 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBitLM: Unlocking Multi-Token Language Generation with Bitwise Continuous Diffusion
May 12, 2026Autoregressive language models generate text one token at a time, yet natural language is inherently structured in multi-token units, including phrases, n-grams, and collocations that carry meaning jointly. This one-token bottleneck limits both the expressiveness of the model during pre-training and its throughput at inference time. Existing remedies such as speculative decoding or diffusion-based language models either leave the underlying bottleneck intact or sacrifice the causal structure essential to language modeling. We propose BitLM, a language model that represents each token as a fixed-length binary code and employs a lightweight diffusion head to denoise multiple tokens in parallel within each block. Crucially, BitLM preserves left-to-right causal attention across blocks while making joint lexical decisions within each block, combining the reliability of autoregressive modeling with the parallelism of iterative refinement. By replacing the large-vocabulary softmax with bitwise denoising, BitLM reframes token generation as iterative commitment in a compact binary space, enabling more efficient pre-training and substantially faster inference without altering the causal foundation that makes language models effective. Our results demonstrate that the one-token-at-a-time paradigm is not a fundamental requirement but an interface choice, and that changing it can yield a stronger and faster language model. We hope BitLM points toward a promising direction for next-generation language model architectures.
UniWeTok: An Unified Binary Tokenizer with Codebook Size $\mathit{2^{128}}$ for Unified Multimodal Large Language Model
Feb 15, 2026Unified Multimodal Large Language Models (MLLMs) require a visual representation that simultaneously supports high-fidelity reconstruction, complex semantic extraction, and generative suitability. However, existing visual tokenizers typically struggle to satisfy these conflicting objectives within a single framework. In this paper, we introduce UniWeTok, a unified discrete tokenizer designed to bridge this gap using a massive binary codebook ($\mathit{2^{128}}$). For training framework, we introduce Pre-Post Distillation and a Generative-Aware Prior to enhance the semantic extraction and generative prior of the discrete tokens. In terms of model architecture, we propose a convolution-attention hybrid architecture with the SigLu activation function. SigLu activation not only bounds the encoder output and stabilizes the semantic distillation process but also effectively addresses the optimization conflict between token entropy loss and commitment loss. We further propose a three-stage training framework designed to enhance UniWeTok's adaptability cross various image resolutions and perception-sensitive scenarios, such as those involving human faces and textual content. On ImageNet, UniWeTok achieves state-of-the-art image generation performance (FID: UniWeTok 1.38 vs. REPA 1.42) while requiring a remarkably low training compute (Training Tokens: UniWeTok 33B vs. REPA 262B). On general-domain, UniWeTok demonstrates highly competitive capabilities across a broad range of tasks, including multimodal understanding, image generation (DPG Score: UniWeTok 86.63 vs. FLUX.1 [Dev] 83.84), and editing (GEdit Overall Score: UniWeTok 5.09 vs. OmniGen 5.06). We release code and models to facilitate community exploration of unified tokenizer and MLLM.
BitDance: Scaling Autoregressive Generative Models with Binary Tokens
Feb 15, 2026We present BitDance, a scalable autoregressive (AR) image generator that predicts binary visual tokens instead of codebook indices. With high-entropy binary latents, BitDance lets each token represent up to $2^{256}$ states, yielding a compact yet highly expressive discrete representation. Sampling from such a huge token space is difficult with standard classification. To resolve this, BitDance uses a binary diffusion head: instead of predicting an index with softmax, it employs continuous-space diffusion to generate the binary tokens. Furthermore, we propose next-patch diffusion, a new decoding method that predicts multiple tokens in parallel with high accuracy, greatly speeding up inference. On ImageNet 256x256, BitDance achieves an FID of 1.24, the best among AR models. With next-patch diffusion, BitDance beats state-of-the-art parallel AR models that use 1.4B parameters, while using 5.4x fewer parameters (260M) and achieving 8.7x speedup. For text-to-image generation, BitDance trains on large-scale multimodal tokens and generates high-resolution, photorealistic images efficiently, showing strong performance and favorable scaling. When generating 1024x1024 images, BitDance achieves a speedup of over 30x compared to prior AR models. We release code and models to facilitate further research on AR foundation models. Code and models are available at: https://github.com/shallowdream204/BitDance.
WeTok: Powerful Discrete Tokenization for High-Fidelity Visual Reconstruction
Aug 07, 2025Visual tokenizer is a critical component for vision generation. However, the existing tokenizers often face unsatisfactory trade-off between compression ratios and reconstruction fidelity. To fill this gap, we introduce a powerful and concise WeTok tokenizer, which surpasses the previous leading tokenizers via two core innovations. (1) Group-wise lookup-free Quantization (GQ). We partition the latent features into groups, and perform lookup-free quantization for each group. As a result, GQ can efficiently overcome memory and computation limitations of prior tokenizers, while achieving a reconstruction breakthrough with more scalable codebooks. (2) Generative Decoding (GD). Different from prior tokenizers, we introduce a generative decoder with a prior of extra noise variable. In this case, GD can probabilistically model the distribution of visual data conditioned on discrete tokens, allowing WeTok to reconstruct visual details, especially at high compression ratios. Extensive experiments on mainstream benchmarks show superior performance of our WeTok. On the ImageNet 50k validation set, WeTok achieves a record-low zero-shot rFID (WeTok: 0.12 vs. FLUX-VAE: 0.18 vs. SD-VAE 3.5: 0.19). Furthermore, our highest compression model achieves a zero-shot rFID of 3.49 with a compression ratio of 768, outperforming Cosmos (384) 4.57 which has only 50% compression rate of ours. Code and models are available: https://github.com/zhuangshaobin/WeTok.
Unleashing High-Quality Image Generation in Diffusion Sampling Using Second-Order Levenberg-Marquardt-Langevin
May 30, 2025


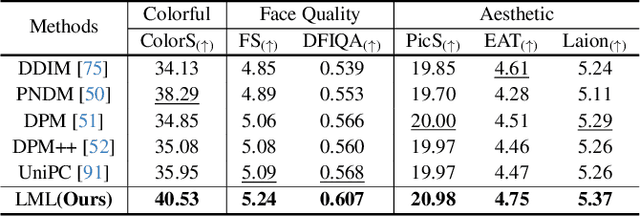
The diffusion models (DMs) have demonstrated the remarkable capability of generating images via learning the noised score function of data distribution. Current DM sampling techniques typically rely on first-order Langevin dynamics at each noise level, with efforts concentrated on refining inter-level denoising strategies. While leveraging additional second-order Hessian geometry to enhance the sampling quality of Langevin is a common practice in Markov chain Monte Carlo (MCMC), the naive attempts to utilize Hessian geometry in high-dimensional DMs lead to quadratic-complexity computational costs, rendering them non-scalable. In this work, we introduce a novel Levenberg-Marquardt-Langevin (LML) method that approximates the diffusion Hessian geometry in a training-free manner, drawing inspiration from the celebrated Levenberg-Marquardt optimization algorithm. Our approach introduces two key innovations: (1) A low-rank approximation of the diffusion Hessian, leveraging the DMs' inherent structure and circumventing explicit quadratic-complexity computations; (2) A damping mechanism to stabilize the approximated Hessian. This LML approximated Hessian geometry enables the diffusion sampling to execute more accurate steps and improve the image generation quality. We further conduct a theoretical analysis to substantiate the approximation error bound of low-rank approximation and the convergence property of the damping mechanism. Extensive experiments across multiple pretrained DMs validate that the LML method significantly improves image generation quality, with negligible computational overhead.
Efficiently Access Diffusion Fisher: Within the Outer Product Span Space
May 29, 2025Recent Diffusion models (DMs) advancements have explored incorporating the second-order diffusion Fisher information (DF), defined as the negative Hessian of log density, into various downstream tasks and theoretical analysis. However, current practices typically approximate the diffusion Fisher by applying auto-differentiation to the learned score network. This black-box method, though straightforward, lacks any accuracy guarantee and is time-consuming. In this paper, we show that the diffusion Fisher actually resides within a space spanned by the outer products of score and initial data. Based on the outer-product structure, we develop two efficient approximation algorithms to access the trace and matrix-vector multiplication of DF, respectively. These algorithms bypass the auto-differentiation operations with time-efficient vector-product calculations. Furthermore, we establish the approximation error bounds for the proposed algorithms. Experiments in likelihood evaluation and adjoint optimization demonstrate the superior accuracy and reduced computational cost of our proposed algorithms. Additionally, based on the novel outer-product formulation of DF, we design the first numerical verification experiment for the optimal transport property of the general PF-ODE deduced map.
Video-GPT via Next Clip Diffusion
May 18, 2025

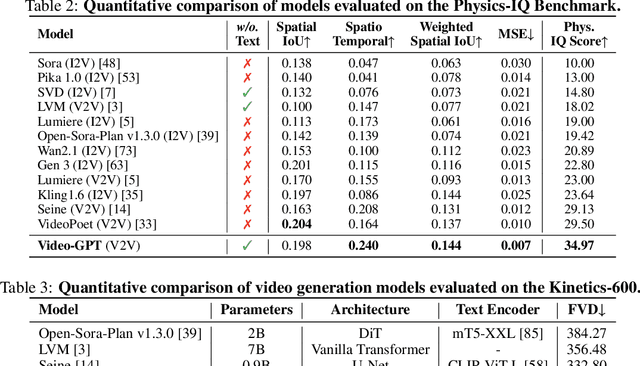
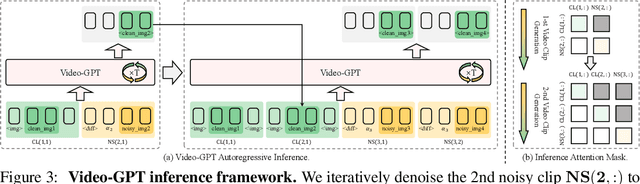
GPT has shown its remarkable success in natural language processing. However, the language sequence is not sufficient to describe spatial-temporal details in the visual world. Alternatively, the video sequence is good at capturing such details. Motivated by this fact, we propose a concise Video-GPT in this paper by treating video as new language for visual world modeling. By analogy to next token prediction in GPT, we introduce a novel next clip diffusion paradigm for pretraining Video-GPT. Different from the previous works, this distinct paradigm allows Video-GPT to tackle both short-term generation and long-term prediction, by autoregressively denoising the noisy clip according to the clean clips in the history. Extensive experiments show our Video-GPT achieves the state-of-the-art performance on video prediction, which is the key factor towards world modeling (Physics-IQ Benchmark: Video-GPT 34.97 vs. Kling 23.64 vs. Wan 20.89). Moreover, it can be well adapted on 6 mainstream video tasks in both video generation and understanding, showing its great generalization capacity in downstream. The project page is at https://Video-GPT.github.io.
V-Stylist: Video Stylization via Collaboration and Reflection of MLLM Agents
Mar 15, 2025



Despite the recent advancement in video stylization, most existing methods struggle to render any video with complex transitions, based on an open style description of user query. To fill this gap, we introduce a generic multi-agent system for video stylization, V-Stylist, by a novel collaboration and reflection paradigm of multi-modal large language models. Specifically, our V-Stylist is a systematical workflow with three key roles: (1) Video Parser decomposes the input video into a number of shots and generates their text prompts of key shot content. Via a concise video-to-shot prompting paradigm, it allows our V-Stylist to effectively handle videos with complex transitions. (2) Style Parser identifies the style in the user query and progressively search the matched style model from a style tree. Via a robust tree-of-thought searching paradigm, it allows our V-Stylist to precisely specify vague style preference in the open user query. (3) Style Artist leverages the matched model to render all the video shots into the required style. Via a novel multi-round self-reflection paradigm, it allows our V-Stylist to adaptively adjust detail control, according to the style requirement. With such a distinct design of mimicking human professionals, our V-Stylist achieves a major breakthrough over the primary challenges for effective and automatic video stylization. Moreover,we further construct a new benchmark Text-driven Video Stylization Benchmark (TVSBench), which fills the gap to assess stylization of complex videos on open user queries. Extensive experiments show that, V-Stylist achieves the state-of-the-art, e.g.,V-Stylist surpasses FRESCO and ControlVideo by 6.05% and 4.51% respectively in overall average metrics, marking a significant advance in video stylization.
TimeStep Master: Asymmetrical Mixture of Timestep LoRA Experts for Versatile and Efficient Diffusion Models in Vision
Mar 10, 2025
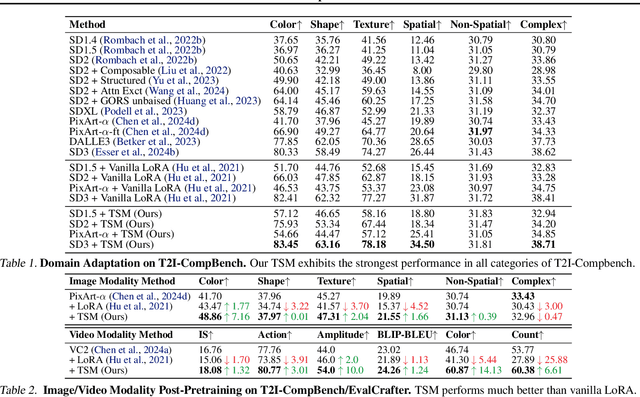
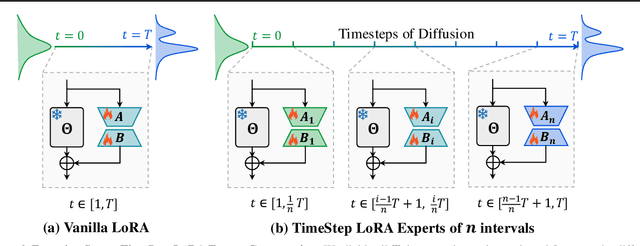
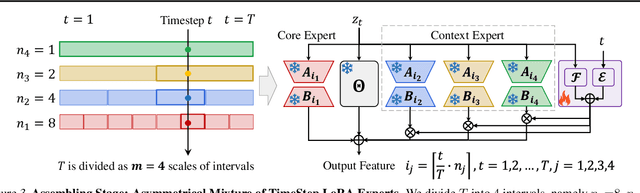
Diffusion models have driven the advancement of vision generation over the past years. However, it is often difficult to apply these large models in downstream tasks, due to massive fine-tuning cost. Recently, Low-Rank Adaptation (LoRA) has been applied for efficient tuning of diffusion models. Unfortunately, the capabilities of LoRA-tuned diffusion models are limited, since the same LoRA is used for different timesteps of the diffusion process. To tackle this problem, we introduce a general and concise TimeStep Master (TSM) paradigm with two key fine-tuning stages. In the fostering stage (1-stage), we apply different LoRAs to fine-tune the diffusion model at different timestep intervals. This results in different TimeStep LoRA experts that can effectively capture different noise levels. In the assembling stage (2-stage), we design a novel asymmetrical mixture of TimeStep LoRA experts, via core-context collaboration of experts at multi-scale intervals. For each timestep, we leverage TimeStep LoRA expert within the smallest interval as the core expert without gating, and use experts within the bigger intervals as the context experts with time-dependent gating. Consequently, our TSM can effectively model the noise level via the expert in the finest interval, and adaptively integrate contexts from the experts of other scales, boosting the versatility of diffusion models. To show the effectiveness of our TSM paradigm, we conduct extensive experiments on three typical and popular LoRA-related tasks of diffusion models, including domain adaptation, post-pretraining, and model distillation. Our TSM achieves the state-of-the-art results on all these tasks, throughout various model structures (UNet, DiT and MM-DiT) and visual data modalities (Image, Video), showing its remarkable generalization capacity.
Get In Video: Add Anything You Want to the Video
Mar 08, 2025



Video editing increasingly demands the ability to incorporate specific real-world instances into existing footage, yet current approaches fundamentally fail to capture the unique visual characteristics of particular subjects and ensure natural instance/scene interactions. We formalize this overlooked yet critical editing paradigm as "Get-In-Video Editing", where users provide reference images to precisely specify visual elements they wish to incorporate into videos. Addressing this task's dual challenges, severe training data scarcity and technical challenges in maintaining spatiotemporal coherence, we introduce three key contributions. First, we develop GetIn-1M dataset created through our automated Recognize-Track-Erase pipeline, which sequentially performs video captioning, salient instance identification, object detection, temporal tracking, and instance removal to generate high-quality video editing pairs with comprehensive annotations (reference image, tracking mask, instance prompt). Second, we present GetInVideo, a novel end-to-end framework that leverages a diffusion transformer architecture with 3D full attention to process reference images, condition videos, and masks simultaneously, maintaining temporal coherence, preserving visual identity, and ensuring natural scene interactions when integrating reference objects into videos. Finally, we establish GetInBench, the first comprehensive benchmark for Get-In-Video Editing scenario, demonstrating our approach's superior performance through extensive evaluations. Our work enables accessible, high-quality incorporation of specific real-world subjects into videos, significantly advancing personalized video editing capabilities.