 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnyRecon: Arbitrary-View 3D Reconstruction with Video Diffusion Model
Apr 21, 2026Sparse-view 3D reconstruction is essential for modeling scenes from casual captures, but remain challenging for non-generative reconstruction. Existing diffusion-based approaches mitigates this issues by synthesizing novel views, but they often condition on only one or two capture frames, which restricts geometric consistency and limits scalability to large or diverse scenes. We propose AnyRecon, a scalable framework for reconstruction from arbitrary and unordered sparse inputs that preserves explicit geometric control while supporting flexible conditioning cardinality. To support long-range conditioning, our method constructs a persistent global scene memory via a prepended capture view cache, and removes temporal compression to maintain frame-level correspondence under large viewpoint changes. Beyond better generative model, we also find that the interplay between generation and reconstruction is crucial for large-scale 3D scenes. Thus, we introduce a geometry-aware conditioning strategy that couples generation and reconstruction through an explicit 3D geometric memory and geometry-driven capture-view retrieval. To ensure efficiency, we combine 4-step diffusion distillation with context-window sparse attention to reduce quadratic complexity. Extensive experiments demonstrate robust and scalable reconstruction across irregular inputs, large viewpoint gaps, and long trajectories.
HiVLA: A Visual-Grounded-Centric Hierarchical Embodied Manipulation System
Apr 15, 2026While end-to-end Vision-Language-Action (VLA) models offer a promising paradigm for robotic manipulation, fine-tuning them on narrow control data often compromises the profound reasoning capabilities inherited from their base Vision-Language Models (VLMs). To resolve this fundamental trade-off, we propose HiVLA, a visual-grounded-centric hierarchical framework that explicitly decouples high-level semantic planning from low-level motor control. In high-level part, a VLM planner first performs task decomposition and visual grounding to generate structured plans, comprising a subtask instruction and a precise target bounding box. Then, to translate this plan into physical actions, we introduce a flow-matching Diffusion Transformer (DiT) action expert in low-level part equipped with a novel cascaded cross-attention mechanism. This design sequentially fuses global context, high-resolution object-centric crops and skill semantics, enabling the DiT to focus purely on robust execution. Our decoupled architecture preserves the VLM's zero-shot reasoning while allowing independent improvement of both components. Extensive experiments in simulation and the real world demonstrate that HiVLA significantly outperforms state-of-the-art end-to-end baselines, particularly excelling in long-horizon skill composition and the fine-grained manipulation of small objects in cluttered scenes.
Rein3D: Reinforced 3D Indoor Scene Generation with Panoramic Video Diffusion Models
Apr 14, 2026The growing demand for Embodied AI and VR applications has highlighted the need for synthesizing high-quality 3D indoor scenes from sparse inputs. However, existing approaches struggle to infer massive amounts of missing geometry in large unseen areas while maintaining global consistency, often producing locally plausible but globally inconsistent reconstructions. We present Rein3D, a framework that reconstructs full 360-degree indoor environments by coupling explicit 3D Gaussian Splatting (3DGS) with temporally coherent priors from video diffusion models. Our approach follows a "restore-and-refine" paradigm: we employ a radial exploration strategy to render imperfect panoramic videos along trajectories starting from the origin, effectively uncovering occluded regions from a coarse 3DGS initialization. These sequences are restored by a panoramic video-to-video diffusion model and further enhanced via video super-resolution to synthesize high-fidelity geometry and textures. Finally, these refined videos serve as pseudo-ground truths to update the global 3D Gaussian field. To support this task, we construct PanoV2V-15K, a dataset of over 15K paired clean and degraded panoramic videos for diffusion-based scene restoration. Experiments demonstrate that Rein3D produces photorealistic and globally consistent 3D scenes and significantly improves long-range camera exploration compared with existing baselines.
Adapting Feature Attenuation to NLP
Jan 02, 2026Transformer classifiers such as BERT deliver impressive closed-set accuracy, yet they remain brittle when confronted with inputs from unseen categories--a common scenario for deployed NLP systems. We investigate Open-Set Recognition (OSR) for text by porting the feature attenuation hypothesis from computer vision to transformers and by benchmarking it against state-of-the-art baselines. Concretely, we adapt the COSTARR framework--originally designed for classification in computer vision--to two modest language models (BERT (base) and GPT-2) trained to label 176 arXiv subject areas. Alongside COSTARR, we evaluate Maximum Softmax Probability (MSP), MaxLogit, and the temperature-scaled free-energy score under the OOSA and AUOSCR metrics. Our results show (i) COSTARR extends to NLP without retraining but yields no statistically significant gain over MaxLogit or MSP, and (ii) free-energy lags behind all other scores in this high-class-count setting. The study highlights both the promise and the current limitations of transplanting vision-centric OSR ideas to language models, and points toward the need for larger backbones and task-tailored attenuation strategies.
Discrete Diffusion VLA: Bringing Discrete Diffusion to Action Decoding in Vision-Language-Action Policies
Aug 27, 2025Vision-Language-Action (VLA) models adapt large vision-language backbones to map images and instructions to robot actions. However, prevailing VLA decoders either generate actions autoregressively in a fixed left-to-right order or attach continuous diffusion or flow matching heads outside the backbone, demanding specialized training and iterative sampling that hinder a unified, scalable architecture. We present Discrete Diffusion VLA, a single-transformer policy that models discretized action chunks with discrete diffusion and is trained with the same cross-entropy objective as the VLM backbone. The design retains diffusion's progressive refinement paradigm while remaining natively compatible with the discrete token interface of VLMs. Our method achieves an adaptive decoding order that resolves easy action elements before harder ones and uses secondary remasking to revisit uncertain predictions across refinement rounds, which improves consistency and enables robust error correction. This unified decoder preserves pretrained vision language priors, supports parallel decoding, breaks the autoregressive bottleneck, and reduces the number of function evaluations. Discrete Diffusion VLA achieves 96.3% avg. SR on LIBERO, 71.2% visual matching on SimplerEnv Fractal and 49.3% overall on SimplerEnv Bridge, improving over both autoregressive and continuous diffusion baselines. These findings indicate that discrete-diffusion action decoder supports precise action modeling and consistent training, laying groundwork for scaling VLA to larger models and datasets.
AutoBio: A Simulation and Benchmark for Robotic Automation in Digital Biology Laboratory
May 20, 2025Vision-language-action (VLA) models have shown promise as generalist robotic policies by jointly leveraging visual, linguistic, and proprioceptive modalities to generate action trajectories. While recent benchmarks have advanced VLA research in domestic tasks, professional science-oriented domains remain underexplored. We introduce AutoBio, a simulation framework and benchmark designed to evaluate robotic automation in biology laboratory environments--an application domain that combines structured protocols with demanding precision and multimodal interaction. AutoBio extends existing simulation capabilities through a pipeline for digitizing real-world laboratory instruments, specialized physics plugins for mechanisms ubiquitous in laboratory workflows, and a rendering stack that support dynamic instrument interfaces and transparent materials through physically based rendering. Our benchmark comprises biologically grounded tasks spanning three difficulty levels, enabling standardized evaluation of language-guided robotic manipulation in experimental protocols. We provide infrastructure for demonstration generation and seamless integration with VLA models. Baseline evaluations with two SOTA VLA models reveal significant gaps in precision manipulation, visual reasoning, and instruction following in scientific workflows. By releasing AutoBio, we aim to catalyze research on generalist robotic systems for complex, high-precision, and multimodal professional environments. The simulator and benchmark are publicly available to facilitate reproducible research.
LemmaHead: RAG Assisted Proof Generation Using Large Language Models
Jan 27, 2025Developing the logic necessary to solve mathematical problems or write mathematical proofs is one of the more difficult objectives for large language models (LLMS). Currently, the most popular methods in literature consists of fine-tuning the model on written mathematical content such as academic publications and textbooks, so that the model can learn to emulate the style of mathematical writing. In this project, we explore the effectiveness of using retrieval augmented generation (RAG) to address gaps in the mathematical reasoning of LLMs. We develop LemmaHead, a RAG knowledge base that supplements queries to the model with relevant mathematical context, with particular focus on context from published textbooks. To measure our model's performance in mathematical reasoning, our testing paradigm focuses on the task of automated theorem proving via generating proofs to a given mathematical claim in the Lean formal language.
Diffree: Text-Guided Shape Free Object Inpainting with Diffusion Model
Jul 24, 2024



This paper addresses an important problem of object addition for images with only text guidance. It is challenging because the new object must be integrated seamlessly into the image with consistent visual context, such as lighting, texture, and spatial location. While existing text-guided image inpainting methods can add objects, they either fail to preserve the background consistency or involve cumbersome human intervention in specifying bounding boxes or user-scribbled masks. To tackle this challenge, we introduce Diffree, a Text-to-Image (T2I) model that facilitates text-guided object addition with only text control. To this end, we curate OABench, an exquisite synthetic dataset by removing objects with advanced image inpainting techniques. OABench comprises 74K real-world tuples of an original image, an inpainted image with the object removed, an object mask, and object descriptions. Trained on OABench using the Stable Diffusion model with an additional mask prediction module, Diffree uniquely predicts the position of the new object and achieves object addition with guidance from only text. Extensive experiments demonstrate that Diffree excels in adding new objects with a high success rate while maintaining background consistency, spatial appropriateness, and object relevance and quality.
PhyBench: A Physical Commonsense Benchmark for Evaluating Text-to-Image Models
Jun 17, 2024
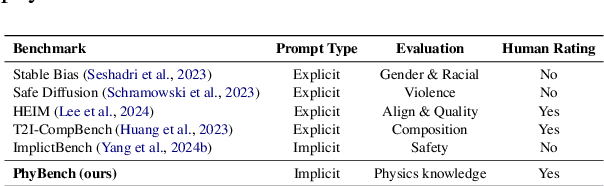

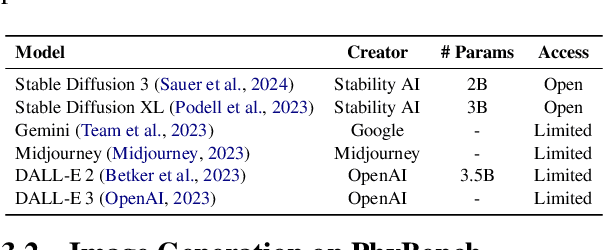
Text-to-image (T2I) models have made substantial progress in generating images from textual prompts. However, they frequently fail to produce images consistent with physical commonsense, a vital capability for applications in world simulation and everyday tasks. Current T2I evaluation benchmarks focus on metrics such as accuracy, bias, and safety, neglecting the evaluation of models' internal knowledge, particularly physical commonsense. To address this issue, we introduce PhyBench, a comprehensive T2I evaluation dataset comprising 700 prompts across 4 primary categories: mechanics, optics, thermodynamics, and material properties, encompassing 31 distinct physical scenarios. We assess 6 prominent T2I models, including proprietary models DALLE3 and Gemini, and demonstrate that incorporating physical principles into prompts enhances the models' ability to generate physically accurate images. Our findings reveal that: (1) even advanced models frequently err in various physical scenarios, except for optics; (2) GPT-4o, with item-specific scoring instructions, effectively evaluates the models' understanding of physical commonsense, closely aligning with human assessments; and (3) current T2I models are primarily focused on text-to-image translation, lacking profound reasoning regarding physical commonsense. We advocate for increased attention to the inherent knowledge within T2I models, beyond their utility as mere image generation tools. The code and data are available at https://github.com/OpenGVLab/PhyBench.
Lumina-T2X: Transforming Text into Any Modality, Resolution, and Duration via Flow-based Large Diffusion Transformers
May 09, 2024



Sora unveils the potential of scaling Diffusion Transformer for generating photorealistic images and videos at arbitrary resolutions, aspect ratios, and durations, yet it still lacks sufficient implementation details. In this technical report, we introduce the Lumina-T2X family - a series of Flow-based Large Diffusion Transformers (Flag-DiT) equipped with zero-initialized attention, as a unified framework designed to transform noise into images, videos, multi-view 3D objects, and audio clips conditioned on text instructions. By tokenizing the latent spatial-temporal space and incorporating learnable placeholders such as [nextline] and [nextframe] tokens, Lumina-T2X seamlessly unifies the representations of different modalities across various spatial-temporal resolutions. This unified approach enables training within a single framework for different modalities and allows for flexible generation of multimodal data at any resolution, aspect ratio, and length during inference. Advanced techniques like RoPE, RMSNorm, and flow matching enhance the stability, flexibility, and scalability of Flag-DiT, enabling models of Lumina-T2X to scale up to 7 billion parameters and extend the context window to 128K tokens. This is particularly beneficial for creating ultra-high-definition images with our Lumina-T2I model and long 720p videos with our Lumina-T2V model. Remarkably, Lumina-T2I, powered by a 5-billion-parameter Flag-DiT, requires only 35% of the training computational costs of a 600-million-parameter naive DiT. Our further comprehensive analysis underscores Lumina-T2X's preliminary capability in resolution extrapolation, high-resolution editing, generating consistent 3D views, and synthesizing videos with seamless transitions. We expect that the open-sourcing of Lumina-T2X will further foster creativity, transparency, and diversity in the generative AI community.