 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntropy Is Not Enough: Unlocking Effective Reinforcement Learning for Visual Reasoning via Vision-Anchored Token Selection
Jun 03, 2026While token-level entropy is commonly recognized as effective for credit assignment in text-only reinforcement learning with verifiable rewards (RLVR), it remains unclear whether this mechanism still holds in visual reasoning. Our controlled study shows that this mechanism collapses in visual reasoning due to the omission of vision-sensitive tokens with naturally low entropy. Although existing multimodal RL methods increasingly acknowledge the importance of visual perception, they struggle to satisfy the inherent demand for interleaving precise perceptual grounding with semantic reasoning, either lacking systematic visual measurements or overlooking that token entropy primarily drives semantic exploration. To address this, we introduce VEPO (Vision-Entropy token-selection for Policy Optimization), an effective RL framework explicitly integrating visual sensitivity with token entropy via a principled multiplicative coupling, where VEPO redirects gradient credit toward tokens which are simultaneously visually grounded and highly informative. Extensive experiments demonstrate VEPO's leading performance, significantly outperforming the entropy-only baseline by 2.28 points at 7B-scale and 3.15 points at 3B-scale. Ablations further substantiate the soundness of our method.
LoopFM: Learning frOm HistOrical RePresentations of Foundation Model for Recommendation
May 28, 2026Knowledge distillation (KD) transfers a single scalar prediction from a large foundation model (FM) to compact vertical models (VMs), suffering from diminishing transfer ratio -- the fraction of FM improvement captured by the VM -- as a single scalar cannot convey the rich intermediate knowledge that larger FMs learn. To address this bottleneck, we propose LoopFM (Learning frOm HistOrical ReP*resentations of FM), a framework that opens a high-bandwidth transfer channel by structuring FM intermediate embeddings as input features (e.g., user history sequence) for downstream VMs, without requiring real-time FM inference at serving and architectural coupling between FM and VM. We provide a theoretical framework for LoopFM with a gain decomposition and transfer-ratio analysis. On three public benchmarks, LoopFM demonstrates strong AUC improvements (e.g., 6\%+ on TaobaoAd) and complementary knowledge transfer capability with KD. On industrial-scale systems (billions of examples, trillion-parameter FMs), LoopFM approximately doubles the knowledge transfer ratio on top of KD, delivering a +0.5\% conversion improvement in Y1H1, and a +1.03\% and +1.22\% conversion improvement from two individual launches respectively in Y1H2.
ERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
Meta Lattice: Model Space Redesign for Cost-Effective Industry-Scale Ads Recommendations
Dec 15, 2025The rapidly evolving landscape of products, surfaces, policies, and regulations poses significant challenges for deploying state-of-the-art recommendation models at industry scale, primarily due to data fragmentation across domains and escalating infrastructure costs that hinder sustained quality improvements. To address this challenge, we propose Lattice, a recommendation framework centered around model space redesign that extends Multi-Domain, Multi-Objective (MDMO) learning beyond models and learning objectives. Lattice addresses these challenges through a comprehensive model space redesign that combines cross-domain knowledge sharing, data consolidation, model unification, distillation, and system optimizations to achieve significant improvements in both quality and cost-efficiency. Our deployment of Lattice at Meta has resulted in 10% revenue-driving top-line metrics gain, 11.5% user satisfaction improvement, 6% boost in conversion rate, with 20% capacity saving.
Memory in the Age of AI Agents
Dec 15, 2025Memory has emerged, and will continue to remain, a core capability of foundation model-based agents. As research on agent memory rapidly expands and attracts unprecedented attention, the field has also become increasingly fragmented. Existing works that fall under the umbrella of agent memory often differ substantially in their motivations, implementations, and evaluation protocols, while the proliferation of loosely defined memory terminologies has further obscured conceptual clarity. Traditional taxonomies such as long/short-term memory have proven insufficient to capture the diversity of contemporary agent memory systems. This work aims to provide an up-to-date landscape of current agent memory research. We begin by clearly delineating the scope of agent memory and distinguishing it from related concepts such as LLM memory, retrieval augmented generation (RAG), and context engineering. We then examine agent memory through the unified lenses of forms, functions, and dynamics. From the perspective of forms, we identify three dominant realizations of agent memory, namely token-level, parametric, and latent memory. From the perspective of functions, we propose a finer-grained taxonomy that distinguishes factual, experiential, and working memory. From the perspective of dynamics, we analyze how memory is formed, evolved, and retrieved over time. To support practical development, we compile a comprehensive summary of memory benchmarks and open-source frameworks. Beyond consolidation, we articulate a forward-looking perspective on emerging research frontiers, including memory automation, reinforcement learning integration, multimodal memory, multi-agent memory, and trustworthiness issues. We hope this survey serves not only as a reference for existing work, but also as a conceptual foundation for rethinking memory as a first-class primitive in the design of future agentic intelligence.
TACTIC: Translation Agents with Cognitive-Theoretic Interactive Collaboration
Jun 11, 2025

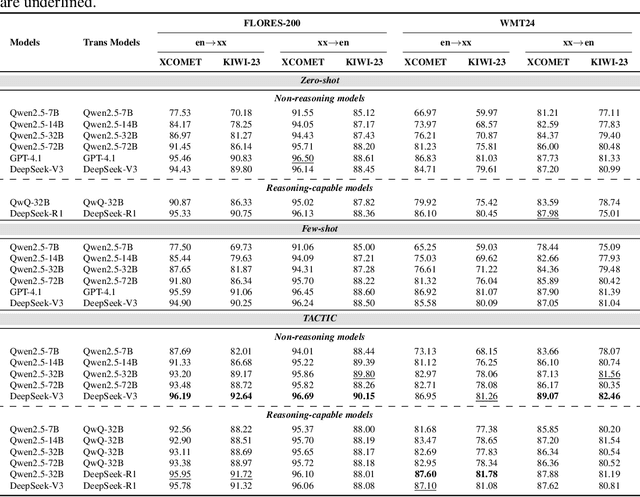

Machine translation has long been a central task in natural language processing. With the rapid advancement of large language models (LLMs), there has been remarkable progress in translation quality. However, fully realizing the translation potential of LLMs remains an open challenge. Recent studies have explored multi-agent systems to decompose complex translation tasks into collaborative subtasks, showing initial promise in enhancing translation quality through agent cooperation and specialization. Nevertheless, existing multi-agent translation frameworks largely neglect foundational insights from cognitive translation studies. These insights emphasize how human translators employ different cognitive strategies, such as balancing literal and free translation, refining expressions based on context, and iteratively evaluating outputs. To address this limitation, we propose a cognitively informed multi-agent framework called TACTIC, which stands for T ranslation A gents with Cognitive- T heoretic Interactive Collaboration. The framework comprises six functionally distinct agents that mirror key cognitive processes observed in human translation behavior. These include agents for drafting, refinement, evaluation, scoring, context reasoning, and external knowledge gathering. By simulating an interactive and theory-grounded translation workflow, TACTIC effectively leverages the full capacity of LLMs for high-quality translation. Experimental results on diverse language pairs from the FLORES-200 and WMT24 benchmarks show that our method consistently achieves state-of-the-art performance. Using DeepSeek-V3 as the base model, TACTIC surpasses GPT-4.1 by an average of +0.6 XCOMET and +1.18 COMETKIWI-23. Compared to DeepSeek-R1, it further improves by +0.84 XCOMET and +2.99 COMETKIWI-23. Code is available at https://github.com/weiyali126/TACTIC.
Search-TTA: A Multimodal Test-Time Adaptation Framework for Visual Search in the Wild
May 16, 2025



To perform autonomous visual search for environmental monitoring, a robot may leverage satellite imagery as a prior map. This can help inform coarse, high-level search and exploration strategies, even when such images lack sufficient resolution to allow fine-grained, explicit visual recognition of targets. However, there are some challenges to overcome with using satellite images to direct visual search. For one, targets that are unseen in satellite images are underrepresented (compared to ground images) in most existing datasets, and thus vision models trained on these datasets fail to reason effectively based on indirect visual cues. Furthermore, approaches which leverage large Vision Language Models (VLMs) for generalization may yield inaccurate outputs due to hallucination, leading to inefficient search. To address these challenges, we introduce Search-TTA, a multimodal test-time adaptation framework that can accept text and/or image input. First, we pretrain a remote sensing image encoder to align with CLIP's visual encoder to output probability distributions of target presence used for visual search. Second, our framework dynamically refines CLIP's predictions during search using a test-time adaptation mechanism. Through a feedback loop inspired by Spatial Poisson Point Processes, gradient updates (weighted by uncertainty) are used to correct (potentially inaccurate) predictions and improve search performance. To validate Search-TTA's performance, we curate a visual search dataset based on internet-scale ecological data. We find that Search-TTA improves planner performance by up to 9.7%, particularly in cases with poor initial CLIP predictions. It also achieves comparable performance to state-of-the-art VLMs. Finally, we deploy Search-TTA on a real UAV via hardware-in-the-loop testing, by simulating its operation within a large-scale simulation that provides onboard sensing.
Rethinking Multi-modal Object Detection from the Perspective of Mono-Modality Feature Learning
Mar 14, 2025Multi-Modal Object Detection (MMOD), due to its stronger adaptability to various complex environments, has been widely applied in various applications. Extensive research is dedicated to the RGB-IR object detection, primarily focusing on how to integrate complementary features from RGB-IR modalities. However, they neglect the mono-modality insufficient learning problem that the decreased feature extraction capability in multi-modal joint learning. This leads to an unreasonable but prevalent phenomenon--Fusion Degradation, which hinders the performance improvement of the MMOD model. Motivated by this, in this paper, we introduce linear probing evaluation to the multi-modal detectors and rethink the multi-modal object detection task from the mono-modality learning perspective. Therefore, we construct an novel framework called M$^2$D-LIF, which consists of the Mono-Modality Distillation (M$^2$D) method and the Local Illumination-aware Fusion (LIF) module. The M$^2$D-LIF framework facilitates the sufficient learning of mono-modality during multi-modal joint training and explores a lightweight yet effective feature fusion manner to achieve superior object detection performance. Extensive experiments conducted on three MMOD datasets demonstrate that our M$^2$D-LIF effectively mitigates the Fusion Degradation phenomenon and outperforms the previous SOTA detectors.
EliteKV: Scalable KV Cache Compression via RoPE Frequency Selection and Joint Low-Rank Projection
Mar 03, 2025



Rotary Position Embedding (RoPE) enables each attention head to capture multi-frequency information along the sequence dimension and is widely applied in foundation models. However, the nonlinearity introduced by RoPE complicates optimization of the key state in the Key-Value (KV) cache for RoPE-based attention. Existing KV cache compression methods typically store key state before rotation and apply the transformation during decoding, introducing additional computational overhead. This paper introduces EliteKV, a flexible modification framework for RoPE-based models supporting variable KV cache compression ratios. EliteKV first identifies the intrinsic frequency preference of each head using RoPElite, selectively restoring linearity to certain dimensions of key within attention computation. Building on this, joint low-rank compression of key and value enables partial cache sharing. Experimental results show that with minimal uptraining on only $0.6\%$ of the original training data, RoPE-based models achieve a $75\%$ reduction in KV cache size while preserving performance within a negligible margin. Furthermore, EliteKV consistently performs well across models of different scales within the same family.
External Large Foundation Model: How to Efficiently Serve Trillions of Parameters for Online Ads Recommendation
Feb 26, 2025



Ads recommendation is a prominent service of online advertising systems and has been actively studied. Recent studies indicate that scaling-up and advanced design of the recommendation model can bring significant performance improvement. However, with a larger model scale, such prior studies have a significantly increasing gap from industry as they often neglect two fundamental challenges in industrial-scale applications. First, training and inference budgets are restricted for the model to be served, exceeding which may incur latency and impair user experience. Second, large-volume data arrive in a streaming mode with data distributions dynamically shifting, as new users/ads join and existing users/ads leave the system. We propose the External Large Foundation Model (ExFM) framework to address the overlooked challenges. Specifically, we develop external distillation and a data augmentation system (DAS) to control the computational cost of training/inference while maintaining high performance. We design the teacher in a way like a foundation model (FM) that can serve multiple students as vertical models (VMs) to amortize its building cost. We propose Auxiliary Head and Student Adapter to mitigate the data distribution gap between FM and VMs caused by the streaming data issue. Comprehensive experiments on internal industrial-scale applications and public datasets demonstrate significant performance gain by ExFM.