 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLess Languages, Less Tokens: An Efficient Unified Logic Cross-lingual Chain-of-Thought Reasoning Framework
Apr 22, 2026Cross-lingual chain-of-thought (XCoT) with self-consistency markedly enhances multilingual reasoning, yet existing methods remain costly due to extensive sampling of full trajectories across languages. Moreover, multilingual LLM representations vary strongly by language, hindering direct feature comparisons and effective pruning. Motivated by this, we introduce UL-XCoT, the first efficient unified logic cross-lingual reasoning framework that minimizes redundancy in token usage and latency, yielding the greatest efficiency under limited sampling budgets during inference. Specifically, UL-XCoT (1) achieves less languages by selecting, per query, a small candidate language set in a language-invariant unified logic space, (2) enables less tokens by monitoring logic-space trajectory dynamics during decoding to prune low-quality reasoning paths, and (3) aggregates the remaining high-quality trajectories via voting. Experiments on PolyMath across 18 languages and MMLU-ProX-Lite across 29 languages with DeepSeek-R1-DistillQwen-7B demonstrate that UL-XCoT achieves competitive accuracy while sharply cutting over 50% decoding token cost versus prior sampling baselines. UL-XCoT also delivers more stable gains on low-resource languages, underscoring consistently superior robustness where standard XCoT self-consistency method fails.
OMIBench: Benchmarking Olympiad-Level Multi-Image Reasoning in Large Vision-Language Model
Apr 22, 2026Large vision-language models (LVLMs) have made substantial advances in reasoning tasks at the Olympiad level. Nevertheless, current Olympiad-level multimodal reasoning benchmarks for these models often emphasize single-image analysis and fail to exploit contextual information across multiple images. We present OMIBench, a benchmark designed to evaluate Olympiad-level reasoning when the required evidence is distributed over multiple images. It contains problems from biology, chemistry, mathematics, and physics Olympiads, together with manually annotated rationales and evaluation protocols for both exact and semantic answer matching. Across extensive experiments on OMIBench, we observe meaningful performance gaps in existing models. Even the strongest LVLMs, such as Gemini-3-Pro, attain only about 50% on the benchmark. These results position OMIBench as a focused resources for studying and improving multi-image reasoning in LVLMs.
Let's Think with Images Efficiently! An Interleaved-Modal Chain-of-Thought Reasoning Framework with Dynamic and Precise Visual Thoughts
Mar 23, 2026Recently, Interleaved-modal Chain-of-Thought (ICoT) reasoning has achieved remarkable success by leveraging both multimodal inputs and outputs, attracting increasing attention. While achieving promising performance, current ICoT methods still suffer from two major limitations: (1) Static Visual Thought Positioning, which statically inserts visual information at fixed steps, resulting in inefficient and inflexible reasoning; and (2) Broken Visual Thought Representation, which involves discontinuous and semantically incoherent visual tokens. To address these limitations, we introduce Interleaved-modal Chain-of-Thought reasoning with Dynamic and Precise Visual Thoughts (DaP-ICoT), which incorporates two key components: (1) Dynamic Visual Thought Integration adaptively introduces visual inputs based on reasoning needs, reducing redundancy and improving efficiency. (2) Precise Visual Thought Guidance ensures visual semantically coherent and contextually aligned representations. Experiments across multiple benchmarks and models demonstrate that DaP-ICoT achieves state-of-the-art performance. In addition, DaP-ICoT significantly reduces the number of inserted images, leading to a 72.6% decrease in token consumption, enabling more efficient ICoT reasoning.
AI Can Learn Scientific Taste
Mar 15, 2026Great scientists have strong judgement and foresight, closely tied to what we call scientific taste. Here, we use the term to refer to the capacity to judge and propose research ideas with high potential impact. However, most relative research focuses on improving an AI scientist's executive capability, while enhancing an AI's scientific taste remains underexplored. In this work, we propose Reinforcement Learning from Community Feedback (RLCF), a training paradigm that uses large-scale community signals as supervision, and formulate scientific taste learning as a preference modeling and alignment problem. For preference modeling, we train Scientific Judge on 700K field- and time-matched pairs of high- vs. low-citation papers to judge ideas. For preference alignment, using Scientific Judge as a reward model, we train a policy model, Scientific Thinker, to propose research ideas with high potential impact. Experiments show Scientific Judge outperforms SOTA LLMs (e.g., GPT-5.2, Gemini 3 Pro) and generalizes to future-year test, unseen fields, and peer-review preference. Furthermore, Scientific Thinker proposes research ideas with higher potential impact than baselines. Our findings show that AI can learn scientific taste, marking a key step toward reaching human-level AI scientists.
BABE: Biology Arena BEnchmark
Feb 05, 2026The rapid evolution of large language models (LLMs) has expanded their capabilities from basic dialogue to advanced scientific reasoning. However, existing benchmarks in biology often fail to assess a critical skill required of researchers: the ability to integrate experimental results with contextual knowledge to derive meaningful conclusions. To address this gap, we introduce BABE(Biology Arena BEnchmark), a comprehensive benchmark designed to evaluate the experimental reasoning capabilities of biological AI systems. BABE is uniquely constructed from peer-reviewed research papers and real-world biological studies, ensuring that tasks reflect the complexity and interdisciplinary nature of actual scientific inquiry. BABE challenges models to perform causal reasoning and cross-scale inference. Our benchmark provides a robust framework for assessing how well AI systems can reason like practicing scientists, offering a more authentic measure of their potential to contribute to biological research.
OffSeeker: Online Reinforcement Learning Is Not All You Need for Deep Research Agents
Jan 26, 2026Deep research agents have shown remarkable potential in handling long-horizon tasks. However, state-of-the-art performance typically relies on online reinforcement learning (RL), which is financially expensive due to extensive API calls. While offline training offers a more efficient alternative, its progress is hindered by the scarcity of high-quality research trajectories. In this paper, we demonstrate that expensive online reinforcement learning is not all you need to build powerful research agents. To bridge this gap, we introduce a fully open-source suite designed for effective offline training. Our core contributions include DeepForge, a ready-to-use task synthesis framework that generates large-scale research queries without heavy preprocessing; and a curated collection of 66k QA pairs, 33k SFT trajectories, and 21k DPO pairs. Leveraging these resources, we train OffSeeker (8B), a model developed entirely offline. Extensive evaluations across six benchmarks show that OffSeeker not only leads among similar-sized agents but also remains competitive with 30B-parameter systems trained via heavy online RL.
The Molecular Structure of Thought: Mapping the Topology of Long Chain-of-Thought Reasoning
Jan 13, 2026Large language models (LLMs) often fail to learn effective long chain-of-thought (Long CoT) reasoning from human or non-Long-CoT LLMs imitation. To understand this, we propose that effective and learnable Long CoT trajectories feature stable molecular-like structures in unified view, which are formed by three interaction types: Deep-Reasoning (covalent-like), Self-Reflection (hydrogen-bond-like), and Self-Exploration (van der Waals-like). Analysis of distilled trajectories reveals these structures emerge from Long CoT fine-tuning, not keyword imitation. We introduce Effective Semantic Isomers and show that only bonds promoting fast entropy convergence support stable Long CoT learning, while structural competition impairs training. Drawing on these findings, we present Mole-Syn, a distribution-transfer-graph method that guides synthesis of effective Long CoT structures, boosting performance and RL stability across benchmarks.
Agent2World: Learning to Generate Symbolic World Models via Adaptive Multi-Agent Feedback
Dec 26, 2025Symbolic world models (e.g., PDDL domains or executable simulators) are central to model-based planning, but training LLMs to generate such world models is limited by the lack of large-scale verifiable supervision. Current approaches rely primarily on static validation methods that fail to catch behavior-level errors arising from interactive execution. In this paper, we propose Agent2World, a tool-augmented multi-agent framework that achieves strong inference-time world-model generation and also serves as a data engine for supervised fine-tuning, by grounding generation in multi-agent feedback. Agent2World follows a three-stage pipeline: (i) A Deep Researcher agent performs knowledge synthesis by web searching to address specification gaps; (ii) A Model Developer agent implements executable world models; And (iii) a specialized Testing Team conducts adaptive unit testing and simulation-based validation. Agent2World demonstrates superior inference-time performance across three benchmarks spanning both Planning Domain Definition Language (PDDL) and executable code representations, achieving consistent state-of-the-art results. Beyond inference, Testing Team serves as an interactive environment for the Model Developer, providing behavior-aware adaptive feedback that yields multi-turn training trajectories. The model fine-tuned on these trajectories substantially improves world-model generation, yielding an average relative gain of 30.95% over the same model before training. Project page: https://agent2world.github.io.
Thinking with Video: Video Generation as a Promising Multimodal Reasoning Paradigm
Nov 06, 2025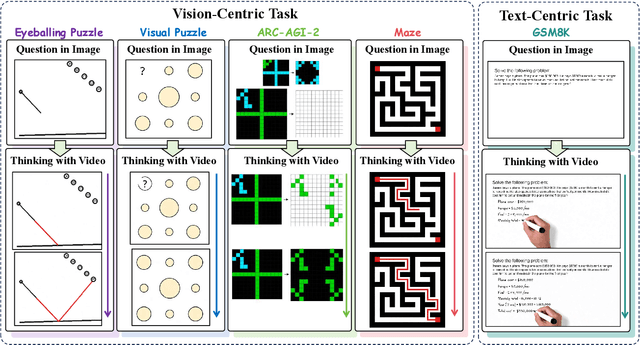
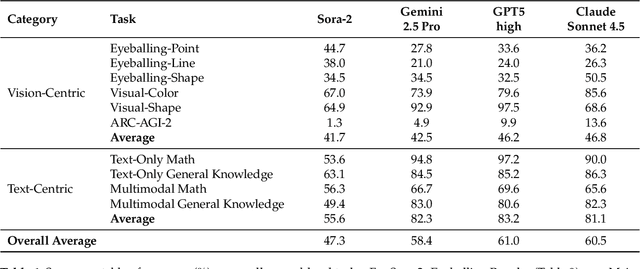
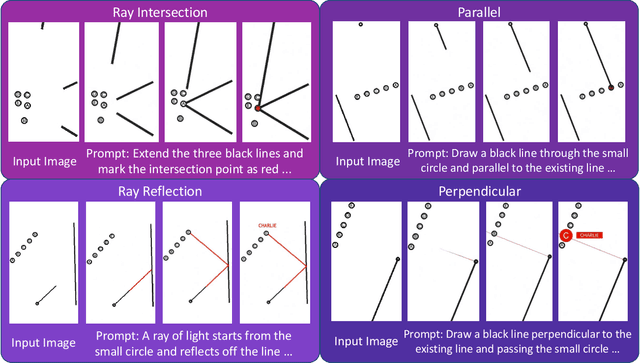

"Thinking with Text" and "Thinking with Images" paradigm significantly improve the reasoning ability of large language models (LLMs) and Vision Language Models (VLMs). However, these paradigms have inherent limitations. (1) Images capture only single moments and fail to represent dynamic processes or continuous changes, and (2) The separation of text and vision as distinct modalities, hindering unified multimodal understanding and generation. To overcome these limitations, we introduce "Thinking with Video", a new paradigm that leverages video generation models, such as Sora-2, to bridge visual and textual reasoning in a unified temporal framework. To support this exploration, we developed the Video Thinking Benchmark (VideoThinkBench). VideoThinkBench encompasses two task categories: (1) vision-centric tasks (e.g., Eyeballing Puzzles), and (2) text-centric tasks (e.g., subsets of GSM8K, MMMU). Our evaluation establishes Sora-2 as a capable reasoner. On vision-centric tasks, Sora-2 is generally comparable to state-of-the-art (SOTA) VLMs, and even surpasses VLMs on several tasks, such as Eyeballing Games. On text-centric tasks, Sora-2 achieves 92% accuracy on MATH, and 75.53% accuracy on MMMU. Furthermore, we systematically analyse the source of these abilities. We also find that self-consistency and in-context learning can improve Sora-2's performance. In summary, our findings demonstrate that the video generation model is the potential unified multimodal understanding and generation model, positions "thinking with video" as a unified multimodal reasoning paradigm.
The Universal Landscape of Human Reasoning
Oct 24, 2025



Understanding how information is dynamically accumulated and transformed in human reasoning has long challenged cognitive psychology, philosophy, and artificial intelligence. Existing accounts, from classical logic to probabilistic models, illuminate aspects of output or individual modelling, but do not offer a unified, quantitative description of general human reasoning dynamics. To solve this, we introduce Information Flow Tracking (IF-Track), that uses large language models (LLMs) as probabilistic encoder to quantify information entropy and gain at each reasoning step. Through fine-grained analyses across diverse tasks, our method is the first successfully models the universal landscape of human reasoning behaviors within a single metric space. We show that IF-Track captures essential reasoning features, identifies systematic error patterns, and characterizes individual differences. Applied to discussion of advanced psychological theory, we first reconcile single- versus dual-process theories in IF-Track and discover the alignment of artificial and human cognition and how LLMs reshaping human reasoning process. This approach establishes a quantitative bridge between theory and measurement, offering mechanistic insights into the architecture of reasoning.