 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUtility-Aware Data Pricing: Token-Level Quality and Empirical Training Gain for LLMs
Apr 24, 2026Traditional data valuation methods based on ``row-count $\times$ quality coefficient'' paradigms fail to capture the nuanced, nonlinear contributions that data makes to Large Language Model (LLM) capabilities. This paper presents a dynamic data valuation framework that transitions from static accounting to utility-based pricing. Our approach operates on three layers: (1) token-level information density metrics using Shannon entropy and Data Quality Scores; (2) empirical training gain measurement through influence functions, proxy model strategies, and Data Shapley values; and (3) cryptographic verifiability through hash-based commitments, Merkle trees, and a tamper-evident training ledger. We provide comprehensive experimental validation on three real domains (instruction following, mathematical reasoning, and code summarization), demonstrating that proxy-based empirical gain achieves near-perfect ranking alignment with realized utility, substantially outperforming row-count and token-count baselines. This framework enables a fair Data-as-a-Service economy where high-reasoning data is priced according to its actual contribution to model intelligence, while providing the transparency and auditability necessary for trustworthy data markets.
Graph-Aware Text-Only Backdoor Poisoning for Text-Attributed Graphs
Mar 20, 2026Many learning systems now use graph data in which each node also contains text, such as papers with abstracts or users with posts. Because these texts often come from open platforms, an attacker may be able to quietly poison a small part of the training data and later make the model produce wrong predictions on demand. This paper studies that risk in a realistic setting where the attacker edits only node text and does not change the graph structure. We propose TAGBD, a text-only backdoor attack for text-attributed graphs. TAGBD first finds training nodes that are easier to influence, then generates natural-looking trigger text with the help of a shadow graph model, and finally injects the trigger by either replacing the original text or appending a short phrase. Experiments on three benchmark datasets show that the attack is highly effective, transfers across different graph models, and remains strong under common defenses. These results demonstrate that text alone is a practical attack channel in graph learning systems and suggest that future defenses should inspect both graph links and node content.
DualSentinel: A Lightweight Framework for Detecting Targeted Attacks in Black-box LLM via Dual Entropy Lull Pattern
Mar 02, 2026Recent intelligent systems integrate powerful Large Language Models (LLMs) through APIs, but their trustworthiness may be critically undermined by targeted attacks like backdoor and prompt injection attacks, which secretly force LLMs to generate specific malicious sequences. Existing defensive approaches for such threats typically rely on high access rights, impose prohibitive costs, and hinder normal inference, rendering them impractical for real-world scenarios. To solve these limitations, we introduce DualSentinel, a lightweight and unified defense framework that can accurately and promptly detect the activation of targeted attacks alongside the LLM generation process. We first identify a characteristic of compromised LLMs, termed Entropy Lull: when a targeted attack successfully hijacks the generation process, the LLM exhibits a distinct period of abnormally low and stable token probability entropy, indicating it is following a fixed path rather than making creative choices. DualSentinel leverages this pattern by developing an innovative dual-check approach. It first employs a magnitude and trend-aware monitoring method to proactively and sensitively flag an entropy lull pattern at runtime. Upon such flagging, it triggers a lightweight yet powerful secondary verification based on task-flipping. An attack is confirmed only if the entropy lull pattern persists across both the original and the flipped task, proving that the LLM's output is coercively controlled. Extensive evaluations show that DualSentinel is both highly effective (superior detection accuracy with near-zero false positives) and remarkably efficient (negligible additional cost), offering a truly practical path toward securing deployed LLMs. The source code can be accessed at https://doi.org/10.5281/zenodo.18479273.
MOVA: Towards Scalable and Synchronized Video-Audio Generation
Feb 09, 2026Audio is indispensable for real-world video, yet generation models have largely overlooked audio components. Current approaches to producing audio-visual content often rely on cascaded pipelines, which increase cost, accumulate errors, and degrade overall quality. While systems such as Veo 3 and Sora 2 emphasize the value of simultaneous generation, joint multimodal modeling introduces unique challenges in architecture, data, and training. Moreover, the closed-source nature of existing systems limits progress in the field. In this work, we introduce MOVA (MOSS Video and Audio), an open-source model capable of generating high-quality, synchronized audio-visual content, including realistic lip-synced speech, environment-aware sound effects, and content-aligned music. MOVA employs a Mixture-of-Experts (MoE) architecture, with a total of 32B parameters, of which 18B are active during inference. It supports IT2VA (Image-Text to Video-Audio) generation task. By releasing the model weights and code, we aim to advance research and foster a vibrant community of creators. The released codebase features comprehensive support for efficient inference, LoRA fine-tuning, and prompt enhancement.
Multi-hop Reasoning via Early Knowledge Alignment
Dec 23, 2025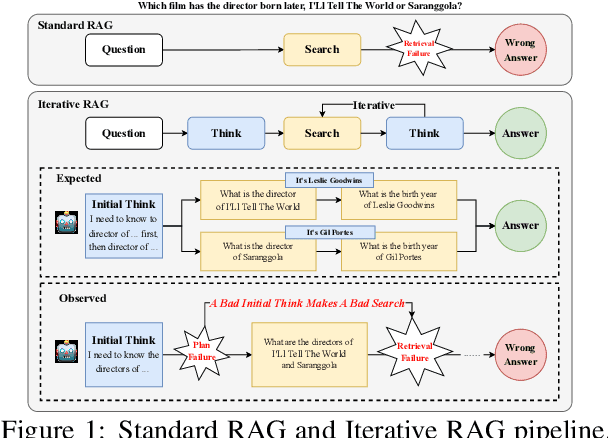

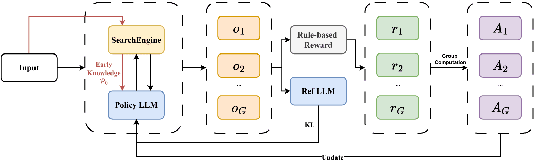
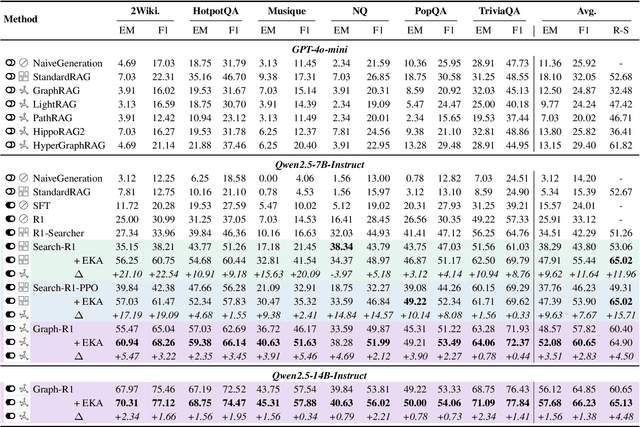
Retrieval-Augmented Generation (RAG) has emerged as a powerful paradigm for Large Language Models (LLMs) to address knowledge-intensive queries requiring domain-specific or up-to-date information. To handle complex multi-hop questions that are challenging for single-step retrieval, iterative RAG approaches incorporating reinforcement learning have been proposed. However, existing iterative RAG systems typically plan to decompose questions without leveraging information about the available retrieval corpus, leading to inefficient retrieval and reasoning chains that cascade into suboptimal performance. In this paper, we introduce Early Knowledge Alignment (EKA), a simple but effective module that aligns LLMs with retrieval set before planning in iterative RAG systems with contextually relevant retrieved knowledge. Extensive experiments on six standard RAG datasets demonstrate that by establishing a stronger reasoning foundation, EKA significantly improves retrieval precision, reduces cascading errors, and enhances both performance and efficiency. Our analysis from an entropy perspective demonstrate that incorporating early knowledge reduces unnecessary exploration during the reasoning process, enabling the model to focus more effectively on relevant information subsets. Moreover, EKA proves effective as a versatile, training-free inference strategy that scales seamlessly to large models. Generalization tests across diverse datasets and retrieval corpora confirm the robustness of our approach. Overall, EKA advances the state-of-the-art in iterative RAG systems while illuminating the critical interplay between structured reasoning and efficient exploration in reinforcement learning-augmented frameworks. The code is released at \href{https://github.com/yxzwang/EarlyKnowledgeAlignment}{Github}.
Terahertz Signal Coverage Enhancement in Hall Scenarios Based on Single-Hop and Dual-Hop Reconfigurable Intelligent Surfaces
Dec 16, 2025Terahertz (THz) communication offers ultra-high data rates and has emerged as a promising technology for future wireless networks. However, the inherently high free-space path loss of THz waves significantly limits the coverage range of THz communication systems. Therefore, extending the effective coverage area is a key challenge for the practical deployment of THz networks. Reconfigurable intelligent surfaces (RIS), which can dynamically manipulate electromagnetic wave propagation, provide a solution to enhance THz coverage. To investigate multi-RIS deployment scenarios, this work integrates an antenna array-based RIS model into the ray-tracing simulation platform. Using an indoor hall as a representative case study, the enhancement effects of single-hop and dual-hop RIS configurations on indoor signal coverage are evaluated under various deployment schemes. The developed framework offers valuable insights and design references for optimizing RIS-assisted indoor THz communication and coverage estimation.
GUIDE: Gaussian Unified Instance Detection for Enhanced Obstacle Perception in Autonomous Driving
Nov 17, 2025In the realm of autonomous driving, accurately detecting surrounding obstacles is crucial for effective decision-making. Traditional methods primarily rely on 3D bounding boxes to represent these obstacles, which often fail to capture the complexity of irregularly shaped, real-world objects. To overcome these limitations, we present GUIDE, a novel framework that utilizes 3D Gaussians for instance detection and occupancy prediction. Unlike conventional occupancy prediction methods, GUIDE also offers robust tracking capabilities. Our framework employs a sparse representation strategy, using Gaussian-to-Voxel Splatting to provide fine-grained, instance-level occupancy data without the computational demands associated with dense voxel grids. Experimental validation on the nuScenes dataset demonstrates GUIDE's performance, with an instance occupancy mAP of 21.61, marking a 50\% improvement over existing methods, alongside competitive tracking capabilities. GUIDE establishes a new benchmark in autonomous perception systems, effectively combining precision with computational efficiency to better address the complexities of real-world driving environments.
MARAG-R1: Beyond Single Retriever via Reinforcement-Learned Multi-Tool Agentic Retrieval
Oct 31, 2025



Large Language Models (LLMs) excel at reasoning and generation but are inherently limited by static pretraining data, resulting in factual inaccuracies and weak adaptability to new information. Retrieval-Augmented Generation (RAG) addresses this issue by grounding LLMs in external knowledge; However, the effectiveness of RAG critically depends on whether the model can adequately access relevant information. Existing RAG systems rely on a single retriever with fixed top-k selection, restricting access to a narrow and static subset of the corpus. As a result, this single-retriever paradigm has become the primary bottleneck for comprehensive external information acquisition, especially in tasks requiring corpus-level reasoning. To overcome this limitation, we propose MARAG-R1, a reinforcement-learned multi-tool RAG framework that enables LLMs to dynamically coordinate multiple retrieval mechanisms for broader and more precise information access. MARAG-R1 equips the model with four retrieval tools -- semantic search, keyword search, filtering, and aggregation -- and learns both how and when to use them through a two-stage training process: supervised fine-tuning followed by reinforcement learning. This design allows the model to interleave reasoning and retrieval, progressively gathering sufficient evidence for corpus-level synthesis. Experiments on GlobalQA, HotpotQA, and 2WikiMultiHopQA demonstrate that MARAG-R1 substantially outperforms strong baselines and achieves new state-of-the-art results in corpus-level reasoning tasks.
Towards Global Retrieval Augmented Generation: A Benchmark for Corpus-Level Reasoning
Oct 30, 2025



Retrieval-augmented generation (RAG) has emerged as a leading approach to reducing hallucinations in large language models (LLMs). Current RAG evaluation benchmarks primarily focus on what we call local RAG: retrieving relevant chunks from a small subset of documents to answer queries that require only localized understanding within specific text chunks. However, many real-world applications require a fundamentally different capability -- global RAG -- which involves aggregating and analyzing information across entire document collections to derive corpus-level insights (for example, "What are the top 10 most cited papers in 2023?"). In this paper, we introduce GlobalQA -- the first benchmark specifically designed to evaluate global RAG capabilities, covering four core task types: counting, extremum queries, sorting, and top-k extraction. Through systematic evaluation across different models and baselines, we find that existing RAG methods perform poorly on global tasks, with the strongest baseline achieving only 1.51 F1 score. To address these challenges, we propose GlobalRAG, a multi-tool collaborative framework that preserves structural coherence through chunk-level retrieval, incorporates LLM-driven intelligent filters to eliminate noisy documents, and integrates aggregation modules for precise symbolic computation. On the Qwen2.5-14B model, GlobalRAG achieves 6.63 F1 compared to the strongest baseline's 1.51 F1, validating the effectiveness of our method.
R3-RAG: Learning Step-by-Step Reasoning and Retrieval for LLMs via Reinforcement Learning
May 26, 2025



Retrieval-Augmented Generation (RAG) integrates external knowledge with Large Language Models (LLMs) to enhance factual correctness and mitigate hallucination. However, dense retrievers often become the bottleneck of RAG systems due to their limited parameters compared to LLMs and their inability to perform step-by-step reasoning. While prompt-based iterative RAG attempts to address these limitations, it is constrained by human-designed workflows. To address these limitations, we propose $\textbf{R3-RAG}$, which uses $\textbf{R}$einforcement learning to make the LLM learn how to $\textbf{R}$eason and $\textbf{R}$etrieve step by step, thus retrieving comprehensive external knowledge and leading to correct answers. R3-RAG is divided into two stages. We first use cold start to make the model learn the manner of iteratively interleaving reasoning and retrieval. Then we use reinforcement learning to further harness its ability to better explore the external retrieval environment. Specifically, we propose two rewards for R3-RAG: 1) answer correctness for outcome reward, which judges whether the trajectory leads to a correct answer; 2) relevance-based document verification for process reward, encouraging the model to retrieve documents that are relevant to the user question, through which we can let the model learn how to iteratively reason and retrieve relevant documents to get the correct answer. Experimental results show that R3-RAG significantly outperforms baselines and can transfer well to different retrievers. We release R3-RAG at https://github.com/Yuan-Li-FNLP/R3-RAG.