 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Scientific Discovery in an Agentic Era
Jul 04, 2026Artificial intelligence has advanced scientific discovery, but most AI4Science systems remain fragmented tools that rely on humans to coordinate problem formulation, literature grounding, model use, simulation, validation, and knowledge reuse. This paper presents \textbf{SCION (Scientific Collaborative Innovation with Agentic Organizational Nexus)}, an agentic scientific operating system that acts as an \textbf{organizational nexus}. Through a Science Agent serving as a \textbf{Meta-Harness}, SCION connects scientific tasks, tools, agents, artifacts, and memory, transforming research into an executable, auditable, and reusable operational process. At its core is the \textbf{Research Execution Plan (REP)}, which compiles high-level scientific intent into staged objectives, dependencies, verification checkpoints, tool requirements, expected artifacts, and fallback conditions. SCION further integrates hierarchical multi-agent execution, profile-driven specialization, selective context construction, governed delegation, and layered epistemic memory to support long-horizon scientific work. We formulate discovery under SCION as \textbf{Target-conditioned Inverse Search} and extend it to hidden-target settings through batch active search under finite experimental budgets. Applications in materials analysis, molecule design, and protein or antibody screening, together with experiments on scientific reading, idea generation, molecule generation, and antibody screening, show that SCION outperforms existing autonomous research-agent baselines, especially in decomposition, verification, refinement, and memory reuse. Overall, SCION shifts AI from isolated tools toward a coordinated operational layer for traceable and reusable scientific innovation.
AI Can Learn Scientific Taste
Mar 15, 2026Great scientists have strong judgement and foresight, closely tied to what we call scientific taste. Here, we use the term to refer to the capacity to judge and propose research ideas with high potential impact. However, most relative research focuses on improving an AI scientist's executive capability, while enhancing an AI's scientific taste remains underexplored. In this work, we propose Reinforcement Learning from Community Feedback (RLCF), a training paradigm that uses large-scale community signals as supervision, and formulate scientific taste learning as a preference modeling and alignment problem. For preference modeling, we train Scientific Judge on 700K field- and time-matched pairs of high- vs. low-citation papers to judge ideas. For preference alignment, using Scientific Judge as a reward model, we train a policy model, Scientific Thinker, to propose research ideas with high potential impact. Experiments show Scientific Judge outperforms SOTA LLMs (e.g., GPT-5.2, Gemini 3 Pro) and generalizes to future-year test, unseen fields, and peer-review preference. Furthermore, Scientific Thinker proposes research ideas with higher potential impact than baselines. Our findings show that AI can learn scientific taste, marking a key step toward reaching human-level AI scientists.
Thinking with Video: Video Generation as a Promising Multimodal Reasoning Paradigm
Nov 06, 2025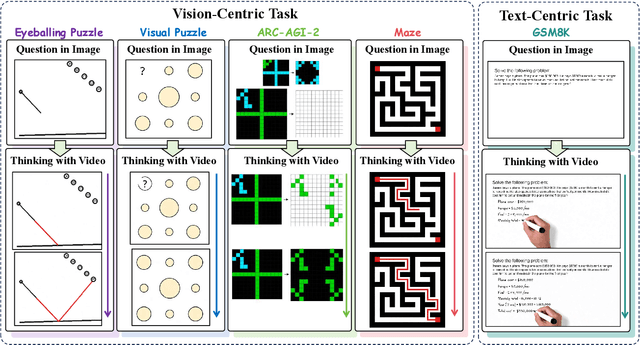
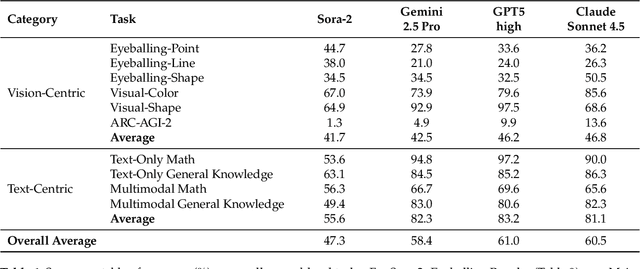
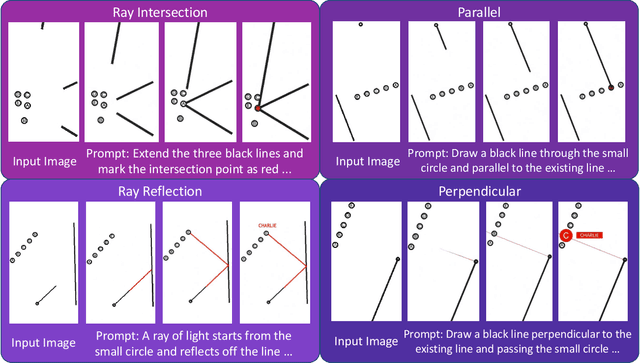

"Thinking with Text" and "Thinking with Images" paradigm significantly improve the reasoning ability of large language models (LLMs) and Vision Language Models (VLMs). However, these paradigms have inherent limitations. (1) Images capture only single moments and fail to represent dynamic processes or continuous changes, and (2) The separation of text and vision as distinct modalities, hindering unified multimodal understanding and generation. To overcome these limitations, we introduce "Thinking with Video", a new paradigm that leverages video generation models, such as Sora-2, to bridge visual and textual reasoning in a unified temporal framework. To support this exploration, we developed the Video Thinking Benchmark (VideoThinkBench). VideoThinkBench encompasses two task categories: (1) vision-centric tasks (e.g., Eyeballing Puzzles), and (2) text-centric tasks (e.g., subsets of GSM8K, MMMU). Our evaluation establishes Sora-2 as a capable reasoner. On vision-centric tasks, Sora-2 is generally comparable to state-of-the-art (SOTA) VLMs, and even surpasses VLMs on several tasks, such as Eyeballing Games. On text-centric tasks, Sora-2 achieves 92% accuracy on MATH, and 75.53% accuracy on MMMU. Furthermore, we systematically analyse the source of these abilities. We also find that self-consistency and in-context learning can improve Sora-2's performance. In summary, our findings demonstrate that the video generation model is the potential unified multimodal understanding and generation model, positions "thinking with video" as a unified multimodal reasoning paradigm.