 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnactToM: An Evolving Benchmark for Functional Theory of Mind in Embodied Agents
May 11, 2026Theory of Mind (ToM), the ability to track others epistemic state, makes humans efficient collaborators. AI agents need the same capacity in multi agent settings, yet existing benchmarks mostly test literal ToM by asking direct belief questions. The ability act optimally on implicit beliefs in embodied environments, called functional ToM, remains largely untested. We introduce EnactToM, an evolving benchmark of 300 embodied multi-agent tasks set in a 3D household with partial observability, private information, and constrained communication. Each task is formally verified for solvability and required epistemic depth, and new tasks are generated increase difficulty as models improve. On the hard split, all seven evaluated frontier models score 0.0% Pass^3 on functional task completion, while averaging 45.0% on literal belief probes. Manual analysis traces 93% of sampled failures to epistemic coordination breakdowns such as withheld information, ignored partner constraints, and misallocated messages, providing a concrete target for future work.
FAMA: Failure-Aware Meta-Agentic Framework for Open-Source LLMs in Interactive Tool Use Environments
Apr 28, 2026Large Language Models are being increasingly deployed as the decision-making core of autonomous agents capable of effecting change in external environments. Yet, in conversational benchmarks, which simulate real-world customer-centric issue resolution scenarios, these agents frequently fail due to the cascading effects of incorrect decision-making. These challenges are particularly pronounced for open-source LLMs with smaller parameter sizes, limited context windows, and constrained inference budgets, which contribute to increased error accumulation in agentic settings. To tackle these challenges, we present the Failure-Aware Meta-Agentic (FAMA) framework. FAMA operates in two stages: first, it analyzes failure trajectories from baseline agents to identify the most prevalent errors; second, it employs an orchestration mechanism that activates a minimal subset of specialized agents tailored to address these failures by injecting a targeted context for the tool-use agent before the decision-making step. Experiments across open-source LLMs demonstrate performance gains up to 27% across evaluation modes over standard baselines. These results highlight that targeted curation of context through specialized agents to address common failures is a valuable design principle for building reliable, multi-turn tool-use LLM agents that simulate real-world conversational scenarios.
AgentDS Technical Report: Benchmarking the Future of Human-AI Collaboration in Domain-Specific Data Science
Mar 19, 2026Data science plays a critical role in transforming complex data into actionable insights across numerous domains. Recent developments in large language models (LLMs) and artificial intelligence (AI) agents have significantly automated data science workflow. However, it remains unclear to what extent AI agents can match the performance of human experts on domain-specific data science tasks, and in which aspects human expertise continues to provide advantages. We introduce AgentDS, a benchmark and competition designed to evaluate both AI agents and human-AI collaboration performance in domain-specific data science. AgentDS consists of 17 challenges across six industries: commerce, food production, healthcare, insurance, manufacturing, and retail banking. We conducted an open competition involving 29 teams and 80 participants, enabling systematic comparison between human-AI collaborative approaches and AI-only baselines. Our results show that current AI agents struggle with domain-specific reasoning. AI-only baselines perform near or below the median of competition participants, while the strongest solutions arise from human-AI collaboration. These findings challenge the narrative of complete automation by AI and underscore the enduring importance of human expertise in data science, while illuminating directions for the next generation of AI. Visit the AgentDS website here: https://agentds.org/ and open source datasets here: https://huggingface.co/datasets/lainmn/AgentDS .
Context Bootstrapped Reinforcement Learning
Mar 19, 2026Reinforcement Learning from Verifiable Rewards (RLVR) suffers from exploration inefficiency, where models struggle to generate successful rollouts, resulting in minimal learning signal. This challenge is particularly severe for tasks that require the acquisition of novel reasoning patterns or domain-specific knowledge. To address this, we propose Context Bootstrapped Reinforcement Learning (CBRL), which augments RLVR training by stochastically prepending few-shot demonstrations to training prompts. The injection probability follows a curriculum that starts high to bootstrap early exploration, then anneals to zero so the model must ultimately succeed without assistance. This forces the policy to internalize reasoning patterns from the demonstrations rather than relying on them at test time. We validate CBRL across two model families and five Reasoning Gym tasks. Our results demonstrate that CBRL consistently improves success rate, provides better exploration efficiency, and is algorithm-agnostic. We further demonstrate CBRL's practical applicability on Q, a domain-specific programming language that diverges significantly from mainstream language conventions.
Can Agentic AI Match the Performance of Human Data Scientists?
Dec 24, 2025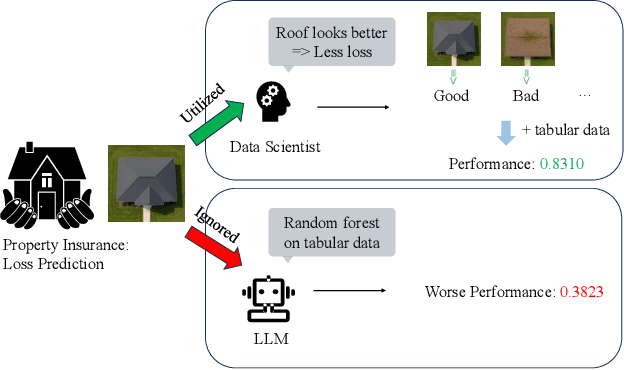

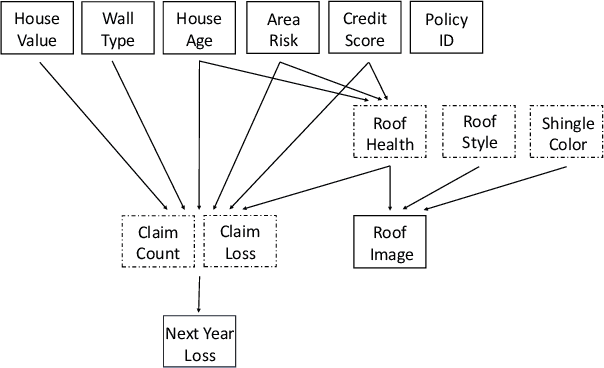

Data science plays a critical role in transforming complex data into actionable insights across numerous domains. Recent developments in large language models (LLMs) have significantly automated data science workflows, but a fundamental question persists: Can these agentic AI systems truly match the performance of human data scientists who routinely leverage domain-specific knowledge? We explore this question by designing a prediction task where a crucial latent variable is hidden in relevant image data instead of tabular features. As a result, agentic AI that generates generic codes for modeling tabular data cannot perform well, while human experts could identify the important hidden variable using domain knowledge. We demonstrate this idea with a synthetic dataset for property insurance. Our experiments show that agentic AI that relies on generic analytics workflow falls short of methods that use domain-specific insights. This highlights a key limitation of the current agentic AI for data science and underscores the need for future research to develop agentic AI systems that can better recognize and incorporate domain knowledge.
Dora: QoE-Aware Hybrid Parallelism for Distributed Edge AI
Dec 09, 2025



With the proliferation of edge AI applications, satisfying user quality of experience (QoE) requirements, such as model inference latency, has become a first class objective, as these models operate in resource constrained settings and directly interact with users. Yet, modern AI models routinely exceed the resource capacity of individual devices, necessitating distributed execution across heterogeneous devices over variable and contention prone networks. Existing planners for hybrid (e.g., data and pipeline) parallelism largely optimize for throughput or device utilization, overlooking QoE, leading to severe resource inefficiency (e.g., unnecessary energy drain) or QoE violations under runtime dynamics. We present Dora, a framework for QoE aware hybrid parallelism in distributed edge AI training and inference. Dora jointly optimizes heterogeneous computation, contention prone networks, and multi dimensional QoE objectives via three key mechanisms: (i) a heterogeneity aware model partitioner that determines and assigns model partitions across devices, forming a compact set of QoE compliant plans; (ii) a contention aware network scheduler that further refines these candidate plans by maximizing compute communication overlap; and (iii) a runtime adapter that adaptively composes multiple plans to maximize global efficiency while respecting overall QoEs. Across representative edge deployments, including smart homes, traffic analytics, and small edge clusters, Dora achieves 1.1--6.3 times faster execution and, alternatively, reduces energy consumption by 21--82 percent, all while maintaining QoE under runtime dynamics.
How Can Input Reformulation Improve Tool Usage Accuracy in a Complex Dynamic Environment? A Study on $τ$-bench
Aug 28, 2025Recent advances in reasoning and planning capabilities of large language models (LLMs) have enabled their potential as autonomous agents capable of tool use in dynamic environments. However, in multi-turn conversational environments like $\tau$-bench, these agents often struggle with consistent reasoning, adherence to domain-specific policies, and extracting correct information over a long horizon of tool-calls and conversation. To capture and mitigate these failures, we conduct a comprehensive manual analysis of the common errors occurring in the conversation trajectories. We then experiment with reformulations of inputs to the tool-calling agent for improvement in agent decision making. Finally, we propose the Input-Reformulation Multi-Agent (IRMA) framework, which automatically reformulates user queries augmented with relevant domain rules and tool suggestions for the tool-calling agent to focus on. The results show that IRMA significantly outperforms ReAct, Function Calling, and Self-Reflection by 16.1%, 12.7%, and 19.1%, respectively, in overall pass^5 scores. These findings highlight the superior reliability and consistency of IRMA compared to other methods in dynamic environments.
EXP-Bench: Can AI Conduct AI Research Experiments?
May 30, 2025



Automating AI research holds immense potential for accelerating scientific progress, yet current AI agents struggle with the complexities of rigorous, end-to-end experimentation. We introduce EXP-Bench, a novel benchmark designed to systematically evaluate AI agents on complete research experiments sourced from influential AI publications. Given a research question and incomplete starter code, EXP-Bench challenges AI agents to formulate hypotheses, design and implement experimental procedures, execute them, and analyze results. To enable the creation of such intricate and authentic tasks with high-fidelity, we design a semi-autonomous pipeline to extract and structure crucial experimental details from these research papers and their associated open-source code. With the pipeline, EXP-Bench curated 461 AI research tasks from 51 top-tier AI research papers. Evaluations of leading LLM-based agents, such as OpenHands and IterativeAgent on EXP-Bench demonstrate partial capabilities: while scores on individual experimental aspects such as design or implementation correctness occasionally reach 20-35%, the success rate for complete, executable experiments was a mere 0.5%. By identifying these bottlenecks and providing realistic step-by-step experiment procedures, EXP-Bench serves as a vital tool for future AI agents to improve their ability to conduct AI research experiments. EXP-Bench is open-sourced at https://github.com/Just-Curieous/Curie/tree/main/benchmark/exp_bench.
An Outlook on the Opportunities and Challenges of Multi-Agent AI Systems
May 23, 2025Multi-agent AI systems (MAS) offer a promising framework for distributed intelligence, enabling collaborative reasoning, planning, and decision-making across autonomous agents. This paper provides a systematic outlook on the current opportunities and challenges of MAS, drawing insights from recent advances in large language models (LLMs), federated optimization, and human-AI interaction. We formalize key concepts including agent topology, coordination protocols, and shared objectives, and identify major risks such as dependency, misalignment, and vulnerabilities arising from training data overlap. Through a biologically inspired simulation and comprehensive theoretical framing, we highlight critical pathways for developing robust, scalable, and secure MAS in real-world settings.
SafeKey: Amplifying Aha-Moment Insights for Safety Reasoning
May 22, 2025



Large Reasoning Models (LRMs) introduce a new generation paradigm of explicitly reasoning before answering, leading to remarkable improvements in complex tasks. However, they pose great safety risks against harmful queries and adversarial attacks. While recent mainstream safety efforts on LRMs, supervised fine-tuning (SFT), improve safety performance, we find that SFT-aligned models struggle to generalize to unseen jailbreak prompts. After thorough investigation of LRMs' generation, we identify a safety aha moment that can activate safety reasoning and lead to a safe response. This aha moment typically appears in the `key sentence', which follows models' query understanding process and can indicate whether the model will proceed safely. Based on these insights, we propose SafeKey, including two complementary objectives to better activate the safety aha moment in the key sentence: (1) a Dual-Path Safety Head to enhance the safety signal in the model's internal representations before the key sentence, and (2) a Query-Mask Modeling objective to improve the models' attention on its query understanding, which has important safety hints. Experiments across multiple safety benchmarks demonstrate that our methods significantly improve safety generalization to a wide range of jailbreak attacks and out-of-distribution harmful prompts, lowering the average harmfulness rate by 9.6\%, while maintaining general abilities. Our analysis reveals how SafeKey enhances safety by reshaping internal attention and improving the quality of hidden representations.