework with progressive rewards for Text-to-SQL. Our approach introduces an Oracle-guided Diagnostic Tree (ODT), which abstracts SQL queries into clause-level structural profiles and produces diagnostic feedback for next-turn refinement. To provide dense and robust reward signals, we combine ODT-based structural alignment with lexical alignment and define a progressive reward that measures the improvement from the initial SQL to the final SQL. We further incorporate a progression latency reward that favors earlier correctness and an execution status reward that encourages recovery from the invalid SQL. Experiments on BIRD, Spider, and Spider robustness variants demonstrate that our method consistently improves Text-to-SQL performance across both primary and robustness evaluations.
IA-RAG: Interval-Algebra-Driven Temporal Reasoning for Dynamic Knowledge Retrieval
Jun 04, 2026Retrieval-Augmented Generation (RAG) has shown strong effectiveness in grounding Large Language Models (LLMs) with external knowledge. However, existing RAG and Graph RAG frameworks largely treat knowledge as static or associate time with coarse-grained timestamps or metadata, failing to capture rich temporal structures such as duration, overlap, and containment. We propose IA-RAG, a hierarchical temporal RAG framework that models knowledge as time intervals and performs retrieval under formal temporal constraints. IA-RAG represents facts as Interval Event Units (IEUs) and organizes them into a hierarchical Thematic Forest, where temporal dependencies are governed by Allen's Interval Algebra. To handle incomplete or uncertain temporal boundaries, IA-RAG further introduces a Sub-graph Time Tightening mechanism that refines fuzzy intervals through logical constraints within connected event subgraphs. In addition, IA-RAG supports implicit temporal semantic retrieval through interval-algebra-guided traversal. Experiments on multiple temporal question answering benchmarks, including TimeQA, TempReason, and ComplexTR, demonstrate that IA-RAG achieves strong temporal retrieval and reasoning performance, particularly on complex compositional temporal reasoning tasks. Our code is released at https://github.com/xiaoAugenstern/LogicalRAG_TemporalQA.
Scoring Edit Impact in Grammatical Error Correction via Embedded Association Graphs
Apr 08, 2026A Grammatical Error Correction (GEC) system produces a sequence of edits to correct an erroneous sentence. The quality of these edits is typically evaluated against human annotations. However, a sentence may admit multiple valid corrections, and existing evaluation settings do not fully accommodate diverse application scenarios. Recent meta-evaluation approaches rely on human judgments across multiple references, but they are difficult to scale to large datasets. In this paper, we propose a new task, Scoring Edit Impact in GEC, which aims to automatically estimate the importance of edits produced by a GEC system. To address this task, we introduce a scoring framework based on an embedded association graph. The graph captures latent dependencies among edits and syntactically related edits, grouping them into coherent groups. We then perform perplexity-based scoring to estimate each edit's contribution to sentence fluency. Experiments across 4 GEC datasets, 4 languages, and 4 GEC systems demonstrate that our method consistently outperforms a range of baselines. Further analysis shows that the embedded association graph effectively captures cross-linguistic structural dependencies among edits.
DynVLA: Learning World Dynamics for Action Reasoning in Autonomous Driving
Mar 11, 2026We propose DynVLA, a driving VLA model that introduces a new CoT paradigm termed Dynamics CoT. DynVLA forecasts compact world dynamics before action generation, enabling more informed and physically grounded decision-making. To obtain compact dynamics representations, DynVLA introduces a Dynamics Tokenizer that compresses future evolution into a small set of dynamics tokens. Considering the rich environment dynamics in interaction-intensive driving scenarios, DynVLA decouples ego-centric and environment-centric dynamics, yielding more accurate world dynamics modeling. We then train DynVLA to generate dynamics tokens before actions through SFT and RFT, improving decision quality while maintaining latency-efficient inference. Compared to Textual CoT, which lacks fine-grained spatiotemporal understanding, and Visual CoT, which introduces substantial redundancy due to dense image prediction, Dynamics CoT captures the evolution of the world in a compact, interpretable, and efficient form. Extensive experiments on NAVSIM, Bench2Drive, and a large-scale in-house dataset demonstrate that DynVLA consistently outperforms Textual CoT and Visual CoT methods, validating the effectiveness and practical value of Dynamics CoT.
Vision-DeepResearch Benchmark: Rethinking Visual and Textual Search for Multimodal Large Language Models
Feb 02, 2026Multimodal Large Language Models (MLLMs) have advanced VQA and now support Vision-DeepResearch systems that use search engines for complex visual-textual fact-finding. However, evaluating these visual and textual search abilities is still difficult, and existing benchmarks have two major limitations. First, existing benchmarks are not visual search-centric: answers that should require visual search are often leaked through cross-textual cues in the text questions or can be inferred from the prior world knowledge in current MLLMs. Second, overly idealized evaluation scenario: On the image-search side, the required information can often be obtained via near-exact matching against the full image, while the text-search side is overly direct and insufficiently challenging. To address these issues, we construct the Vision-DeepResearch benchmark (VDR-Bench) comprising 2,000 VQA instances. All questions are created via a careful, multi-stage curation pipeline and rigorous expert review, designed to assess the behavior of Vision-DeepResearch systems under realistic real-world conditions. Moreover, to address the insufficient visual retrieval capabilities of current MLLMs, we propose a simple multi-round cropped-search workflow. This strategy is shown to effectively improve model performance in realistic visual retrieval scenarios. Overall, our results provide practical guidance for the design of future multimodal deep-research systems. The code will be released in https://github.com/Osilly/Vision-DeepResearch.
DriveVLA-W0: World Models Amplify Data Scaling Law in Autonomous Driving
Oct 14, 2025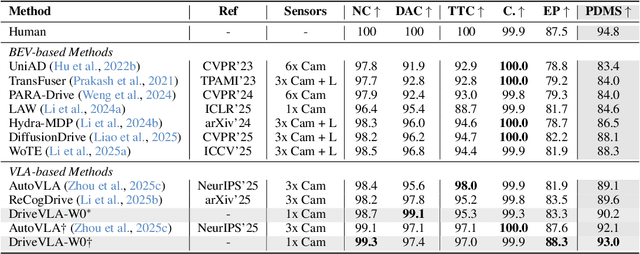
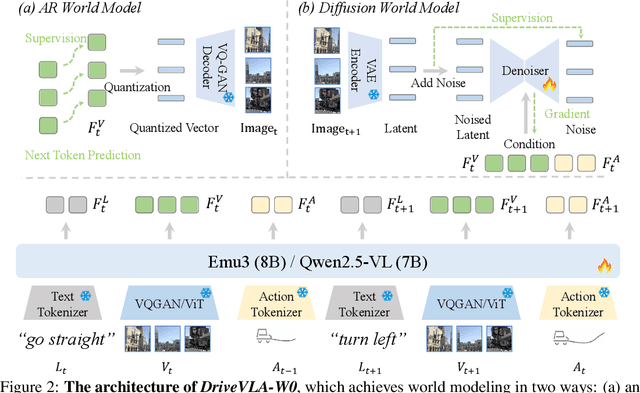

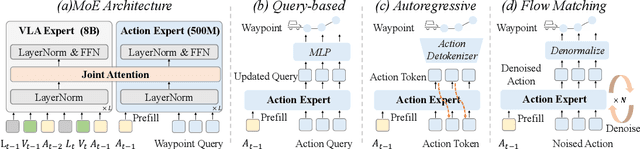
Scaling Vision-Language-Action (VLA) models on large-scale data offers a promising path to achieving a more generalized driving intelligence. However, VLA models are limited by a ``supervision deficit'': the vast model capacity is supervised by sparse, low-dimensional actions, leaving much of their representational power underutilized. To remedy this, we propose \textbf{DriveVLA-W0}, a training paradigm that employs world modeling to predict future images. This task generates a dense, self-supervised signal that compels the model to learn the underlying dynamics of the driving environment. We showcase the paradigm's versatility by instantiating it for two dominant VLA archetypes: an autoregressive world model for VLAs that use discrete visual tokens, and a diffusion world model for those operating on continuous visual features. Building on the rich representations learned from world modeling, we introduce a lightweight action expert to address the inference latency for real-time deployment. Extensive experiments on the NAVSIM v1/v2 benchmark and a 680x larger in-house dataset demonstrate that DriveVLA-W0 significantly outperforms BEV and VLA baselines. Crucially, it amplifies the data scaling law, showing that performance gains accelerate as the training dataset size increases.
Interleaving Reasoning for Better Text-to-Image Generation
Sep 09, 2025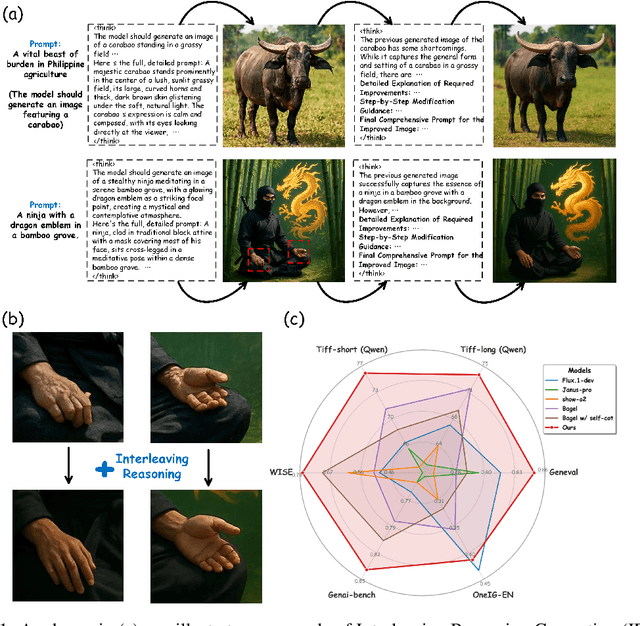
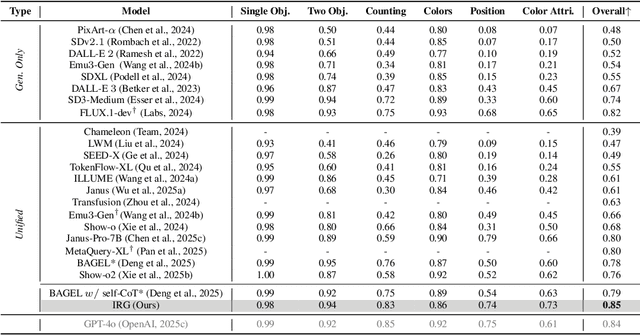

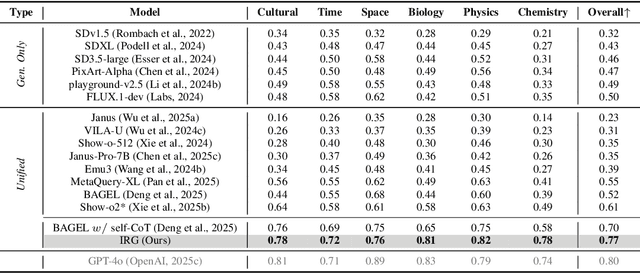
Unified multimodal understanding and generation models recently have achieve significant improvement in image generation capability, yet a large gap remains in instruction following and detail preservation compared to systems that tightly couple comprehension with generation such as GPT-4o. Motivated by recent advances in interleaving reasoning, we explore whether such reasoning can further improve Text-to-Image (T2I) generation. We introduce Interleaving Reasoning Generation (IRG), a framework that alternates between text-based thinking and image synthesis: the model first produces a text-based thinking to guide an initial image, then reflects on the result to refine fine-grained details, visual quality, and aesthetics while preserving semantics. To train IRG effectively, we propose Interleaving Reasoning Generation Learning (IRGL), which targets two sub-goals: (1) strengthening the initial think-and-generate stage to establish core content and base quality, and (2) enabling high-quality textual reflection and faithful implementation of those refinements in a subsequent image. We curate IRGL-300K, a dataset organized into six decomposed learning modes that jointly cover learning text-based thinking, and full thinking-image trajectories. Starting from a unified foundation model that natively emits interleaved text-image outputs, our two-stage training first builds robust thinking and reflection, then efficiently tunes the IRG pipeline in the full thinking-image trajectory data. Extensive experiments show SoTA performance, yielding absolute gains of 5-10 points on GenEval, WISE, TIIF, GenAI-Bench, and OneIG-EN, alongside substantial improvements in visual quality and fine-grained fidelity. The code, model weights and datasets will be released in: https://github.com/Osilly/Interleaving-Reasoning-Generation .
LeanRAG: Knowledge-Graph-Based Generation with Semantic Aggregation and Hierarchical Retrieval
Aug 14, 2025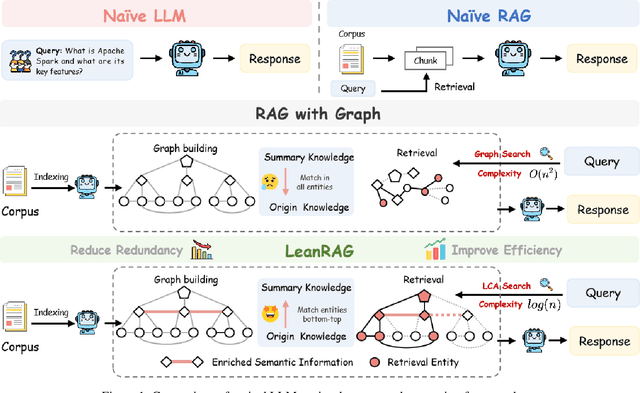
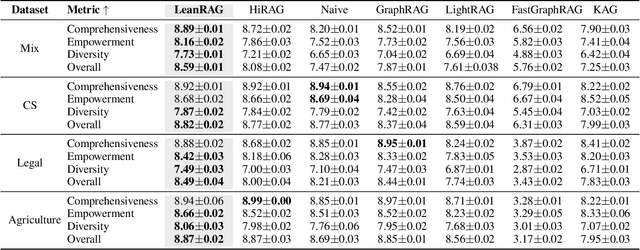
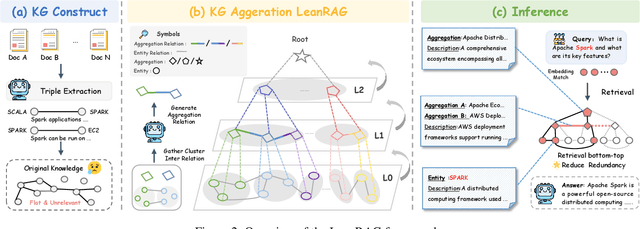

Retrieval-Augmented Generation (RAG) plays a crucial role in grounding Large Language Models by leveraging external knowledge, whereas the effectiveness is often compromised by the retrieval of contextually flawed or incomplete information. To address this, knowledge graph-based RAG methods have evolved towards hierarchical structures, organizing knowledge into multi-level summaries. However, these approaches still suffer from two critical, unaddressed challenges: high-level conceptual summaries exist as disconnected ``semantic islands'', lacking the explicit relations needed for cross-community reasoning; and the retrieval process itself remains structurally unaware, often degenerating into an inefficient flat search that fails to exploit the graph's rich topology. To overcome these limitations, we introduce LeanRAG, a framework that features a deeply collaborative design combining knowledge aggregation and retrieval strategies. LeanRAG first employs a novel semantic aggregation algorithm that forms entity clusters and constructs new explicit relations among aggregation-level summaries, creating a fully navigable semantic network. Then, a bottom-up, structure-guided retrieval strategy anchors queries to the most relevant fine-grained entities and then systematically traverses the graph's semantic pathways to gather concise yet contextually comprehensive evidence sets. The LeanRAG can mitigate the substantial overhead associated with path retrieval on graphs and minimizes redundant information retrieval. Extensive experiments on four challenging QA benchmarks with different domains demonstrate that LeanRAG significantly outperforming existing methods in response quality while reducing 46\% retrieval redundancy. Code is available at: https://github.com/RaZzzyz/LeanRAG