 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaskWAM: Unifying Mask Prompting and Prediction for World-Action Models
Jun 11, 2026World Action Models (WAMs) present a promising paradigm for robotic control via video prediction. However, current WAMs suffer from fundamental spatial bottlenecks: standard text inputs introduce referential ambiguity in cluttered scenes, while unstructured RGB predictions lack semantic grounding and remain biased by task-irrelevant backgrounds. To overcome these limitations, we introduce MaskWAM, an object-centric world-action model. By jointly integrating masks as both explicit inputs and predictions via a unified Mixture of Transformers (MoT), MaskWAM unlocks robust policy generalization. This design provides two key benefits: (1) predicting future masks yields object-centric semantic supervision that suppresses visual noise, significantly enhancing even standard text-conditioned WAMs; and (2) coupling this predictive supervision with first-frame visual prompts, such as target object masks, establishes a precise spatial anchor that substantially reduces language ambiguity. Crucially, as WAMs are inherently vision-driven architectures, direct mask conditioning yields substantially stronger guidance than text alone, establishing a precise and robust paradigm for manipulating unseen objects. Evaluations on LIBERO, RoboTwin, and real-world tasks demonstrate that MaskWAM significantly outperforms baselines in both language-clear and language-ambiguous tasks.
SeePhys Pro: Diagnosing Modality Transfer and Blind-Training Effects in Multimodal RLVR for Physics Reasoning
May 10, 2026We introduce SeePhys Pro, a fine-grained modality transfer benchmark that studies whether models preserve the same reasoning capability when critical information is progressively transferred from text to image. Unlike standard vision-essential benchmarks that evaluate a single input form, SeePhys Pro features four semantically aligned variants for each problem with progressively increasing visual elements. Our evaluation shows that current frontier models are far from representation-invariant reasoners: performance degrades on average as information moves from language to diagrams, with visual variable grounding as the most critical bottleneck. Motivated by this inference-time fragility, we further develop large training corpora for multimodal RLVR and use blind training as a diagnostic control, finding that RL with all training images masked can still improve performance on unmasked validation sets. To analyze this effect, text-deletion, image-mask-rate, and format-saturation controls suggest that such gains can arise from residual textual and distributional cues rather than valid visual evidence. Our results highlight the need to evaluate multimodal reasoning not only by final-answer accuracy, but also by robustness under modality transfer and by diagnostics that test whether improvements rely on task-critical visual evidence.
Continuous Expert Assembly: Instance-Conditioned Low-Rank Residuals for All-in-One Image Restoration
May 07, 2026Real-world image degradation is often unknown, spatially non-uniform, and compositional, requiring all-in-one restoration models to adapt a single set of weights to diverse local corruption patterns without test-time degradation labels. Existing methods typically modulate a shared backbone with global prompts or degradation descriptors, or route features through predefined expert pools. However, compact global conditioning can bottleneck localized degradation evidence, while static expert routing may produce homogeneous updates or rely on unstable sparse assignments. We propose \textbf{Continuous Expert Assembly} (CEA), a token-wise dynamic parameterization framework for all-in-one image restoration. CEA employs a lightweight \textbf{Cross-Attention Hyper-Adapter} to probe intermediate spatial features and synthesize instance-conditioned low-rank routing bases and residual directions. Each spatial token then assembles its own residual update via dense signed dot-product affinities over the generated rank-wise components, avoiding external prompts, static expert banks, and discrete Top- selection. The resulting assembly rule also admits a linear-attention perspective, making its dense token-wise routing behavior transparent. Experiments on AIO-3, AIO-5, and CDD-11 show that CEA improves average restoration quality over strong prompt-, descriptor-, and expert-based baselines, with the clearest gains on spatially varying and compositional degradations, while maintaining favorable parameter, FLOP, and runtime efficiency.
MotionHiFlow: Text-to-motion via hierarchical flow matching
Apr 25, 2026Text-to-motion generation aims to generate 3D human motions that are tightly aligned with the input text while remaining physically plausible and rich in fine-grained detail. Although recent approaches can produce complex and natural movements, they usually operate at only one temporal scale, which limits both semantic alignment and temporal coherence. Inspired by the fact that complex motions are conceptualized hierarchically rather than at a single temporal scale in the human cognitive system, we propose \textit{MotionHiFlow}, a hierarchical flow matching framework to generate motion progressively by constructing flow path from low to high temporal scales. The flows at lower scales capture high-level semantics and coarse motion structures, while flows at higher scales refine temporal details. To link the flows across scales, we introduce a novel cross-scale transition process, ensuring continuity and preserving noise consistency. Furthermore, by integrating a Text-Motion Diffusion Transformer and a topology-aware Motion VAE, MotionHiFlow explicitly models structural dependencies among joints via joint-aware positional encoding and skeletal topology, enabling precise semantic alignment alongside fine-grained motion details. Extensive experiments on HumanML3D and KIT-ML benchmarks demonstrate state-of-the-art performance, with ablation studies confirming the effectiveness of the hierarchical design and key components. Code is available at https://github.com/ai-lh/MotionHiFlow.
A multi-center analysis of deep learning methods for video polyp detection and segmentation
Mar 04, 2026Colonic polyps are well-recognized precursors to colorectal cancer (CRC), typically detected during colonoscopy. However, the variability in appearance, location, and size of these polyps complicates their detection and removal, leading to challenges in effective surveillance, intervention, and subsequently CRC prevention. The processes of colonoscopy surveillance and polyp removal are highly reliant on the expertise of gastroenterologists and occur within the complexities of the colonic structure. As a result, there is a high rate of missed detections and incomplete removal of colonic polyps, which can adversely impact patient outcomes. Recently, automated methods that use machine learning have been developed to enhance polyps detection and segmentation, thus helping clinical processes and reducing missed rates. These advancements highlight the potential for improving diagnostic accuracy in real-time applications, which ultimately facilitates more effective patient management. Furthermore, integrating sequence data and temporal information could significantly enhance the precision of these methods by capturing the dynamic nature of polyp growth and the changes that occur over time. To rigorously investigate these challenges, data scientists and experts gastroenterologists collaborated to compile a comprehensive dataset that spans multiple centers and diverse populations. This initiative aims to underscore the critical importance of incorporating sequence data and temporal information in the development of robust automated detection and segmentation methods. This study evaluates the applicability of deep learning techniques developed in real-time clinical colonoscopy tasks using sequence data, highlighting the critical role of temporal relationships between frames in improving diagnostic precision.
Early and Prediagnostic Detection of Pancreatic Cancer from Computed Tomography
Jan 29, 2026Pancreatic ductal adenocarcinoma (PDAC), one of the deadliest solid malignancies, is often detected at a late and inoperable stage. Retrospective reviews of prediagnostic CT scans, when conducted by expert radiologists aware that the patient later developed PDAC, frequently reveal lesions that were previously overlooked. To help detecting these lesions earlier, we developed an automated system named ePAI (early Pancreatic cancer detection with Artificial Intelligence). It was trained on data from 1,598 patients from a single medical center. In the internal test involving 1,009 patients, ePAI achieved an area under the receiver operating characteristic curve (AUC) of 0.939-0.999, a sensitivity of 95.3%, and a specificity of 98.7% for detecting small PDAC less than 2 cm in diameter, precisely localizing PDAC as small as 2 mm. In an external test involving 7,158 patients across 6 centers, ePAI achieved an AUC of 0.918-0.945, a sensitivity of 91.5%, and a specificity of 88.0%, precisely localizing PDAC as small as 5 mm. Importantly, ePAI detected PDACs on prediagnostic CT scans obtained 3 to 36 months before clinical diagnosis that had originally been overlooked by radiologists. It successfully detected and localized PDACs in 75 of 159 patients, with a median lead time of 347 days before clinical diagnosis. Our multi-reader study showed that ePAI significantly outperformed 30 board-certified radiologists by 50.3% (P < 0.05) in sensitivity while maintaining a comparable specificity of 95.4% in detecting PDACs early and prediagnostic. These findings suggest its potential of ePAI as an assistive tool to improve early detection of pancreatic cancer.
Automated Safety Benchmarking: A Multi-agent Pipeline for LVLMs
Jan 27, 2026Large vision-language models (LVLMs) exhibit remarkable capabilities in cross-modal tasks but face significant safety challenges, which undermine their reliability in real-world applications. Efforts have been made to build LVLM safety evaluation benchmarks to uncover their vulnerability. However, existing benchmarks are hindered by their labor-intensive construction process, static complexity, and limited discriminative power. Thus, they may fail to keep pace with rapidly evolving models and emerging risks. To address these limitations, we propose VLSafetyBencher, the first automated system for LVLM safety benchmarking. VLSafetyBencher introduces four collaborative agents: Data Preprocessing, Generation, Augmentation, and Selection agents to construct and select high-quality samples. Experiments validates that VLSafetyBencher can construct high-quality safety benchmarks within one week at a minimal cost. The generated benchmark effectively distinguish safety, with a safety rate disparity of 70% between the most and least safe models.
Geometry-Grounded Gaussian Splatting
Jan 25, 2026Gaussian Splatting (GS) has demonstrated impressive quality and efficiency in novel view synthesis. However, shape extraction from Gaussian primitives remains an open problem. Due to inadequate geometry parameterization and approximation, existing shape reconstruction methods suffer from poor multi-view consistency and are sensitive to floaters. In this paper, we present a rigorous theoretical derivation that establishes Gaussian primitives as a specific type of stochastic solids. This theoretical framework provides a principled foundation for Geometry-Grounded Gaussian Splatting by enabling the direct treatment of Gaussian primitives as explicit geometric representations. Using the volumetric nature of stochastic solids, our method efficiently renders high-quality depth maps for fine-grained geometry extraction. Experiments show that our method achieves the best shape reconstruction results among all Gaussian Splatting-based methods on public datasets.
Overcoming Joint Intractability with Lossless Hierarchical Speculative Decoding
Jan 09, 2026Verification is a key bottleneck in improving inference speed while maintaining distribution fidelity in Speculative Decoding. Recent work has shown that sequence-level verification leads to a higher number of accepted tokens compared to token-wise verification. However, existing solutions often rely on surrogate approximations or are constrained by partial information, struggling with joint intractability. In this work, we propose Hierarchical Speculative Decoding (HSD), a provably lossless verification method that significantly boosts the expected number of accepted tokens and overcomes joint intractability by balancing excess and deficient probability mass across accessible branches. Our extensive large-scale experiments demonstrate that HSD yields consistent improvements in acceptance rates across diverse model families and benchmarks. Moreover, its strong explainability and generality make it readily integrable into a wide range of speculative decoding frameworks. Notably, integrating HSD into EAGLE-3 yields over a 12% performance gain, establishing state-of-the-art decoding efficiency without compromising distribution fidelity. Code is available at https://github.com/ZhouYuxuanYX/Hierarchical-Speculative-Decoding.
SPATIALGEN: Layout-guided 3D Indoor Scene Generation
Sep 18, 2025
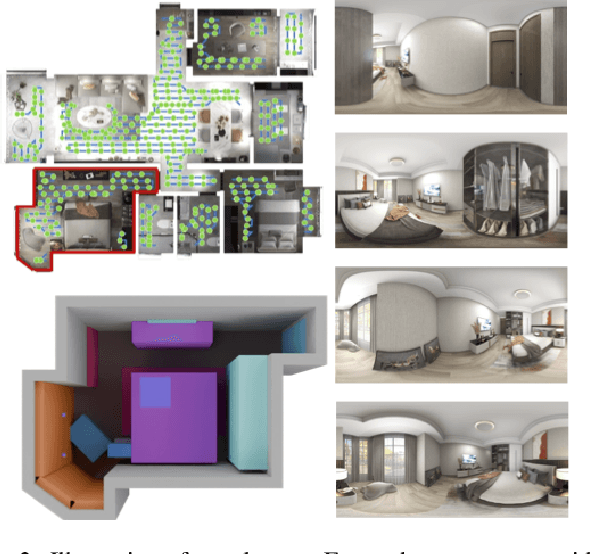
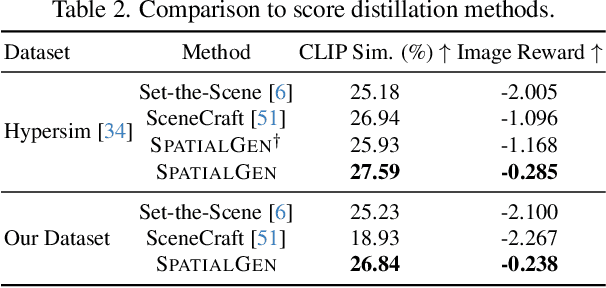
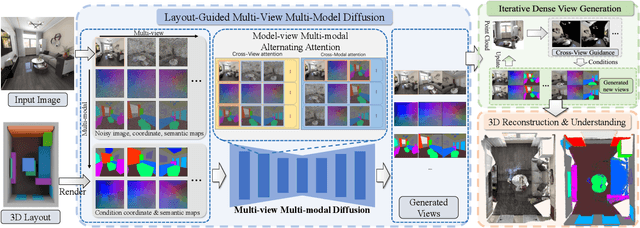
Creating high-fidelity 3D models of indoor environments is essential for applications in design, virtual reality, and robotics. However, manual 3D modeling remains time-consuming and labor-intensive. While recent advances in generative AI have enabled automated scene synthesis, existing methods often face challenges in balancing visual quality, diversity, semantic consistency, and user control. A major bottleneck is the lack of a large-scale, high-quality dataset tailored to this task. To address this gap, we introduce a comprehensive synthetic dataset, featuring 12,328 structured annotated scenes with 57,440 rooms, and 4.7M photorealistic 2D renderings. Leveraging this dataset, we present SpatialGen, a novel multi-view multi-modal diffusion model that generates realistic and semantically consistent 3D indoor scenes. Given a 3D layout and a reference image (derived from a text prompt), our model synthesizes appearance (color image), geometry (scene coordinate map), and semantic (semantic segmentation map) from arbitrary viewpoints, while preserving spatial consistency across modalities. SpatialGen consistently generates superior results to previous methods in our experiments. We are open-sourcing our data and models to empower the community and advance the field of indoor scene understanding and generation.