 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEventVLA: Event-Driven Visual Evidence Memory for Long-Horizon Vision-Language-Action Policies
Jun 18, 2026Memory remains a critical bottleneck for long-horizon robotic manipulation, as standard Vision-Language-Action (VLA) policies often fail when task-relevant cues become occluded or unobservable over time. While existing memory-augmented methods utilize historical context, they either suffer from severe information bottlenecks, incur high latency via decoupled dual systems, or rely on unselective buffers that accumulate massive visual redundancies. To address these limitations, we introduce EventVLA, an end-to-end framework founded on the concept of sparse visual evidence memory that comprises two core components: foundational visual anchors to retain initial and short-term contexts, and a dynamic Keyframe Evidence Memory (KEM) module. Specifically, KEM directly predicts future keyframe probabilities from the VLA's latent embeddings to autonomously capture and store sparse, task-critical visual events. This foresight-driven mechanism empowers the policy to dynamically evaluate the future causal utility of current observations, preserving transient visual evidence before it becomes unobservable. Furthermore, we propose RoboTwin-MeM, a diagnostic benchmark specifically designed to evaluate non-Markovian manipulation tasks with interactive visual evidence. Extensive evaluations show that across 17 memory-requiring simulation tasks and 4 real-world bimanual tasks, EventVLA achieves an average success rate improvement of +40% over state-of-the-art memory-augmented VLAs.
AnyScene: Towards Highly Controllable Driving Scene Generation at Anywhere and Beyond
May 25, 2026Generating high-fidelity and controllable synthetic data is critical for advancing end-to-end autonomous driving, particularly for addressing the long tail of rare safety-critical scenarios. Existing occupancy-guided methods typically rely on shallow conditioning mechanisms and reference-frame-dependent video synthesis, which limits fine-grained controllability from arbitrary BEV layouts and restricts their applicability for scalable simulation. In this paper, we propose AnyScene, a unified occupancy-centric framework for driving scene generation. AnyScene generates semantic occupancy sequences from BEV layouts through a Spatial-Temporal Occupancy Diffusion Transformer that jointly tokenizes BEV and occupancy features in an autoregressive manner. This design enables precise controllability from cross-dataset and user-defined BEV inputs while naturally supporting long-horizon generation. Building upon the generated occupancy, a Geometry-Grounded View Expansion module treats occupancy as the canonical spatial representation and synthesizes temporally consistent multi-view driving videos in a reference-free and autoregressive fashion, supporting flexible camera configurations at inference time. Extensive experiments demonstrate that AnyScene achieves state-of-the-art performance in both occupancy and video generation. It exhibits strong generalization to unseen and customized layouts, and provides measurable benefits for downstream tasks such as sparse-view 3D reconstruction.
Driving Intents Amplify Planning-Oriented Reinforcement Learning
May 14, 2026Continuous-action policies trained on a single demonstrated trajectory per scene suffer from mode collapse: samples cluster around the demonstrated maneuver and the policy cannot represent semantically distinct alternatives. Under preference-based evaluation, this caps best-of-N performance -- even oracle selection cannot recover what the sampling distribution does not contain. We introduce DIAL, a two-stage Driving-Intent-Amplified reinforcement Learning framework for preference-aligned continuous-action driving policies. In the first stage, DIAL conditions the flow-matching action head on a discrete intent label with classifier-free guidance (CFG), which expands the sampling distribution along distinct maneuver modes and breaks single-demonstration mode collapse. In the second stage, DIAL carries this expanded distribution into preference RL through multi-intent GRPO, which spans all intent classes within every preference group and prevents fine-tuning from re-collapsing around the currently preferred mode. Instantiated for end-to-end driving with eight rule-derived intents and evaluated on WOD-E2E: competitive Vision-to-Action (VA) and Vision-Language-Action (VLA) Supervised Finetuning (SFT) baselines plateau below the human-driven demonstration at best-of-128, with the strongest prior (RAP) capping at Rater Feedback Score (RFS) 8.5 even with best-of-64; intent-CFG sampling lifts this ceiling to RFS 9.14 at best-of-128, surpassing both the prior best (RAP 8.5) and the human-driven demonstration (8.13) for the first time; and multi-intent GRPO improves held-out RFS from 7.681 to 8.211, while every single-intent baseline peaks lower and degrades by training end. These results suggest that the bottleneck of preference RL on continuous-action policies trained from demonstrations is not only how to update the policy, but to expand and preserve the sampling distribution being optimized.
MindVLA-U1: VLA Beats VA with Unified Streaming Architecture for Autonomous Driving
May 14, 2026Autonomous driving has progressed from modular pipelines toward end-to-end unification, and Vision-Language-Action (VLA) models are a natural extension of this journey beyond Vision-to-Action (VA). In practice, driving VLAs have often trailed VA on planning quality, suggesting that the difficulty is not simply model scale but the interface through which semantic reasoning, temporal context, and continuous control are combined. We argue that this gap reflects how VLA has been built -- as isolated subtask improvements that fail to compose coherent driving capabilities -- rather than what VLA is. We present MindVLA-U1, the first unified streaming VLA architecture for autonomous driving. A unified VLM backbone produces AR language tokens (optional) and flow-matching continuous action trajectories in a single forward pass over one shared representation, preserving the natural output form of each modality. A full streaming design processes the driving video framewise rather than as fixed video-action chunks under costly temporal VLM modeling. Planned trajectories evolve smoothly across frames while a learned streaming memory channel carries temporal context and updates. The unified architecture enables fast/slow systems on dense & sparse MoT backbones via flexible self-attention context management, and exposes a measurable language-control path for action: language-predicted driving intents steers the action diffusion via classifier-free guidance (CFG), turning language-side intent into control signals for continuous action planning. On the long-tail WOD-E2E benchmark, MindVLA-U1 surpasses experienced human drivers for the first time (8.20 RFS vs. 8.13 GT RFS) with 2 diffusion steps, achieves state-of-the-art planning ADEs over prior VA/VLA by large margins, and matches VA latency (16 FPS vs. RAP's 18 FPS at 1B scale) while preserving natural language interfaces for human-vehicle interaction.
Action Emergence from Streaming Intent
May 14, 2026We formalize action emergence as a target capability for end-to-end autonomous driving: the ability to generate physically feasible, semantically appropriate, and safety-compliant actions in arbitrary, long-tail traffic scenes through scene-conditioned reasoning rather than retrieval or interpolation of learned scene-action mappings. We show that previous paradigms cannot deliver action emergence: autoregressive trajectory decoders collapse the inherently multimodal future into a single averaged output, while diffusion and flow-matching generators express multimodality but are not steerable by reasoned intent. We propose Streaming Intent as a concrete way to approach action emergence: a mechanism that makes driving intent (i) semantically streamed through a continuous chain-of-thought that causally derives the intent from scene understanding, and (ii) temporally streamed across clips so that intent commitments remain coherent along the driving horizon. We realize Streaming Intent in a VLA model we call SI (Streaming Intent). SI autoregressively decodes a four-step chain-of-thought and emits an intent token; the decoded intent then drives classifier-free guidance (CFG) on a flow-matching action head, requiring only two denoising steps to generate the final trajectory. On the Waymo End-to-End benchmark, SI achieves competitive aggregate performance, with an RFS score of 7.96 on the validation set and 7.74 on the test set. Beyond aggregate metrics, the model demonstrates -- to our knowledge for the first time in a fully end-to-end VLA -- intent-faithful controllability: for a fixed scene, varying the intent class at inference yields qualitatively distinct yet consistently high-quality plans, arising purely from data-driven learning without any pre-built trajectory bank or hand-coded post-hoc selector.
MiroFlow: Towards High-Performance and Robust Open-Source Agent Framework for General Deep Research Tasks
Feb 26, 2026Despite the remarkable progress of large language models (LLMs), the capabilities of standalone LLMs have begun to plateau when tackling real-world, complex tasks that require interaction with external tools and dynamic environments. Although recent agent frameworks aim to enhance model autonomy through tool integration and external interaction, they still suffer from naive workflows, unstable performance, limited support across diverse benchmarks and tasks, and heavy reliance on costly commercial APIs. In this work, we propose a high-performance and robust open-source agent framework, termed MiroFlow, which incorporates an agent graph for flexible orchestration, an optional deep reasoning mode to enhance performance, and a robust workflow execution to ensure stable and reproducible performance. Extensive experiments demonstrate that MiroFlow consistently achieves state-of-the-art performance across multiple agent benchmarks, including GAIA, BrowseComp-EN/ZH, HLE, xBench-DeepSearch, and notably FutureX. We hope it could serve as an easily accessible, reproducible, and comparable baseline for the deep research community.
MiroThinker: Pushing the Performance Boundaries of Open-Source Research Agents via Model, Context, and Interactive Scaling
Nov 18, 2025We present MiroThinker v1.0, an open-source research agent designed to advance tool-augmented reasoning and information-seeking capabilities. Unlike previous agents that only scale up model size or context length, MiroThinker explores interaction scaling at the model level, systematically training the model to handle deeper and more frequent agent-environment interactions as a third dimension of performance improvement. Unlike LLM test-time scaling, which operates in isolation and risks degradation with longer reasoning chains, interactive scaling leverages environment feedback and external information acquisition to correct errors and refine trajectories. Through reinforcement learning, the model achieves efficient interaction scaling: with a 256K context window, it can perform up to 600 tool calls per task, enabling sustained multi-turn reasoning and complex real-world research workflows. Across four representative benchmarks-GAIA, HLE, BrowseComp, and BrowseComp-ZH-the 72B variant achieves up to 81.9%, 37.7%, 47.1%, and 55.6% accuracy respectively, surpassing previous open-source agents and approaching commercial counterparts such as GPT-5-high. Our analysis reveals that MiroThinker benefits from interactive scaling consistently: research performance improves predictably as the model engages in deeper and more frequent agent-environment interactions, demonstrating that interaction depth exhibits scaling behaviors analogous to model size and context length. These findings establish interaction scaling as a third critical dimension for building next-generation open research agents, complementing model capacity and context windows.
GenExam: A Multidisciplinary Text-to-Image Exam
Sep 17, 2025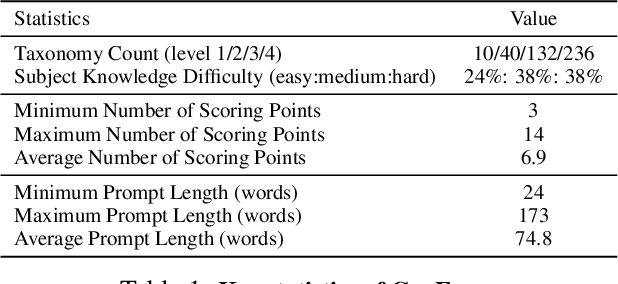

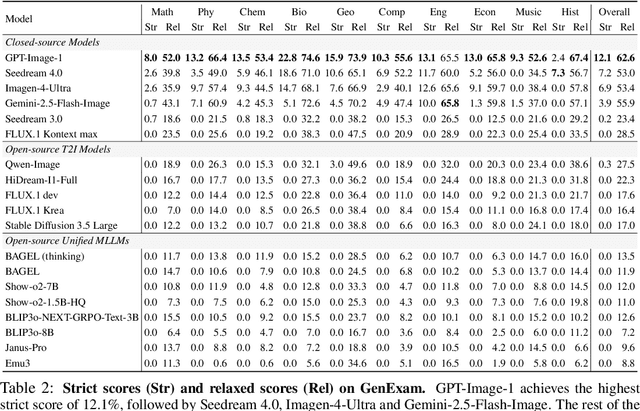

Exams are a fundamental test of expert-level intelligence and require integrated understanding, reasoning, and generation. Existing exam-style benchmarks mainly focus on understanding and reasoning tasks, and current generation benchmarks emphasize the illustration of world knowledge and visual concepts, neglecting the evaluation of rigorous drawing exams. We introduce GenExam, the first benchmark for multidisciplinary text-to-image exams, featuring 1,000 samples across 10 subjects with exam-style prompts organized under a four-level taxonomy. Each problem is equipped with ground-truth images and fine-grained scoring points to enable a precise evaluation of semantic correctness and visual plausibility. Experiments show that even state-of-the-art models such as GPT-Image-1 and Gemini-2.5-Flash-Image achieve less than 15% strict scores, and most models yield almost 0%, suggesting the great challenge of our benchmark. By framing image generation as an exam, GenExam offers a rigorous assessment of models' ability to integrate knowledge, reasoning, and generation, providing insights on the path to general AGI.
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Aug 25, 2025



We introduce InternVL 3.5, a new family of open-source multimodal models that significantly advances versatility, reasoning capability, and inference efficiency along the InternVL series. A key innovation is the Cascade Reinforcement Learning (Cascade RL) framework, which enhances reasoning through a two-stage process: offline RL for stable convergence and online RL for refined alignment. This coarse-to-fine training strategy leads to substantial improvements on downstream reasoning tasks, e.g., MMMU and MathVista. To optimize efficiency, we propose a Visual Resolution Router (ViR) that dynamically adjusts the resolution of visual tokens without compromising performance. Coupled with ViR, our Decoupled Vision-Language Deployment (DvD) strategy separates the vision encoder and language model across different GPUs, effectively balancing computational load. These contributions collectively enable InternVL3.5 to achieve up to a +16.0\% gain in overall reasoning performance and a 4.05$\times$ inference speedup compared to its predecessor, i.e., InternVL3. In addition, InternVL3.5 supports novel capabilities such as GUI interaction and embodied agency. Notably, our largest model, i.e., InternVL3.5-241B-A28B, attains state-of-the-art results among open-source MLLMs across general multimodal, reasoning, text, and agentic tasks -- narrowing the performance gap with leading commercial models like GPT-5. All models and code are publicly released.
Spatial Frequency Modulation for Semantic Segmentation
Jul 16, 2025



High spatial frequency information, including fine details like textures, significantly contributes to the accuracy of semantic segmentation. However, according to the Nyquist-Shannon Sampling Theorem, high-frequency components are vulnerable to aliasing or distortion when propagating through downsampling layers such as strided-convolution. Here, we propose a novel Spatial Frequency Modulation (SFM) that modulates high-frequency features to a lower frequency before downsampling and then demodulates them back during upsampling. Specifically, we implement modulation through adaptive resampling (ARS) and design a lightweight add-on that can densely sample the high-frequency areas to scale up the signal, thereby lowering its frequency in accordance with the Frequency Scaling Property. We also propose Multi-Scale Adaptive Upsampling (MSAU) to demodulate the modulated feature and recover high-frequency information through non-uniform upsampling This module further improves segmentation by explicitly exploiting information interaction between densely and sparsely resampled areas at multiple scales. Both modules can seamlessly integrate with various architectures, extending from convolutional neural networks to transformers. Feature visualization and analysis confirm that our method effectively alleviates aliasing while successfully retaining details after demodulation. Finally, we validate the broad applicability and effectiveness of SFM by extending it to image classification, adversarial robustness, instance segmentation, and panoptic segmentation tasks. The code is available at \href{https://github.com/Linwei-Chen/SFM}{https://github.com/Linwei-Chen/SFM}.