 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDriveFuture: Future-Aware Latent World Models for Autonomous Driving
May 10, 2026Existing latent world models for autonomous driving have opened a promising path toward future-aware driving intelligence. However, they typically treat future latent states as prediction targets or auxiliary signals, rather than directly conditioning trajectory planning. This can entangle current and future features in latent space. In this work, we propose DriveFuture, a future-aware latent world modeling framework for autonomous driving that explicitly learns planning-oriented foresight by conditioning the current latent state modeling process on future world states. Specifically, during training, the model first predicts future latent world states from the current latent state and ego action, and then refines the prediction against the ground-truth future latent state via cross-attention. The resulting future-aware latent serves as an explicit condition for a diffusion-based trajectory planner. During inference, DriveFuture conditions on the predicted future latent state instead of the ground-truth future state. DriveFuture achieves SOTA performance on the public NAVSIM benchmarks, reaching \textbf{55.5} EPDMS on NAVSIM-v2 {\textcolor{blue}{\textit{navhard}}}, \textbf{89.9} EPDMS on NAVSIM-v2 {\textcolor{blue}{\textit{navtest}}}, and \textbf{90.7} PDMS on NAVSIM-v1 {\textcolor{blue}{\textit{navtest}}}, respectively. These results suggest that the key to latent world modeling lies not merely in simulating future states, but more importantly in conditioning current decision-making on future states. Notably, as of April 2026, DriveFuture ranks \textbf{1st} on the \href{https://huggingface.co/spaces/AGC2025/e2e-driving-navhard}{NAVSIM-v2 {\textcolor{blue}{\textit{navhard}}}} leaderboard and achieves SOTA performance on \href{https://huggingface.co/spaces/AGC2024-P/e2e-driving-navtest}{NAVSIM-v1 {\textcolor{blue}{\textit{navtest}}}}.
OneVL: One-Step Latent Reasoning and Planning with Vision-Language Explanation
Apr 20, 2026Chain-of-Thought (CoT) reasoning has become a powerful driver of trajectory prediction in VLA-based autonomous driving, yet its autoregressive nature imposes a latency cost that is prohibitive for real-time deployment. Latent CoT methods attempt to close this gap by compressing reasoning into continuous hidden states, but consistently fall short of their explicit counterparts. We suggest that this is due to purely linguistic latent representations compressing a symbolic abstraction of the world, rather than the causal dynamics that actually govern driving. Thus, we present OneVL (One-step latent reasoning and planning with Vision-Language explanations), a unified VLA and World Model framework that routes reasoning through compact latent tokens supervised by dual auxiliary decoders. Alongside a language decoder that reconstructs text CoT, we introduce a visual world model decoder that predicts future-frame tokens, forcing the latent space to internalize the causal dynamics of road geometry, agent motion, and environmental change. A three-stage training pipeline progressively aligns these latents with trajectory, language, and visual objectives, ensuring stable joint optimization. At inference, the auxiliary decoders are discarded and all latent tokens are prefilled in a single parallel pass, matching the speed of answer-only prediction. Across four benchmarks, OneVL becomes the first latent CoT method to surpass explicit CoT, delivering state-of-the-art accuracy at answer-only latency, and providing direct evidence that tighter compression, when guided in both language and world-model supervision, produces more generalizable representations than verbose token-by-token reasoning. Project Page: https://xiaomi-embodied-intelligence.github.io/OneVL
DynVLA: Learning World Dynamics for Action Reasoning in Autonomous Driving
Mar 11, 2026We propose DynVLA, a driving VLA model that introduces a new CoT paradigm termed Dynamics CoT. DynVLA forecasts compact world dynamics before action generation, enabling more informed and physically grounded decision-making. To obtain compact dynamics representations, DynVLA introduces a Dynamics Tokenizer that compresses future evolution into a small set of dynamics tokens. Considering the rich environment dynamics in interaction-intensive driving scenarios, DynVLA decouples ego-centric and environment-centric dynamics, yielding more accurate world dynamics modeling. We then train DynVLA to generate dynamics tokens before actions through SFT and RFT, improving decision quality while maintaining latency-efficient inference. Compared to Textual CoT, which lacks fine-grained spatiotemporal understanding, and Visual CoT, which introduces substantial redundancy due to dense image prediction, Dynamics CoT captures the evolution of the world in a compact, interpretable, and efficient form. Extensive experiments on NAVSIM, Bench2Drive, and a large-scale in-house dataset demonstrate that DynVLA consistently outperforms Textual CoT and Visual CoT methods, validating the effectiveness and practical value of Dynamics CoT.
Training Report of TeleChat3-MoE
Dec 30, 2025TeleChat3-MoE is the latest series of TeleChat large language models, featuring a Mixture-of-Experts (MoE) architecture with parameter counts ranging from 105 billion to over one trillion,trained end-to-end on Ascend NPU cluster. This technical report mainly presents the underlying training infrastructure that enables reliable and efficient scaling to frontier model sizes. We detail systematic methodologies for operator-level and end-to-end numerical accuracy verification, ensuring consistency across hardware platforms and distributed parallelism strategies. Furthermore, we introduce a suite of performance optimizations, including interleaved pipeline scheduling, attention-aware data scheduling for long-sequence training,hierarchical and overlapped communication for expert parallelism, and DVM-based operator fusion. A systematic parallelization framework, leveraging analytical estimation and integer linear programming, is also proposed to optimize multi-dimensional parallelism configurations. Additionally, we present methodological approaches to cluster-level optimizations, addressing host- and device-bound bottlenecks during large-scale training tasks. These infrastructure advancements yield significant throughput improvements and near-linear scaling on clusters comprising thousands of devices, providing a robust foundation for large-scale language model development on hardware ecosystems.
DriveVLA-W0: World Models Amplify Data Scaling Law in Autonomous Driving
Oct 14, 2025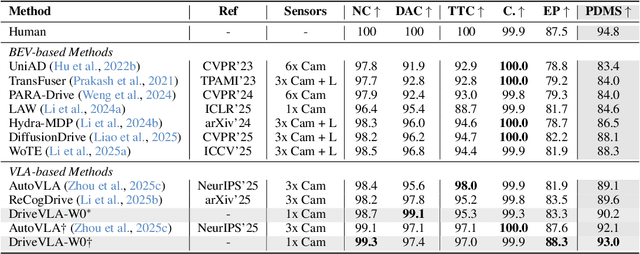
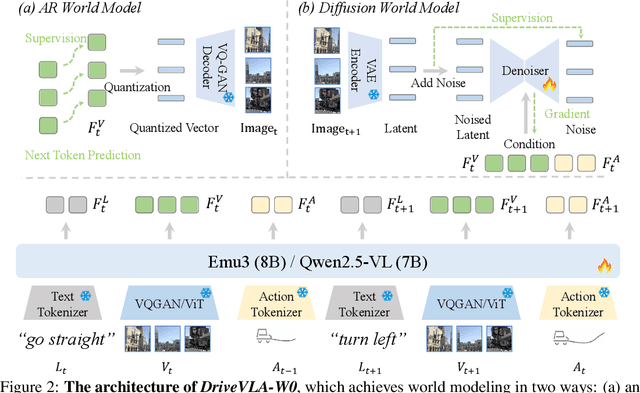

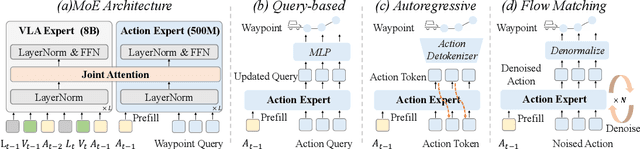
Scaling Vision-Language-Action (VLA) models on large-scale data offers a promising path to achieving a more generalized driving intelligence. However, VLA models are limited by a ``supervision deficit'': the vast model capacity is supervised by sparse, low-dimensional actions, leaving much of their representational power underutilized. To remedy this, we propose \textbf{DriveVLA-W0}, a training paradigm that employs world modeling to predict future images. This task generates a dense, self-supervised signal that compels the model to learn the underlying dynamics of the driving environment. We showcase the paradigm's versatility by instantiating it for two dominant VLA archetypes: an autoregressive world model for VLAs that use discrete visual tokens, and a diffusion world model for those operating on continuous visual features. Building on the rich representations learned from world modeling, we introduce a lightweight action expert to address the inference latency for real-time deployment. Extensive experiments on the NAVSIM v1/v2 benchmark and a 680x larger in-house dataset demonstrate that DriveVLA-W0 significantly outperforms BEV and VLA baselines. Crucially, it amplifies the data scaling law, showing that performance gains accelerate as the training dataset size increases.
Unified Vision-Language-Action Model
Jun 24, 2025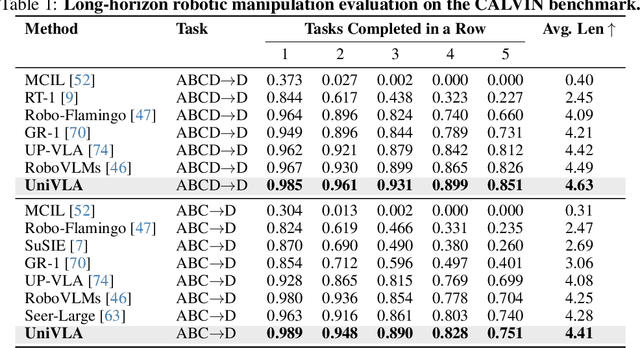
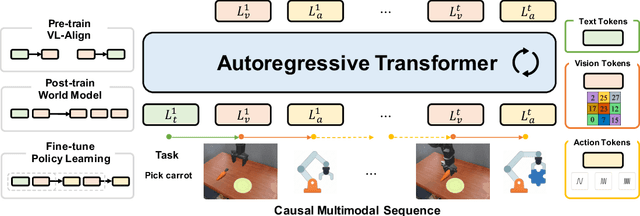
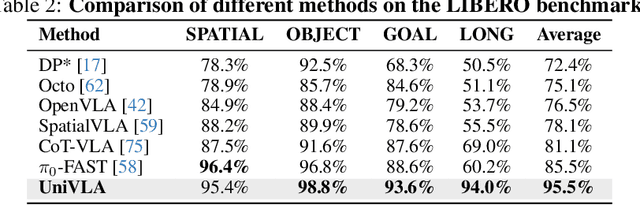
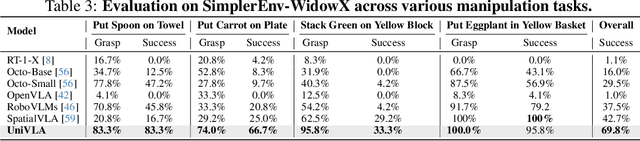
Vision-language-action models (VLAs) have garnered significant attention for their potential in advancing robotic manipulation. However, previous approaches predominantly rely on the general comprehension capabilities of vision-language models (VLMs) to generate action signals, often overlooking the rich temporal and causal structure embedded in visual observations. In this paper, we present UniVLA, a unified and native multimodal VLA model that autoregressively models vision, language, and action signals as discrete token sequences. This formulation enables flexible multimodal tasks learning, particularly from large-scale video data. By incorporating world modeling during post-training, UniVLA captures causal dynamics from videos, facilitating effective transfer to downstream policy learning--especially for long-horizon tasks. Our approach sets new state-of-the-art results across several widely used simulation benchmarks, including CALVIN, LIBERO, and Simplenv-Bridge, significantly surpassing previous methods. For example, UniVLA achieves 95.5% average success rate on LIBERO benchmark, surpassing pi0-FAST's 85.5%. We further demonstrate its broad applicability on real-world ALOHA manipulation and autonomous driving.
TC-Light: Temporally Consistent Relighting for Dynamic Long Videos
Jun 23, 2025Editing illumination in long videos with complex dynamics has significant value in various downstream tasks, including visual content creation and manipulation, as well as data scaling up for embodied AI through sim2real and real2real transfer. Nevertheless, existing video relighting techniques are predominantly limited to portrait videos or fall into the bottleneck of temporal consistency and computation efficiency. In this paper, we propose TC-Light, a novel paradigm characterized by the proposed two-stage post optimization mechanism. Starting from the video preliminarily relighted by an inflated video relighting model, it optimizes appearance embedding in the first stage to align global illumination. Then it optimizes the proposed canonical video representation, i.e., Unique Video Tensor (UVT), to align fine-grained texture and lighting in the second stage. To comprehensively evaluate performance, we also establish a long and highly dynamic video benchmark. Extensive experiments show that our method enables physically plausible relighting results with superior temporal coherence and low computation cost. The code and video demos are available at https://dekuliutesla.github.io/tclight/.
End-to-End Driving with Online Trajectory Evaluation via BEV World Model
Apr 02, 2025End-to-end autonomous driving has achieved remarkable progress by integrating perception, prediction, and planning into a fully differentiable framework. Yet, to fully realize its potential, an effective online trajectory evaluation is indispensable to ensure safety. By forecasting the future outcomes of a given trajectory, trajectory evaluation becomes much more effective. This goal can be achieved by employing a world model to capture environmental dynamics and predict future states. Therefore, we propose an end-to-end driving framework WoTE, which leverages a BEV World model to predict future BEV states for Trajectory Evaluation. The proposed BEV world model is latency-efficient compared to image-level world models and can be seamlessly supervised using off-the-shelf BEV-space traffic simulators. We validate our framework on both the NAVSIM benchmark and the closed-loop Bench2Drive benchmark based on the CARLA simulator, achieving state-of-the-art performance. Code is released at https://github.com/liyingyanUCAS/WoTE.
Enhancing End-to-End Autonomous Driving with Latent World Model
Jun 12, 2024



End-to-end autonomous driving has garnered widespread attention. Current end-to-end approaches largely rely on the supervision from perception tasks such as detection, tracking, and map segmentation to aid in learning scene representations. However, these methods require extensive annotations, hindering the data scalability. To address this challenge, we propose a novel self-supervised method to enhance end-to-end driving without the need for costly labels. Specifically, our framework \textbf{LAW} uses a LAtent World model to predict future latent features based on the predicted ego actions and the latent feature of the current frame. The predicted latent features are supervised by the actually observed features in the future. This supervision jointly optimizes the latent feature learning and action prediction, which greatly enhances the driving performance. As a result, our approach achieves state-of-the-art performance in both open-loop and closed-loop benchmarks without costly annotations.
Fully Sparse Fusion for 3D Object Detection
Apr 25, 2023



Currently prevalent multimodal 3D detection methods are built upon LiDAR-based detectors that usually use dense Bird's-Eye-View (BEV) feature maps. However, the cost of such BEV feature maps is quadratic to the detection range, making it not suitable for long-range detection. Fully sparse architecture is gaining attention as they are highly efficient in long-range perception. In this paper, we study how to effectively leverage image modality in the emerging fully sparse architecture. Particularly, utilizing instance queries, our framework integrates the well-studied 2D instance segmentation into the LiDAR side, which is parallel to the 3D instance segmentation part in the fully sparse detector. This design achieves a uniform query-based fusion framework in both the 2D and 3D sides while maintaining the fully sparse characteristic. Extensive experiments showcase state-of-the-art results on the widely used nuScenes dataset and the long-range Argoverse 2 dataset. Notably, the inference speed of the proposed method under the long-range LiDAR perception setting is 2.7 $\times$ faster than that of other state-of-the-art multimodal 3D detection methods. Code will be released at \url{https://github.com/BraveGroup/FullySparseFusion}.