 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Model, Multiple Goals: Adaptive Multi-Objective Learning for E-commerce Dialogue Systems
Jun 08, 2026Dialogue systems in e-commerce scenarios often need to satisfy multiple objectives: accurately reasoning over user profiles (e.g., eligibility, credit limit) to ensure correct decision-making and user state interpretation, while also generating natural and faithful responses. These goals are complementary but not identical. In this work, we propose MORE, an adaptive Multi-Objective REinforcement learning framework that jointly optimizes reasoning accuracy and linguistic naturalness. Our preliminary experiments show that directly mixing rewards with diverging optimization dynamics can cause oscillations and unstable learning. Thus, instead of optimizing a single mixed reward, we treat reasoning functions as constraints that guide policy optimization. At inference time, the system directly generates responses without explicit reasoning steps, while still benefiting from reasoning-enhanced scaffold and avoiding additional inference overhead. To better balance linguistic objectives during response generation, we introduce an adaptive multi-reward mechanism that aggregates signals such as fluency and naturalness and dynamically reweighs them via gradient feedback. We evaluate MORE on two real-world dialogue systems at ByteDance and the MultiWOZ 2.2 benchmark, where it consistently outperforms strong baselines. In 14-day online experiments on ByteDance production traffic, MORE improves overall and reached conversion by 16.53% and 30.09%, while increasing user satisfaction and reducing handoff rates. Notably, in a human-machine comparison, MORE recovers about 60% of the incremental conversion lift achieved by human agents.
MS-COOT: Comparing Morse-Smale Complexes with Co-Optimal Transport
Jun 06, 2026Understanding and comparing structures in scalar fields is a central challenge in scientific visualization, with applications ranging from feature analysis to temporal and structural comparison. The Morse-Smale (MS) complex provides a natural representation by decomposing a scalar field into regions induced by gradient flow. However, existing approaches typically rely on graph-based representations, capturing relationships between critical points while discarding region-level structure. In this work, we represent the MS complex as a hypergraph, where critical points form nodes and regions define hyperedges. We introduce MS-COOT, a co-optimal transport distance that jointly computes correspondences between critical points and regions. This formulation enables explicit region-to-region matching within a distance-based framework, allowing identification of region-level events such as splitting and merging. We instantiate this framework with domain-specific components, including a hypernetwork function encoding critical point-region relationships, persistence-based probability measures that emphasize topologically significant features, and a sample cost term that incorporates critical point attributes. We evaluate MS-COOT on five datasets spanning 2D simulations, 3D surface meshes, and volumetric data. Our results show that MS-COOT captures region-level structural changes that are not reflected by graph-based distances, while achieving strong performance in downstream tasks such as classification and resolution discrimination.
Deploy DINO with Many-to-Many Association
Apr 26, 2026Motivated by the limited generalization of supervised image matching models to unseen image domains, we explore the zero-shot deployment of DINO features for this task. The generalist visual representation extracted from DINO has inherent ambiguity when used to match feature points among semantically similar instances, prompting us to adopt a many-to-many (m-to-m) matching paradigm. However, the existing robust mechanism under m-to-m data association is computationally heavy, which requires finding a maximum-cardinality matching in the inlier association graph for each parameter evaluation. To address this inefficiency, we introduce a novel likelihood perspective, which interprets the existing method as a zeroth-order approximation of otherwise intractable likelihood calculation,and inspires us to propose a faster and finer-grained robust mechanism, termed as Harmonic Consensus Maximization (HCM). Take camera pose estimation as an exemplifying downstream task, we demonstrate that general-purpose visual features, used out of the box without any adaptation, can compete with specialized matching models on out-of-distribution datasets when mated with m-to-m association and the HCM mechanism.
AI Can Learn Scientific Taste
Mar 15, 2026Great scientists have strong judgement and foresight, closely tied to what we call scientific taste. Here, we use the term to refer to the capacity to judge and propose research ideas with high potential impact. However, most relative research focuses on improving an AI scientist's executive capability, while enhancing an AI's scientific taste remains underexplored. In this work, we propose Reinforcement Learning from Community Feedback (RLCF), a training paradigm that uses large-scale community signals as supervision, and formulate scientific taste learning as a preference modeling and alignment problem. For preference modeling, we train Scientific Judge on 700K field- and time-matched pairs of high- vs. low-citation papers to judge ideas. For preference alignment, using Scientific Judge as a reward model, we train a policy model, Scientific Thinker, to propose research ideas with high potential impact. Experiments show Scientific Judge outperforms SOTA LLMs (e.g., GPT-5.2, Gemini 3 Pro) and generalizes to future-year test, unseen fields, and peer-review preference. Furthermore, Scientific Thinker proposes research ideas with higher potential impact than baselines. Our findings show that AI can learn scientific taste, marking a key step toward reaching human-level AI scientists.
MetaState: Persistent Working Memory for Discrete Diffusion Language Models
Mar 02, 2026Discrete diffusion language models (dLLMs) generate text by iteratively denoising a masked sequence. Compared with autoregressive models, this paradigm naturally supports parallel decoding, bidirectional context, and flexible generation patterns. However, standard dLLMs condition each denoising step only on the current hard-masked sequence, while intermediate continuous representations are discarded after sampling and remasking. We refer to this bottleneck as the \textbf{Information Island} problem. It leads to redundant recomputation across steps and can degrade cross-step consistency. We address this limitation with \textbf{MetaState}, a lightweight recurrent augmentation that equips a frozen dLLM backbone with a persistent, fixed-size working memory that remains independent of sequence length. \textbf{MetaState} consists of three trainable modules: a cross-attention Mixer that reads backbone activations into memory slots, a GRU-style Updater that integrates information across denoising steps, and a cross-attention Injector that feeds the updated memory back into backbone activations. We train these modules with $K$-step unrolling to expose them to multi-step denoising dynamics during fine-tuning. On LLaDA-8B and Dream-7B, \textbf{MetaState} introduces negligible trainable parameters while keeping the backbone frozen, and it consistently improves accuracy over frozen baselines. These results demonstrate that persistent cross-step memory is an effective mechanism for bridging denoising steps and improving generation quality in discrete diffusion language models.
STAR-S: Improving Safety Alignment through Self-Taught Reasoning on Safety Rules
Jan 07, 2026Defending against jailbreak attacks is crucial for the safe deployment of Large Language Models (LLMs). Recent research has attempted to improve safety by training models to reason over safety rules before responding. However, a key issue lies in determining what form of safety reasoning effectively defends against jailbreak attacks, which is difficult to explicitly design or directly obtain. To address this, we propose \textbf{STAR-S} (\textbf{S}elf-\textbf{TA}ught \textbf{R}easoning based on \textbf{S}afety rules), a framework that integrates the learning of safety rule reasoning into a self-taught loop. The core of STAR-S involves eliciting reasoning and reflection guided by safety rules, then leveraging fine-tuning to enhance safety reasoning. Repeating this process creates a synergistic cycle. Improvements in the model's reasoning and interpretation of safety rules allow it to produce better reasoning data under safety rule prompts, which is then utilized for further training. Experiments show that STAR-S effectively defends against jailbreak attacks, outperforming baselines. Code is available at: https://github.com/pikepokenew/STAR_S.git.
Thinking with Video: Video Generation as a Promising Multimodal Reasoning Paradigm
Nov 06, 2025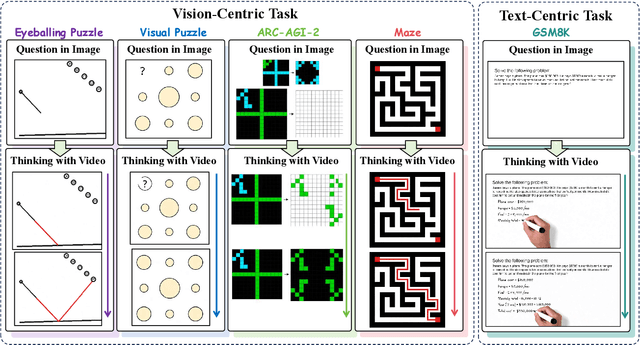
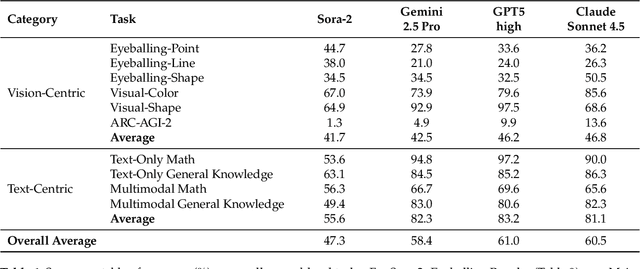
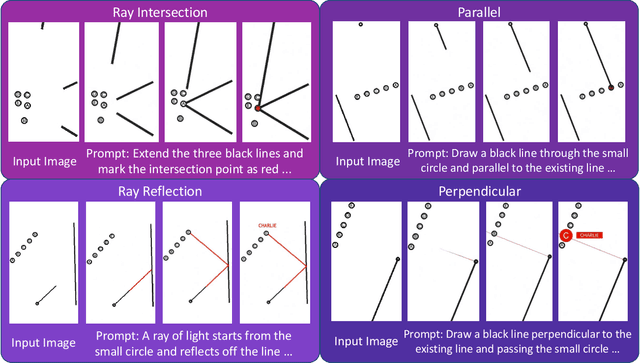

"Thinking with Text" and "Thinking with Images" paradigm significantly improve the reasoning ability of large language models (LLMs) and Vision Language Models (VLMs). However, these paradigms have inherent limitations. (1) Images capture only single moments and fail to represent dynamic processes or continuous changes, and (2) The separation of text and vision as distinct modalities, hindering unified multimodal understanding and generation. To overcome these limitations, we introduce "Thinking with Video", a new paradigm that leverages video generation models, such as Sora-2, to bridge visual and textual reasoning in a unified temporal framework. To support this exploration, we developed the Video Thinking Benchmark (VideoThinkBench). VideoThinkBench encompasses two task categories: (1) vision-centric tasks (e.g., Eyeballing Puzzles), and (2) text-centric tasks (e.g., subsets of GSM8K, MMMU). Our evaluation establishes Sora-2 as a capable reasoner. On vision-centric tasks, Sora-2 is generally comparable to state-of-the-art (SOTA) VLMs, and even surpasses VLMs on several tasks, such as Eyeballing Games. On text-centric tasks, Sora-2 achieves 92% accuracy on MATH, and 75.53% accuracy on MMMU. Furthermore, we systematically analyse the source of these abilities. We also find that self-consistency and in-context learning can improve Sora-2's performance. In summary, our findings demonstrate that the video generation model is the potential unified multimodal understanding and generation model, positions "thinking with video" as a unified multimodal reasoning paradigm.
When Personalization Tricks Detectors: The Feature-Inversion Trap in Machine-Generated Text Detection
Oct 14, 2025



Large language models (LLMs) have grown more powerful in language generation, producing fluent text and even imitating personal style. Yet, this ability also heightens the risk of identity impersonation. To the best of our knowledge, no prior work has examined personalized machine-generated text (MGT) detection. In this paper, we introduce \dataset, the first benchmark for evaluating detector robustness in personalized settings, built from literary and blog texts paired with their LLM-generated imitations. Our experimental results demonstrate large performance gaps across detectors in personalized settings: some state-of-the-art models suffer significant drops. We attribute this limitation to the \textit{feature-inversion trap}, where features that are discriminative in general domains become inverted and misleading when applied to personalized text. Based on this finding, we propose \method, a simple and reliable way to predict detector performance changes in personalized settings. \method identifies latent directions corresponding to inverted features and constructs probe datasets that differ primarily along these features to evaluate detector dependence. Our experiments show that \method can accurately predict both the direction and the magnitude of post-transfer changes, showing 85\% correlation with the actual performance gaps. We hope that this work will encourage further research on personalized text detection.
ManipLVM-R1: Reinforcement Learning for Reasoning in Embodied Manipulation with Large Vision-Language Models
May 22, 2025Large Vision-Language Models (LVLMs) have recently advanced robotic manipulation by leveraging vision for scene perception and language for instruction following. However, existing methods rely heavily on costly human-annotated training datasets, which limits their generalization and causes them to struggle in out-of-domain (OOD) scenarios, reducing real-world adaptability. To address these challenges, we propose ManipLVM-R1, a novel reinforcement learning framework that replaces traditional supervision with Reinforcement Learning using Verifiable Rewards (RLVR). By directly optimizing for task-aligned outcomes, our method enhances generalization and physical reasoning while removing the dependence on costly annotations. Specifically, we design two rule-based reward functions targeting key robotic manipulation subtasks: an Affordance Perception Reward to enhance localization of interaction regions, and a Trajectory Match Reward to ensure the physical plausibility of action paths. These rewards provide immediate feedback and impose spatial-logical constraints, encouraging the model to go beyond shallow pattern matching and instead learn deeper, more systematic reasoning about physical interactions.
Audio Jailbreak: An Open Comprehensive Benchmark for Jailbreaking Large Audio-Language Models
May 21, 2025



The rise of Large Audio Language Models (LAMs) brings both potential and risks, as their audio outputs may contain harmful or unethical content. However, current research lacks a systematic, quantitative evaluation of LAM safety especially against jailbreak attacks, which are challenging due to the temporal and semantic nature of speech. To bridge this gap, we introduce AJailBench, the first benchmark specifically designed to evaluate jailbreak vulnerabilities in LAMs. We begin by constructing AJailBench-Base, a dataset of 1,495 adversarial audio prompts spanning 10 policy-violating categories, converted from textual jailbreak attacks using realistic text to speech synthesis. Using this dataset, we evaluate several state-of-the-art LAMs and reveal that none exhibit consistent robustness across attacks. To further strengthen jailbreak testing and simulate more realistic attack conditions, we propose a method to generate dynamic adversarial variants. Our Audio Perturbation Toolkit (APT) applies targeted distortions across time, frequency, and amplitude domains. To preserve the original jailbreak intent, we enforce a semantic consistency constraint and employ Bayesian optimization to efficiently search for perturbations that are both subtle and highly effective. This results in AJailBench-APT, an extended dataset of optimized adversarial audio samples. Our findings demonstrate that even small, semantically preserved perturbations can significantly reduce the safety performance of leading LAMs, underscoring the need for more robust and semantically aware defense mechanisms.