 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWatch, Remember, Reason: Human-View Video Understanding with MLLMs
Jun 05, 2026Video understanding is being rapidly transformed by multimodal large language models (MLLMs), as research moves from short clips to long, multimodal, and knowledge-intensive video scenarios. These scenarios require models to handle sparse evidence, long-range dependencies, multimodal alignment, and reliable inference under limited computational budgets. This work presents a human-view perspective on LLM-based video understanding, organized around three functional abilities: watching, remembering, and reasoning. Rather than treating video tasks as isolated benchmarks, this view provides a unified structure for analyzing how video MLLMs acquire evidence, preserve context, and produce grounded outputs. We introduce a formulation that characterizes video understanding systems by their perceptual representations, memory states, reasoning traces, and final predictions. Based on this formulation, we identify challenges in spatio-temporal perception, efficient long-video processing, memory modeling, streaming understanding, and faithful reasoning. Representative methods are organized by their roles in video MLLM systems. Watching covers fine-grained, comprehensive, audio-visual, and efficient perception. Remembering includes offline and streaming memory, while reasoning covers text-only reasoning and thinking with videos. We further examine application domains such as egocentric, sports, instructional, medical, and narrative videos, and cover training datasets and evaluation benchmarks across task types, supervision formats, modalities, and capability dimensions. Finally, we outline open problems and future directions for scalable, memory-aware, and evidence-grounded video intelligence. Related works will be continuously traced at https://github.com/marinero4972/Awesome-HumanView-VideoUnderstanding.
Towards One-to-Many Temporal Grounding
Jun 04, 2026Temporal Grounding (TG) aims to localize video segments corresponding to a textual query. Prior research predominantly focuses on single-segment retrieval. Real-world scenarios, however, often require localizing multiple disjoint segments for a single query -- a setting we term One-to-Many Temporal Grounding (OMTG). Previous state-of-the-art MLLMs, optimized for one-to-one settings, struggle in this context, often yielding near-zero scores due to a lack of event cardinality perception. To bridge this gap, we present a systematic solution with three key contributions. First, we establish the first comprehensive OMTG benchmark, introducing Count Accuracy (C-Acc) and Effective Temporal F1 (EtF1) as evaluation metrics. Second, we curate a high-quality OMTG dataset comprising 56k samples through a sophisticated construction pipeline. Third, we develop novel temporal and caption reward functions specifically designed for OMTG. In particular, the caption reward leverages Chain-of-Thought reasoning over dense video captions to explicitly guide policy optimization toward both preciseness and completeness. Extensive experiments show our model achieves a new state-of-the-art EtF1 of 43.65\% on OMTG Bench, outperforming Gemini 2.5 Pro and Seed-1.8 by 15.85\% and 15.61\%, respectively.
VideoZeroBench: Probing the Limits of Video MLLMs with Spatio-Temporal Evidence Verification
Apr 02, 2026Recent video multimodal large language models achieve impressive results across various benchmarks. However, current evaluations suffer from two critical limitations: (1) inflated scores can mask deficiencies in fine-grained visual understanding and reasoning, and (2) answer correctness is often measured without verifying whether models identify the precise spatio-temporal evidence supporting their predictions. To address this, we present VideoZeroBench, a hierarchical benchmark designed for challenging long-video question answering that rigorously verifies spatio-temporal evidence. It comprises 500 manually annotated questions across 13 domains, paired with temporal intervals and spatial bounding boxes as evidence. To disentangle answering generation, temporal grounding, and spatial grounding, we introduce a five-level evaluation protocol that progressively tightens evidence requirements. Experiments show that even Gemini-3-Pro correctly answers fewer than 17% of questions under the standard end-to-end QA setting (Level-3). When grounding constraints are imposed, performance drops sharply: No model exceeds 1% accuracy when both correct answering and accurate spatio-temporal localization are required (Level-5), with most failing to achieve any correct grounded predictions. These results expose a significant gap between surface-level answer correctness and genuine evidence-based reasoning, revealing that grounded video understanding remains a bottleneck for long-video QA. We further analyze performance across minimal evidence spans, atomic abilities, and inference paradigms, providing insights for future research in grounded video reasoning. The benchmark and code will be made publicly available.
Open-o3 Video: Grounded Video Reasoning with Explicit Spatio-Temporal Evidence
Oct 23, 2025Most video reasoning models only generate textual reasoning traces without indicating when and where key evidence appears. Recent models such as OpenAI-o3 have sparked wide interest in evidence-centered reasoning for images, yet extending this ability to videos is more challenging, as it requires joint temporal tracking and spatial localization across dynamic scenes. We introduce Open-o3 Video, a non-agent framework that integrates explicit spatio-temporal evidence into video reasoning, and carefully collect training data and design training strategies to address the aforementioned challenges. The model highlights key timestamps, objects, and bounding boxes alongside its answers, allowing reasoning to be grounded in concrete visual observations. To enable this functionality, we first curate and build two high-quality datasets, STGR-CoT-30k for SFT and STGR-RL-36k for RL, with carefully constructed temporal and spatial annotations, since most existing datasets offer either temporal spans for videos or spatial boxes on images, lacking unified spatio-temporal supervision and reasoning traces. Then, we adopt a cold-start reinforcement learning strategy with multiple specially designed rewards that jointly encourage answer accuracy, temporal alignment, and spatial precision. On V-STAR benchmark, Open-o3 Video achieves state-of-the-art performance, raising mAM by 14.4% and mLGM by 24.2% on the Qwen2.5-VL baseline. Consistent improvements are also observed on a broad range of video understanding benchmarks, including VideoMME, WorldSense, VideoMMMU, and TVGBench. Beyond accuracy, the reasoning traces produced by Open-o3 Video also provide valuable signals for test-time scaling, enabling confidence-aware verification and improving answer reliability.
Grasp Any Region: Towards Precise, Contextual Pixel Understanding for Multimodal LLMs
Oct 22, 2025While Multimodal Large Language Models (MLLMs) excel at holistic understanding, they struggle in capturing the dense world with complex scenes, requiring fine-grained analysis of intricate details and object inter-relationships. Region-level MLLMs have been a promising step. However, previous attempts are generally optimized to understand given regions in isolation, neglecting crucial global contexts. To address this, we introduce Grasp Any Region (GAR) for comprehen- sive region-level visual understanding. Empowered by an effective RoI-aligned feature replay technique, GAR supports (1) precise perception by leveraging necessary global contexts, and (2) modeling interactions between multiple prompts. Together, it then naturally achieves (3) advanced compositional reasoning to answer specific free-form questions about any region, shifting the paradigm from passive description to active dialogue. Moreover, we construct GAR-Bench, which not only provides a more accurate evaluation of single-region comprehension, but also, more importantly, measures interactions and complex reasoning across multiple regions. Extensive experiments have demonstrated that GAR-1B not only maintains the state-of-the-art captioning capabilities, e.g., outperforming DAM-3B +4.5 on DLC-Bench, but also excels at modeling relationships between multiple prompts with advanced comprehension capabilities, even surpassing InternVL3-78B on GAR-Bench-VQA. More importantly, our zero-shot GAR-8B even outperforms in-domain VideoRefer-7B on VideoRefer-BenchQ, indicating its strong capabilities can be easily transferred to videos.
CyberV: Cybernetics for Test-time Scaling in Video Understanding
Jun 09, 2025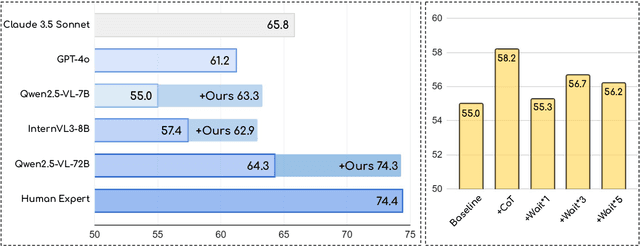
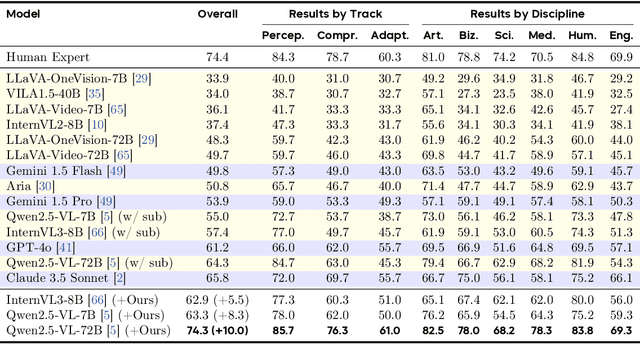
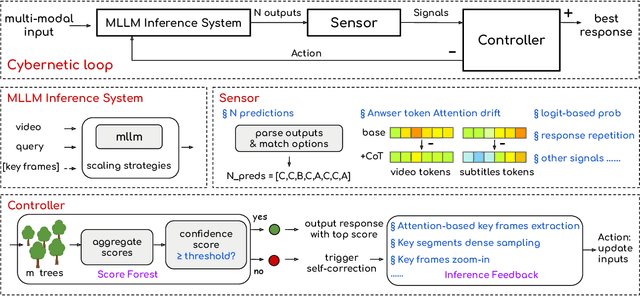
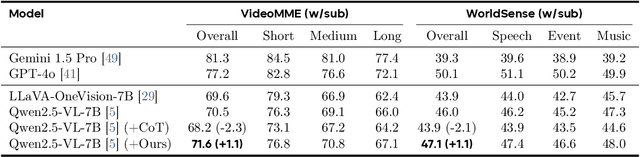
Current Multimodal Large Language Models (MLLMs) may struggle with understanding long or complex videos due to computational demands at test time, lack of robustness, and limited accuracy, primarily stemming from their feed-forward processing nature. These limitations could be more severe for models with fewer parameters. To address these limitations, we propose a novel framework inspired by cybernetic principles, redesigning video MLLMs as adaptive systems capable of self-monitoring, self-correction, and dynamic resource allocation during inference. Our approach, CyberV, introduces a cybernetic loop consisting of an MLLM Inference System, a Sensor, and a Controller. Specifically, the sensor monitors forward processes of the MLLM and collects intermediate interpretations, such as attention drift, then the controller determines when and how to trigger self-correction and generate feedback to guide the next round. This test-time adaptive scaling framework enhances frozen MLLMs without requiring retraining or additional components. Experiments demonstrate significant improvements: CyberV boosts Qwen2.5-VL-7B by 8.3% and InternVL3-8B by 5.5% on VideoMMMU, surpassing the competitive proprietary model GPT-4o. When applied to Qwen2.5-VL-72B, it yields a 10.0% improvement, achieving performance even comparable to human experts. Furthermore, our method demonstrates consistent gains on general-purpose benchmarks, such as VideoMME and WorldSense, highlighting its effectiveness and generalization capabilities in making MLLMs more robust and accurate for dynamic video understanding. The code is released at https://github.com/marinero4972/CyberV.
On Path to Multimodal Generalist: General-Level and General-Bench
May 07, 2025The Multimodal Large Language Model (MLLM) is currently experiencing rapid growth, driven by the advanced capabilities of LLMs. Unlike earlier specialists, existing MLLMs are evolving towards a Multimodal Generalist paradigm. Initially limited to understanding multiple modalities, these models have advanced to not only comprehend but also generate across modalities. Their capabilities have expanded from coarse-grained to fine-grained multimodal understanding and from supporting limited modalities to arbitrary ones. While many benchmarks exist to assess MLLMs, a critical question arises: Can we simply assume that higher performance across tasks indicates a stronger MLLM capability, bringing us closer to human-level AI? We argue that the answer is not as straightforward as it seems. This project introduces General-Level, an evaluation framework that defines 5-scale levels of MLLM performance and generality, offering a methodology to compare MLLMs and gauge the progress of existing systems towards more robust multimodal generalists and, ultimately, towards AGI. At the core of the framework is the concept of Synergy, which measures whether models maintain consistent capabilities across comprehension and generation, and across multiple modalities. To support this evaluation, we present General-Bench, which encompasses a broader spectrum of skills, modalities, formats, and capabilities, including over 700 tasks and 325,800 instances. The evaluation results that involve over 100 existing state-of-the-art MLLMs uncover the capability rankings of generalists, highlighting the challenges in reaching genuine AI. We expect this project to pave the way for future research on next-generation multimodal foundation models, providing a robust infrastructure to accelerate the realization of AGI. Project page: https://generalist.top/
You Can't Ignore Either: Unifying Structure and Feature Denoising for Robust Graph Learning
Aug 01, 2024Recent research on the robustness of Graph Neural Networks (GNNs) under noises or attacks has attracted great attention due to its importance in real-world applications. Most previous methods explore a single noise source, recovering corrupt node embedding by reliable structures bias or developing structure learning with reliable node features. However, the noises and attacks may come from both structures and features in graphs, making the graph denoising a dilemma and challenging problem. In this paper, we develop a unified graph denoising (UGD) framework to unravel the deadlock between structure and feature denoising. Specifically, a high-order neighborhood proximity evaluation method is proposed to recognize noisy edges, considering features may be perturbed simultaneously. Moreover, we propose to refine noisy features with reconstruction based on a graph auto-encoder. An iterative updating algorithm is further designed to optimize the framework and acquire a clean graph, thus enabling robust graph learning for downstream tasks. Our UGD framework is self-supervised and can be easily implemented as a plug-and-play module. We carry out extensive experiments, which proves the effectiveness and advantages of our method. Code is avalaible at https://github.com/YoungTimmy/UGD.
SEFraud: Graph-based Self-Explainable Fraud Detection via Interpretative Mask Learning
Jun 17, 2024



Graph-based fraud detection has widespread application in modern industry scenarios, such as spam review and malicious account detection. While considerable efforts have been devoted to designing adequate fraud detectors, the interpretability of their results has often been overlooked. Previous works have attempted to generate explanations for specific instances using post-hoc explaining methods such as a GNNExplainer. However, post-hoc explanations can not facilitate the model predictions and the computational cost of these methods cannot meet practical requirements, thus limiting their application in real-world scenarios. To address these issues, we propose SEFraud, a novel graph-based self-explainable fraud detection framework that simultaneously tackles fraud detection and result in interpretability. Concretely, SEFraud first leverages customized heterogeneous graph transformer networks with learnable feature masks and edge masks to learn expressive representations from the informative heterogeneously typed transactions. A new triplet loss is further designed to enhance the performance of mask learning. Empirical results on various datasets demonstrate the effectiveness of SEFraud as it shows considerable advantages in both the fraud detection performance and interpretability of prediction results. Moreover, SEFraud has been deployed and offers explainable fraud detection service for the largest bank in China, Industrial and Commercial Bank of China Limited (ICBC). Results collected from the production environment of ICBC show that SEFraud can provide accurate detection results and comprehensive explanations that align with the expert business understanding, confirming its efficiency and applicability in large-scale online services.