 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Rewarding Vision-Language Model via Reasoning Decomposition
Aug 27, 2025



Vision-Language Models (VLMs) often suffer from visual hallucinations, saying things that are not actually in the image, and language shortcuts, where they skip the visual part and just rely on text priors. These issues arise because most post-training methods for VLMs rely on simple verifiable answer matching and supervise only final outputs, leaving intermediate visual reasoning without explicit guidance. As a result, VLMs receive sparse visual signals and often learn to prioritize language-based reasoning over visual perception. To mitigate this, some existing methods add visual supervision using human annotations or distilled labels from external large models. However, human annotations are labor-intensive and costly, and because external signals cannot adapt to the evolving policy, they cause distributional shifts that can lead to reward hacking. In this paper, we introduce Vision-SR1, a self-rewarding method that improves visual reasoning without relying on external visual supervisions via reinforcement learning. Vision-SR1 decomposes VLM reasoning into two stages: visual perception and language reasoning. The model is first prompted to produce self-contained visual perceptions that are sufficient to answer the question without referring back the input image. To validate this self-containment, the same VLM model is then re-prompted to perform language reasoning using only the generated perception as input to compute reward. This self-reward is combined with supervision on final outputs, providing a balanced training signal that strengthens both visual perception and language reasoning. Our experiments demonstrate that Vision-SR1 improves visual reasoning, mitigates visual hallucinations, and reduces reliance on language shortcuts across diverse vision-language tasks.
R-Zero: Self-Evolving Reasoning LLM from Zero Data
Aug 07, 2025
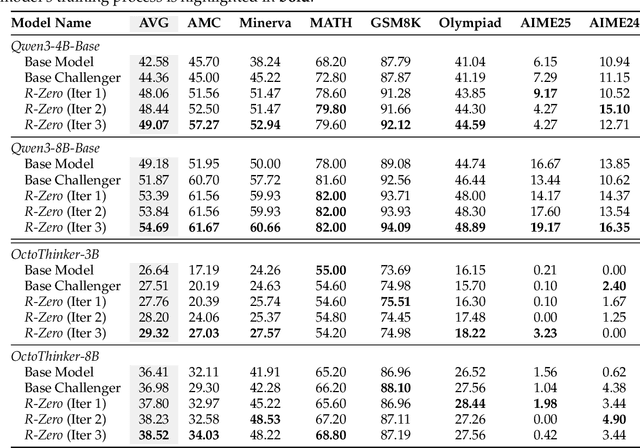

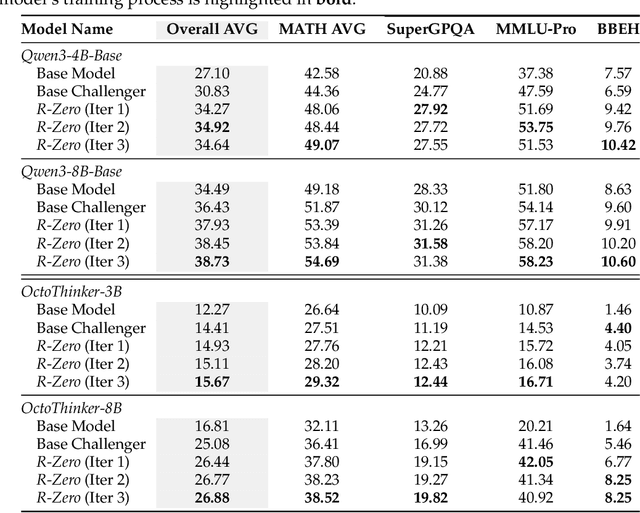
Self-evolving Large Language Models (LLMs) offer a scalable path toward super-intelligence by autonomously generating, refining, and learning from their own experiences. However, existing methods for training such models still rely heavily on vast human-curated tasks and labels, typically via fine-tuning or reinforcement learning, which poses a fundamental bottleneck to advancing AI systems toward capabilities beyond human intelligence. To overcome this limitation, we introduce R-Zero, a fully autonomous framework that generates its own training data from scratch. Starting from a single base LLM, R-Zero initializes two independent models with distinct roles, a Challenger and a Solver. These models are optimized separately and co-evolve through interaction: the Challenger is rewarded for proposing tasks near the edge of the Solver capability, and the Solver is rewarded for solving increasingly challenging tasks posed by the Challenger. This process yields a targeted, self-improving curriculum without any pre-existing tasks and labels. Empirically, R-Zero substantially improves reasoning capability across different backbone LLMs, e.g., boosting the Qwen3-4B-Base by +6.49 on math-reasoning benchmarks and +7.54 on general-domain reasoning benchmarks.
KnowRL: Exploring Knowledgeable Reinforcement Learning for Factuality
Jun 24, 2025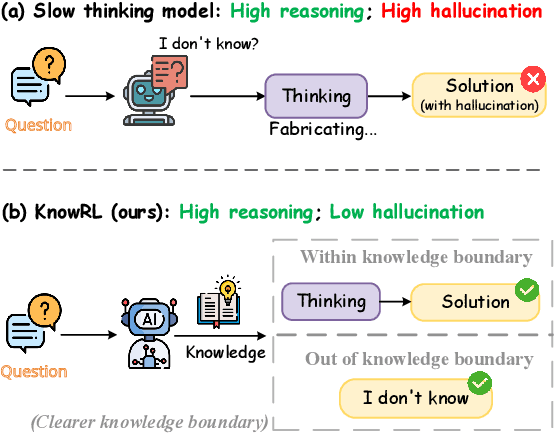
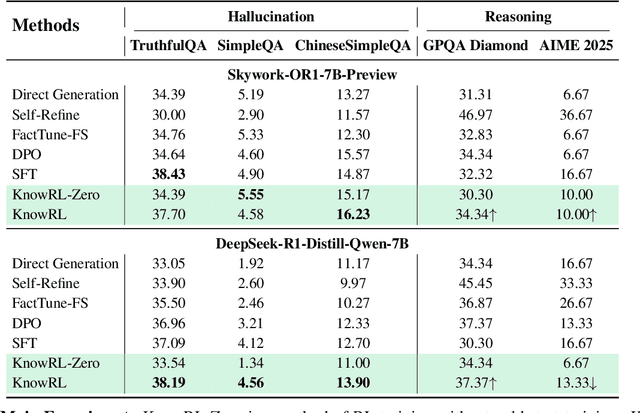
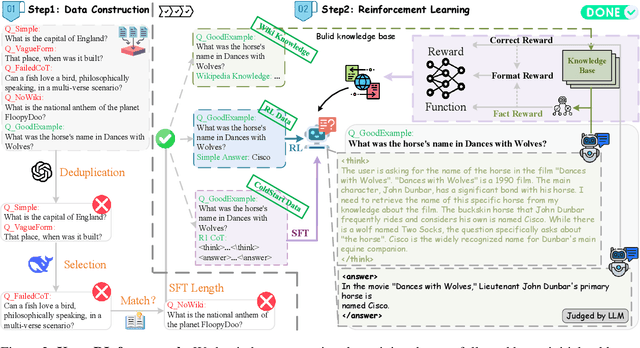
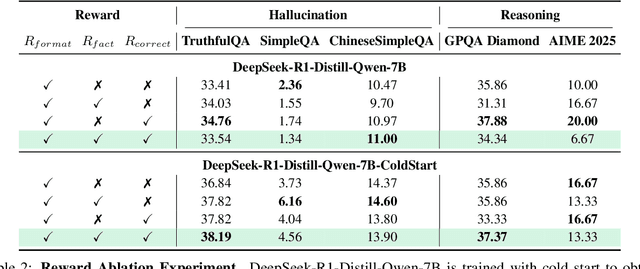
Large Language Models (LLMs), particularly slow-thinking models, often exhibit severe hallucination, outputting incorrect content due to an inability to accurately recognize knowledge boundaries during reasoning. While Reinforcement Learning (RL) can enhance complex reasoning abilities, its outcome-oriented reward mechanism often lacks factual supervision over the thinking process, further exacerbating the hallucination problem. To address the high hallucination in slow-thinking models, we propose Knowledge-enhanced RL, KnowRL. KnowRL guides models to perform fact-based slow thinking by integrating a factuality reward, based on knowledge verification, into the RL training process, helping them recognize their knowledge boundaries. KnowRL guides models to perform fact-based slow thinking by integrating a factuality reward, based on knowledge verification, into the RL training process, helping them recognize their knowledge boundaries. This targeted factual input during RL training enables the model to learn and internalize fact-based reasoning strategies. By directly rewarding adherence to facts within the reasoning steps, KnowRL fosters a more reliable thinking process. Experimental results on three hallucination evaluation datasets and two reasoning evaluation datasets demonstrate that KnowRL effectively mitigates hallucinations in slow-thinking models while maintaining their original strong reasoning capabilities. Our code is available at https://github.com/zjunlp/KnowRL.
LocoTouch: Learning Dexterous Quadrupedal Transport with Tactile Sensing
May 29, 2025Quadrupedal robots have demonstrated remarkable agility and robustness in traversing complex terrains. However, they remain limited in performing object interactions that require sustained contact. In this work, we present LocoTouch, a system that equips quadrupedal robots with tactile sensing to address a challenging task in this category: long-distance transport of unsecured cylindrical objects, which typically requires custom mounting mechanisms to maintain stability. For efficient large-area tactile sensing, we design a high-density distributed tactile sensor array that covers the entire back of the robot. To effectively leverage tactile feedback for locomotion control, we develop a simulation environment with high-fidelity tactile signals, and train tactile-aware transport policies using a two-stage learning pipeline. Furthermore, we design a novel reward function to promote stable, symmetric, and frequency-adaptive locomotion gaits. After training in simulation, LocoTouch transfers zero-shot to the real world, reliably balancing and transporting a wide range of unsecured, cylindrical everyday objects with broadly varying sizes and weights. Thanks to the responsiveness of the tactile sensor and the adaptive gait reward, LocoTouch can robustly balance objects with slippery surfaces over long distances, or even under severe external perturbations.
VScan: Rethinking Visual Token Reduction for Efficient Large Vision-Language Models
May 28, 2025Recent Large Vision-Language Models (LVLMs) have advanced multi-modal understanding by incorporating finer-grained visual perception and encoding. However, such methods incur significant computational costs due to longer visual token sequences, posing challenges for real-time deployment. To mitigate this, prior studies have explored pruning unimportant visual tokens either at the output layer of the visual encoder or at the early layers of the language model. In this work, we revisit these design choices and reassess their effectiveness through comprehensive empirical studies of how visual tokens are processed throughout the visual encoding and language decoding stages. Guided by these insights, we propose VScan, a two-stage visual token reduction framework that addresses token redundancy by: (1) integrating complementary global and local scans with token merging during visual encoding, and (2) introducing pruning at intermediate layers of the language model. Extensive experimental results across four LVLMs validate the effectiveness of VScan in accelerating inference and demonstrate its superior performance over current state-of-the-arts on sixteen benchmarks. Notably, when applied to LLaVA-NeXT-7B, VScan achieves a 2.91$\times$ speedup in prefilling and a 10$\times$ reduction in FLOPs, while retaining 95.4% of the original performance.
S2R-Bench: A Sim-to-Real Evaluation Benchmark for Autonomous Driving
May 24, 2025



Safety is a long-standing and the final pursuit in the development of autonomous driving systems, with a significant portion of safety challenge arising from perception. How to effectively evaluate the safety as well as the reliability of perception algorithms is becoming an emerging issue. Despite its critical importance, existing perception methods exhibit a limitation in their robustness, primarily due to the use of benchmarks are entierly simulated, which fail to align predicted results with actual outcomes, particularly under extreme weather conditions and sensor anomalies that are prevalent in real-world scenarios. To fill this gap, in this study, we propose a Sim-to-Real Evaluation Benchmark for Autonomous Driving (S2R-Bench). We collect diverse sensor anomaly data under various road conditions to evaluate the robustness of autonomous driving perception methods in a comprehensive and realistic manner. This is the first corruption robustness benchmark based on real-world scenarios, encompassing various road conditions, weather conditions, lighting intensities, and time periods. By comparing real-world data with simulated data, we demonstrate the reliability and practical significance of the collected data for real-world applications. We hope that this dataset will advance future research and contribute to the development of more robust perception models for autonomous driving. This dataset is released on https://github.com/adept-thu/S2R-Bench.
Bidirectional LMs are Better Knowledge Memorizers? A Benchmark for Real-world Knowledge Injection
May 18, 2025Despite significant advances in large language models (LLMs), their knowledge memorization capabilities remain underexplored, due to the lack of standardized and high-quality test ground. In this paper, we introduce a novel, real-world and large-scale knowledge injection benchmark that evolves continuously over time without requiring human intervention. Specifically, we propose WikiDYK, which leverages recently-added and human-written facts from Wikipedia's "Did You Know..." entries. These entries are carefully selected by expert Wikipedia editors based on criteria such as verifiability and clarity. Each entry is converted into multiple question-answer pairs spanning diverse task formats from easy cloze prompts to complex multi-hop questions. WikiDYK contains 12,290 facts and 77,180 questions, which is also seamlessly extensible with future updates from Wikipedia editors. Extensive experiments using continued pre-training reveal a surprising insight: despite their prevalence in modern LLMs, Causal Language Models (CLMs) demonstrate significantly weaker knowledge memorization capabilities compared to Bidirectional Language Models (BiLMs), exhibiting a 23% lower accuracy in terms of reliability. To compensate for the smaller scales of current BiLMs, we introduce a modular collaborative framework utilizing ensembles of BiLMs as external knowledge repositories to integrate with LLMs. Experiment shows that our framework further improves the reliability accuracy by up to 29.1%.
MMLongBench: Benchmarking Long-Context Vision-Language Models Effectively and Thoroughly
May 15, 2025The rapid extension of context windows in large vision-language models has given rise to long-context vision-language models (LCVLMs), which are capable of handling hundreds of images with interleaved text tokens in a single forward pass. In this work, we introduce MMLongBench, the first benchmark covering a diverse set of long-context vision-language tasks, to evaluate LCVLMs effectively and thoroughly. MMLongBench is composed of 13,331 examples spanning five different categories of downstream tasks, such as Visual RAG and Many-Shot ICL. It also provides broad coverage of image types, including various natural and synthetic images. To assess the robustness of the models to different input lengths, all examples are delivered at five standardized input lengths (8K-128K tokens) via a cross-modal tokenization scheme that combines vision patches and text tokens. Through a thorough benchmarking of 46 closed-source and open-source LCVLMs, we provide a comprehensive analysis of the current models' vision-language long-context ability. Our results show that: i) performance on a single task is a weak proxy for overall long-context capability; ii) both closed-source and open-source models face challenges in long-context vision-language tasks, indicating substantial room for future improvement; iii) models with stronger reasoning ability tend to exhibit better long-context performance. By offering wide task coverage, various image types, and rigorous length control, MMLongBench provides the missing foundation for diagnosing and advancing the next generation of LCVLMs.
STDArm: Transferring Visuomotor Policies From Static Data Training to Dynamic Robot Manipulation
Apr 26, 2025Recent advances in mobile robotic platforms like quadruped robots and drones have spurred a demand for deploying visuomotor policies in increasingly dynamic environments. However, the collection of high-quality training data, the impact of platform motion and processing delays, and limited onboard computing resources pose significant barriers to existing solutions. In this work, we present STDArm, a system that directly transfers policies trained under static conditions to dynamic platforms without extensive modifications. The core of STDArm is a real-time action correction framework consisting of: (1) an action manager to boost control frequency and maintain temporal consistency, (2) a stabilizer with a lightweight prediction network to compensate for motion disturbances, and (3) an online latency estimation module for calibrating system parameters. In this way, STDArm achieves centimeter-level precision in mobile manipulation tasks. We conduct comprehensive evaluations of the proposed STDArm on two types of robotic arms, four types of mobile platforms, and three tasks. Experimental results indicate that the STDArm enables real-time compensation for platform motion disturbances while preserving the original policy's manipulation capabilities, achieving centimeter-level operational precision during robot motion.
WebEvolver: Enhancing Web Agent Self-Improvement with Coevolving World Model
Apr 23, 2025Agent self-improvement, where the backbone Large Language Model (LLM) of the agent are trained on trajectories sampled autonomously based on their own policies, has emerged as a promising approach for enhancing performance. Recent advancements, particularly in web environments, face a critical limitation: their performance will reach a stagnation point during autonomous learning cycles, hindering further improvement. We argue that this stems from limited exploration of the web environment and insufficient exploitation of pre-trained web knowledge in LLMs. To improve the performance of self-improvement, we propose a novel framework that introduces a co-evolving World Model LLM. This world model predicts the next observation based on the current observation and action within the web environment. Leveraging LLMs' pretrained knowledge of abundant web content, the World Model serves dual roles: (1) as a virtual web server generating self-instructed training data to continuously refine the agent's policy, and (2) as an imagination engine during inference, enabling look-ahead simulation to guide action selection for the agent LLM. Experiments in real-world web environments (Mind2Web-Live, WebVoyager, and GAIA-web) show a 10% performance gain over existing self-evolving agents, demonstrating the efficacy and generalizability of our approach, without using any distillation from more powerful close-sourced models. Our work establishes the necessity of integrating world models into autonomous agent frameworks to unlock sustained adaptability.