 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCSSG: Measuring Code Similarity with Semantic Graphs
Jan 07, 2026Existing code similarity metrics, such as BLEU, CodeBLEU, and TSED, largely rely on surface-level string overlap or abstract syntax tree structures, and often fail to capture deeper semantic relationships between programs.We propose CSSG (Code Similarity using Semantic Graphs), a novel metric that leverages program dependence graphs to explicitly model control dependencies and variable interactions, providing a semantics-aware representation of code.Experiments on the CodeContests+ dataset show that CSSG consistently outperforms existing metrics in distinguishing more similar code from less similar code under both monolingual and cross-lingual settings, demonstrating that dependency-aware graph representations offer a more effective alternative to surface-level or syntax-based similarity measures.
OpenNovelty: An LLM-powered Agentic System for Verifiable Scholarly Novelty Assessment
Jan 04, 2026Evaluating novelty is critical yet challenging in peer review, as reviewers must assess submissions against a vast, rapidly evolving literature. This report presents OpenNovelty, an LLM-powered agentic system for transparent, evidence-based novelty analysis. The system operates through four phases: (1) extracting the core task and contribution claims to generate retrieval queries; (2) retrieving relevant prior work based on extracted queries via semantic search engine; (3) constructing a hierarchical taxonomy of core-task-related work and performing contribution-level full-text comparisons against each contribution; and (4) synthesizing all analyses into a structured novelty report with explicit citations and evidence snippets. Unlike naive LLM-based approaches, \textsc{OpenNovelty} grounds all assessments in retrieved real papers, ensuring verifiable judgments. We deploy our system on 500+ ICLR 2026 submissions with all reports publicly available on our website, and preliminary analysis suggests it can identify relevant prior work, including closely related papers that authors may overlook. OpenNovelty aims to empower the research community with a scalable tool that promotes fair, consistent, and evidence-backed peer review.
Multi-hop Reasoning via Early Knowledge Alignment
Dec 23, 2025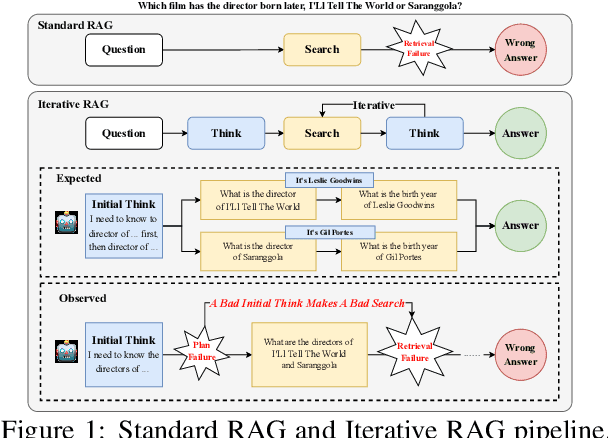

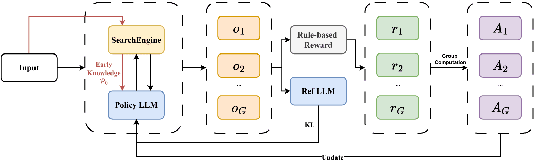
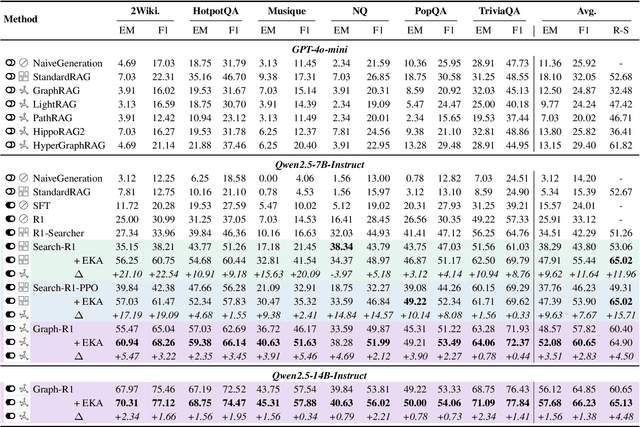
Retrieval-Augmented Generation (RAG) has emerged as a powerful paradigm for Large Language Models (LLMs) to address knowledge-intensive queries requiring domain-specific or up-to-date information. To handle complex multi-hop questions that are challenging for single-step retrieval, iterative RAG approaches incorporating reinforcement learning have been proposed. However, existing iterative RAG systems typically plan to decompose questions without leveraging information about the available retrieval corpus, leading to inefficient retrieval and reasoning chains that cascade into suboptimal performance. In this paper, we introduce Early Knowledge Alignment (EKA), a simple but effective module that aligns LLMs with retrieval set before planning in iterative RAG systems with contextually relevant retrieved knowledge. Extensive experiments on six standard RAG datasets demonstrate that by establishing a stronger reasoning foundation, EKA significantly improves retrieval precision, reduces cascading errors, and enhances both performance and efficiency. Our analysis from an entropy perspective demonstrate that incorporating early knowledge reduces unnecessary exploration during the reasoning process, enabling the model to focus more effectively on relevant information subsets. Moreover, EKA proves effective as a versatile, training-free inference strategy that scales seamlessly to large models. Generalization tests across diverse datasets and retrieval corpora confirm the robustness of our approach. Overall, EKA advances the state-of-the-art in iterative RAG systems while illuminating the critical interplay between structured reasoning and efficient exploration in reinforcement learning-augmented frameworks. The code is released at \href{https://github.com/yxzwang/EarlyKnowledgeAlignment}{Github}.
Memory in the Age of AI Agents
Dec 15, 2025Memory has emerged, and will continue to remain, a core capability of foundation model-based agents. As research on agent memory rapidly expands and attracts unprecedented attention, the field has also become increasingly fragmented. Existing works that fall under the umbrella of agent memory often differ substantially in their motivations, implementations, and evaluation protocols, while the proliferation of loosely defined memory terminologies has further obscured conceptual clarity. Traditional taxonomies such as long/short-term memory have proven insufficient to capture the diversity of contemporary agent memory systems. This work aims to provide an up-to-date landscape of current agent memory research. We begin by clearly delineating the scope of agent memory and distinguishing it from related concepts such as LLM memory, retrieval augmented generation (RAG), and context engineering. We then examine agent memory through the unified lenses of forms, functions, and dynamics. From the perspective of forms, we identify three dominant realizations of agent memory, namely token-level, parametric, and latent memory. From the perspective of functions, we propose a finer-grained taxonomy that distinguishes factual, experiential, and working memory. From the perspective of dynamics, we analyze how memory is formed, evolved, and retrieved over time. To support practical development, we compile a comprehensive summary of memory benchmarks and open-source frameworks. Beyond consolidation, we articulate a forward-looking perspective on emerging research frontiers, including memory automation, reinforcement learning integration, multimodal memory, multi-agent memory, and trustworthiness issues. We hope this survey serves not only as a reference for existing work, but also as a conceptual foundation for rethinking memory as a first-class primitive in the design of future agentic intelligence.
AgentPRM: Process Reward Models for LLM Agents via Step-Wise Promise and Progress
Nov 11, 2025Despite rapid development, large language models (LLMs) still encounter challenges in multi-turn decision-making tasks (i.e., agent tasks) like web shopping and browser navigation, which require making a sequence of intelligent decisions based on environmental feedback. Previous work for LLM agents typically relies on elaborate prompt engineering or fine-tuning with expert trajectories to improve performance. In this work, we take a different perspective: we explore constructing process reward models (PRMs) to evaluate each decision and guide the agent's decision-making process. Unlike LLM reasoning, where each step is scored based on correctness, actions in agent tasks do not have a clear-cut correctness. Instead, they should be evaluated based on their proximity to the goal and the progress they have made. Building on this insight, we propose a re-defined PRM for agent tasks, named AgentPRM, to capture both the interdependence between sequential decisions and their contribution to the final goal. This enables better progress tracking and exploration-exploitation balance. To scalably obtain labeled data for training AgentPRM, we employ a Temporal Difference-based (TD-based) estimation method combined with Generalized Advantage Estimation (GAE), which proves more sample-efficient than prior methods. Extensive experiments across different agentic tasks show that AgentPRM is over $8\times$ more compute-efficient than baselines, and it demonstrates robust improvement when scaling up test-time compute. Moreover, we perform detailed analyses to show how our method works and offer more insights, e.g., applying AgentPRM to the reinforcement learning of LLM agents.
Thinking with Video: Video Generation as a Promising Multimodal Reasoning Paradigm
Nov 06, 2025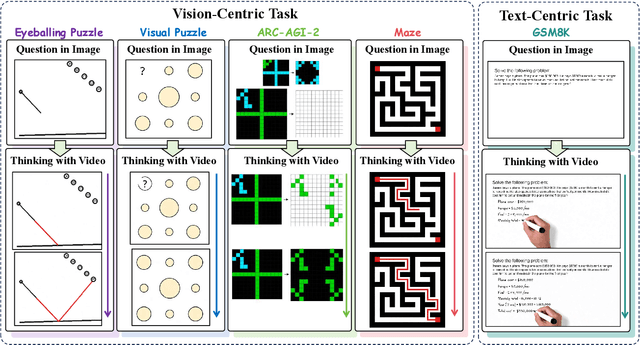
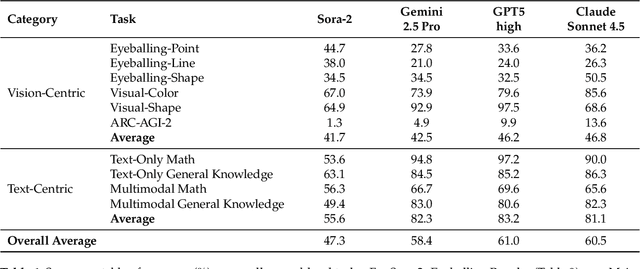
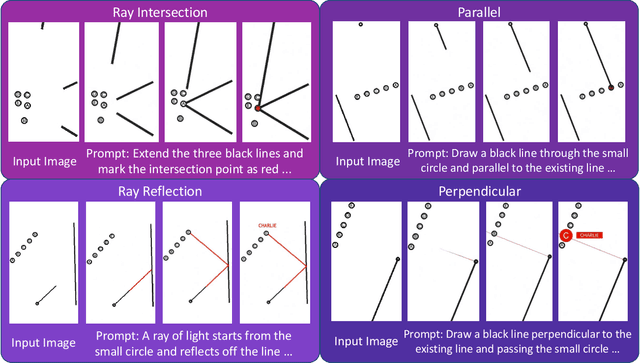

"Thinking with Text" and "Thinking with Images" paradigm significantly improve the reasoning ability of large language models (LLMs) and Vision Language Models (VLMs). However, these paradigms have inherent limitations. (1) Images capture only single moments and fail to represent dynamic processes or continuous changes, and (2) The separation of text and vision as distinct modalities, hindering unified multimodal understanding and generation. To overcome these limitations, we introduce "Thinking with Video", a new paradigm that leverages video generation models, such as Sora-2, to bridge visual and textual reasoning in a unified temporal framework. To support this exploration, we developed the Video Thinking Benchmark (VideoThinkBench). VideoThinkBench encompasses two task categories: (1) vision-centric tasks (e.g., Eyeballing Puzzles), and (2) text-centric tasks (e.g., subsets of GSM8K, MMMU). Our evaluation establishes Sora-2 as a capable reasoner. On vision-centric tasks, Sora-2 is generally comparable to state-of-the-art (SOTA) VLMs, and even surpasses VLMs on several tasks, such as Eyeballing Games. On text-centric tasks, Sora-2 achieves 92% accuracy on MATH, and 75.53% accuracy on MMMU. Furthermore, we systematically analyse the source of these abilities. We also find that self-consistency and in-context learning can improve Sora-2's performance. In summary, our findings demonstrate that the video generation model is the potential unified multimodal understanding and generation model, positions "thinking with video" as a unified multimodal reasoning paradigm.
Counteracting Matthew Effect in Self-Improvement of LVLMs through Head-Tail Re-balancing
Oct 30, 2025Self-improvement has emerged as a mainstream paradigm for advancing the reasoning capabilities of large vision-language models (LVLMs), where models explore and learn from successful trajectories iteratively. However, we identify a critical issue during this process: the model excels at generating high-quality trajectories for simple queries (i.e., head data) but struggles with more complex ones (i.e., tail data). This leads to an imbalanced optimization that drives the model to prioritize simple reasoning skills, while hindering its ability to tackle more complex reasoning tasks. Over iterations, this imbalance becomes increasingly pronounced--a dynamic we term the "Matthew effect"--which ultimately hinders further model improvement and leads to performance bottlenecks. To counteract this challenge, we introduce four efficient strategies from two perspectives: distribution-reshaping and trajectory-resampling, to achieve head-tail re-balancing during the exploration-and-learning self-improvement process. Extensive experiments on Qwen2-VL-7B-Instruct and InternVL2.5-4B models across visual reasoning tasks demonstrate that our methods consistently improve visual reasoning capabilities, outperforming vanilla self-improvement by 3.86 points on average.
MOSS-Speech: Towards True Speech-to-Speech Models Without Text Guidance
Oct 02, 2025



Spoken dialogue systems often rely on cascaded pipelines that transcribe, process, and resynthesize speech. While effective, this design discards paralinguistic cues and limits expressivity. Recent end-to-end methods reduce latency and better preserve these cues, yet still rely on text intermediates, creating a fundamental bottleneck. We present MOSS-Speech, a true speech-to-speech large language model that directly understands and generates speech without relying on text guidance. Our approach combines a modality-based layer-splitting architecture with a frozen pre-training strategy, preserving the reasoning and knowledge of pretrained text LLMs while adding native speech capabilities. Experiments show that our model achieves state-of-the-art results in spoken question answering and delivers comparable speech-to-speech performance relative to existing text-guided systems, while still maintaining competitive text performance. By narrowing the gap between text-guided and direct speech generation, our work establishes a new paradigm for expressive and efficient end-to-end speech interaction.
From Scores to Preferences: Redefining MOS Benchmarking for Speech Quality Reward Modeling
Oct 01, 2025Assessing the perceptual quality of synthetic speech is crucial for guiding the development and refinement of speech generation models. However, it has traditionally relied on human subjective ratings such as the Mean Opinion Score (MOS), which depend on manual annotations and often suffer from inconsistent rating standards and poor reproducibility. To address these limitations, we introduce MOS-RMBench, a unified benchmark that reformulates diverse MOS datasets into a preference-comparison setting, enabling rigorous evaluation across different datasets. Building on MOS-RMBench, we systematically construct and evaluate three paradigms for reward modeling: scalar reward models, semi-scalar reward models, and generative reward models (GRMs). Our experiments reveal three key findings: (1) scalar models achieve the strongest overall performance, consistently exceeding 74% accuracy; (2) most models perform considerably worse on synthetic speech than on human speech; and (3) all models struggle on pairs with very small MOS differences. To improve performance on these challenging pairs, we propose a MOS-aware GRM that incorporates an MOS-difference-based reward function, enabling the model to adaptively scale rewards according to the difficulty of each sample pair. Experimental results show that the MOS-aware GRM significantly improves fine-grained quality discrimination and narrows the gap with scalar models on the most challenging cases. We hope this work will establish both a benchmark and a methodological framework to foster more rigorous and scalable research in automatic speech quality assessment.
MDAR: A Multi-scene Dynamic Audio Reasoning Benchmark
Sep 26, 2025The ability to reason from audio, including speech, paralinguistic cues, environmental sounds, and music, is essential for AI agents to interact effectively in real-world scenarios. Existing benchmarks mainly focus on static or single-scene settings and do not fully capture scenarios where multiple speakers, unfolding events, and heterogeneous audio sources interact. To address these challenges, we introduce MDAR, a benchmark for evaluating models on complex, multi-scene, and dynamically evolving audio reasoning tasks. MDAR comprises 3,000 carefully curated question-answer pairs linked to diverse audio clips, covering five categories of complex reasoning and spanning three question types. We benchmark 26 state-of-the-art audio language models on MDAR and observe that they exhibit limitations in complex reasoning tasks. On single-choice questions, Qwen2.5-Omni (open-source) achieves 76.67% accuracy, whereas GPT-4o Audio (closed-source) reaches 68.47%; however, GPT-4o Audio substantially outperforms Qwen2.5-Omni on the more challenging multiple-choice and open-ended tasks. Across all three question types, no model achieves 80% performance. These findings underscore the unique challenges posed by MDAR and its value as a benchmark for advancing audio reasoning research.Code and benchmark can be found at https://github.com/luckyerr/MDAR.