 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffVSR: Enhancing Real-World Video Super-Resolution with Diffusion Models for Advanced Visual Quality and Temporal Consistency
Jan 17, 2025
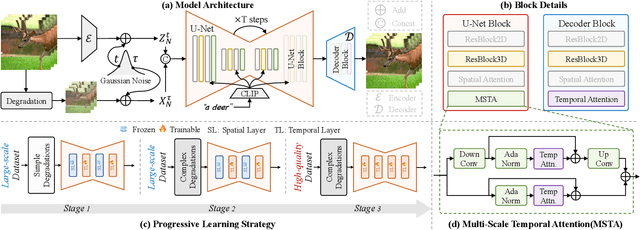
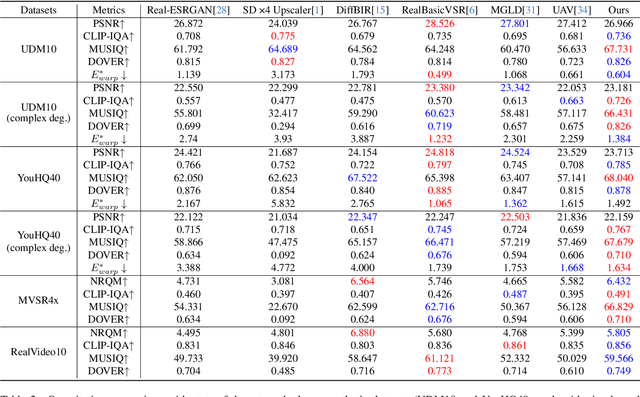
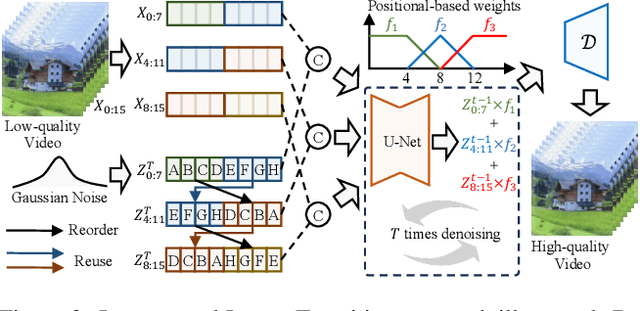
Diffusion models have demonstrated exceptional capabilities in image generation and restoration, yet their application to video super-resolution faces significant challenges in maintaining both high fidelity and temporal consistency. We present DiffVSR, a diffusion-based framework for real-world video super-resolution that effectively addresses these challenges through key innovations. For intra-sequence coherence, we develop a multi-scale temporal attention module and temporal-enhanced VAE decoder that capture fine-grained motion details. To ensure inter-sequence stability, we introduce a noise rescheduling mechanism with an interweaved latent transition approach, which enhances temporal consistency without additional training overhead. We propose a progressive learning strategy that transitions from simple to complex degradations, enabling robust optimization despite limited high-quality video data. Extensive experiments demonstrate that DiffVSR delivers superior results in both visual quality and temporal consistency, setting a new performance standard in real-world video super-resolution.
RepVideo: Rethinking Cross-Layer Representation for Video Generation
Jan 15, 2025



Video generation has achieved remarkable progress with the introduction of diffusion models, which have significantly improved the quality of generated videos. However, recent research has primarily focused on scaling up model training, while offering limited insights into the direct impact of representations on the video generation process. In this paper, we initially investigate the characteristics of features in intermediate layers, finding substantial variations in attention maps across different layers. These variations lead to unstable semantic representations and contribute to cumulative differences between features, which ultimately reduce the similarity between adjacent frames and negatively affect temporal coherence. To address this, we propose RepVideo, an enhanced representation framework for text-to-video diffusion models. By accumulating features from neighboring layers to form enriched representations, this approach captures more stable semantic information. These enhanced representations are then used as inputs to the attention mechanism, thereby improving semantic expressiveness while ensuring feature consistency across adjacent frames. Extensive experiments demonstrate that our RepVideo not only significantly enhances the ability to generate accurate spatial appearances, such as capturing complex spatial relationships between multiple objects, but also improves temporal consistency in video generation.
Mitigating Domain Shift in Federated Learning via Intra- and Inter-Domain Prototypes
Jan 15, 2025



Federated Learning (FL) has emerged as a decentralized machine learning technique, allowing clients to train a global model collaboratively without sharing private data. However, most FL studies ignore the crucial challenge of heterogeneous domains where each client has a distinct feature distribution, which is common in real-world scenarios. Prototype learning, which leverages the mean feature vectors within the same classes, has become a prominent solution for federated learning under domain skew. However, existing federated prototype learning methods only consider inter-domain prototypes on the server and overlook intra-domain characteristics. In this work, we introduce a novel federated prototype learning method, namely I$^2$PFL, which incorporates $\textbf{I}$ntra-domain and $\textbf{I}$nter-domain $\textbf{P}$rototypes, to mitigate domain shifts and learn a generalized global model across multiple domains in federated learning. To construct intra-domain prototypes, we propose feature alignment with MixUp-based augmented prototypes to capture the diversity of local domains and enhance the generalization of local features. Additionally, we introduce a reweighting mechanism for inter-domain prototypes to generate generalized prototypes to provide inter-domain knowledge and reduce domain skew across multiple clients. Extensive experiments on the Digits, Office-10, and PACS datasets illustrate the superior performance of our method compared to other baselines.
Vchitect-2.0: Parallel Transformer for Scaling Up Video Diffusion Models
Jan 14, 2025



We present Vchitect-2.0, a parallel transformer architecture designed to scale up video diffusion models for large-scale text-to-video generation. The overall Vchitect-2.0 system has several key designs. (1) By introducing a novel Multimodal Diffusion Block, our approach achieves consistent alignment between text descriptions and generated video frames, while maintaining temporal coherence across sequences. (2) To overcome memory and computational bottlenecks, we propose a Memory-efficient Training framework that incorporates hybrid parallelism and other memory reduction techniques, enabling efficient training of long video sequences on distributed systems. (3) Additionally, our enhanced data processing pipeline ensures the creation of Vchitect T2V DataVerse, a high-quality million-scale training dataset through rigorous annotation and aesthetic evaluation. Extensive benchmarking demonstrates that Vchitect-2.0 outperforms existing methods in video quality, training efficiency, and scalability, serving as a suitable base for high-fidelity video generation.
Parameter-Inverted Image Pyramid Networks for Visual Perception and Multimodal Understanding
Jan 14, 2025Image pyramids are widely adopted in top-performing methods to obtain multi-scale features for precise visual perception and understanding. However, current image pyramids use the same large-scale model to process multiple resolutions of images, leading to significant computational cost. To address this challenge, we propose a novel network architecture, called Parameter-Inverted Image Pyramid Networks (PIIP). Specifically, PIIP uses pretrained models (ViTs or CNNs) as branches to process multi-scale images, where images of higher resolutions are processed by smaller network branches to balance computational cost and performance. To integrate information from different spatial scales, we further propose a novel cross-branch feature interaction mechanism. To validate PIIP, we apply it to various perception models and a representative multimodal large language model called LLaVA, and conduct extensive experiments on various tasks such as object detection, segmentation, image classification and multimodal understanding. PIIP achieves superior performance compared to single-branch and existing multi-resolution approaches with lower computational cost. When applied to InternViT-6B, a large-scale vision foundation model, PIIP can improve its performance by 1%-2% on detection and segmentation with only 40%-60% of the original computation, finally achieving 60.0 box AP on MS COCO and 59.7 mIoU on ADE20K. For multimodal understanding, our PIIP-LLaVA achieves 73.0% accuracy on TextVQA and 74.5% on MMBench with only 2.8M training data. Our code is released at https://github.com/OpenGVLab/PIIP.
H-MBA: Hierarchical MamBa Adaptation for Multi-Modal Video Understanding in Autonomous Driving
Jan 08, 2025



With the prevalence of Multimodal Large Language Models(MLLMs), autonomous driving has encountered new opportunities and challenges. In particular, multi-modal video understanding is critical to interactively analyze what will happen in the procedure of autonomous driving. However, videos in such a dynamical scene that often contains complex spatial-temporal movements, which restricts the generalization capacity of the existing MLLMs in this field. To bridge the gap, we propose a novel Hierarchical Mamba Adaptation (H-MBA) framework to fit the complicated motion changes in autonomous driving videos. Specifically, our H-MBA consists of two distinct modules, including Context Mamba (C-Mamba) and Query Mamba (Q-Mamba). First, C-Mamba contains various types of structure state space models, which can effectively capture multi-granularity video context for different temporal resolutions. Second, Q-Mamba flexibly transforms the current frame as the learnable query, and attentively selects multi-granularity video context into query. Consequently, it can adaptively integrate all the video contexts of multi-scale temporal resolutions to enhance video understanding. Via a plug-and-play paradigm in MLLMs, our H-MBA shows the remarkable performance on multi-modal video tasks in autonomous driving, e.g., for risk object detection, it outperforms the previous SOTA method with 5.5% mIoU improvement.
Dolphin: Closed-loop Open-ended Auto-research through Thinking, Practice, and Feedback
Jan 07, 2025



The scientific research paradigm is undergoing a profound transformation owing to the development of Artificial Intelligence (AI). Recent works demonstrate that various AI-assisted research methods can largely improve research efficiency by improving data analysis, accelerating computation, and fostering novel idea generation. To further move towards the ultimate goal (i.e., automatic scientific research), in this paper, we propose Dolphin, the first closed-loop open-ended auto-research framework to further build the entire process of human scientific research. Dolphin can generate research ideas, perform experiments, and get feedback from experimental results to generate higher-quality ideas. More specifically, Dolphin first generates novel ideas based on relevant papers which are ranked by the topic and task attributes. Then, the codes are automatically generated and debugged with the exception-traceback-guided local code structure. Finally, Dolphin automatically analyzes the results of each idea and feeds the results back to the next round of idea generation. Experiments are conducted on the benchmark datasets of different topics and results show that Dolphin can generate novel ideas continuously and complete the experiment in a loop. We highlight that Dolphin can automatically propose methods that are comparable to the state-of-the-art in some tasks such as 2D image classification and 3D point classification.
VideoChat-Flash: Hierarchical Compression for Long-Context Video Modeling
Dec 31, 2024



Long-context modeling is a critical capability for multimodal large language models (MLLMs), enabling them to process long-form contents with implicit memorization. Despite its advances, handling extremely long videos remains challenging due to the difficulty in maintaining crucial features over extended sequences. This paper introduces a Hierarchical visual token Compression (HiCo) method designed for high-fidelity representation and a practical context modeling system VideoChat-Flash tailored for multimodal long-sequence processing. HiCo capitalizes on the redundancy of visual information in long videos to compress long video context from the clip-level to the video-level, reducing the compute significantly while preserving essential details. VideoChat-Flash features a multi-stage short-to-long learning scheme, a rich dataset of real-world long videos named LongVid, and an upgraded "Needle-In-A-video-Haystack" (NIAH) for evaluating context capacities. In extensive experiments, VideoChat-Flash shows the leading performance on both mainstream long and short video benchmarks at the 7B model scale. It firstly gets 99.1% accuracy over 10,000 frames in NIAH among open-source models.
Vinci: A Real-time Embodied Smart Assistant based on Egocentric Vision-Language Model
Dec 30, 2024



We introduce Vinci, a real-time embodied smart assistant built upon an egocentric vision-language model. Designed for deployment on portable devices such as smartphones and wearable cameras, Vinci operates in an "always on" mode, continuously observing the environment to deliver seamless interaction and assistance. Users can wake up the system and engage in natural conversations to ask questions or seek assistance, with responses delivered through audio for hands-free convenience. With its ability to process long video streams in real-time, Vinci can answer user queries about current observations and historical context while also providing task planning based on past interactions. To further enhance usability, Vinci integrates a video generation module that creates step-by-step visual demonstrations for tasks that require detailed guidance. We hope that Vinci can establish a robust framework for portable, real-time egocentric AI systems, empowering users with contextual and actionable insights. We release the complete implementation for the development of the device in conjunction with a demo web platform to test uploaded videos at https://github.com/OpenGVLab/vinci.
OS-Genesis: Automating GUI Agent Trajectory Construction via Reverse Task Synthesis
Dec 27, 2024



Graphical User Interface (GUI) agents powered by Vision-Language Models (VLMs) have demonstrated human-like computer control capability. Despite their utility in advancing digital automation, a critical bottleneck persists: collecting high-quality trajectory data for training. Common practices for collecting such data rely on human supervision or synthetic data generation through executing pre-defined tasks, which are either resource-intensive or unable to guarantee data quality. Moreover, these methods suffer from limited data diversity and significant gaps between synthetic data and real-world environments. To address these challenges, we propose OS-Genesis, a novel GUI data synthesis pipeline that reverses the conventional trajectory collection process. Instead of relying on pre-defined tasks, OS-Genesis enables agents first to perceive environments and perform step-wise interactions, then retrospectively derive high-quality tasks to enable trajectory-level exploration. A trajectory reward model is then employed to ensure the quality of the generated trajectories. We demonstrate that training GUI agents with OS-Genesis significantly improves their performance on highly challenging online benchmarks. In-depth analysis further validates OS-Genesis's efficiency and its superior data quality and diversity compared to existing synthesis methods. Our codes, data, and checkpoints are available at \href{https://qiushisun.github.io/OS-Genesis-Home/}{OS-Genesis Homepage}.