 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRS-HyRe-R1: A Hybrid Reward Mechanism to Overcome Perceptual Inertia for Remote Sensing Images Understanding
Apr 19, 2026Reinforcement learning (RL) post-training substantially improves remote sensing vision-language models (RS-VLMs). However, when handling complex remote sensing imagery (RSI) requiring exhaustive visual scanning, models tend to rely on localized salient cues for rapid inference. We term this RL-induced bias "perceptual inertia". Driven by reward maximization, models favor quick outcome fitting, leading to two limitations: cognitively, overreliance on specific features impedes complete evidence construction; operationally, models struggle to flexibly shift visual focus across tasks. To address this bias and encourage comprehensive visual evidence mining, we propose RS-HyRe-R1, a hybrid reward framework for RSI understanding. It introduces: (1) a spatial reasoning activation reward that enforces structured visual reasoning; (2) a perception correctness reward that provides adaptive quality anchors across RS tasks, ensuring accurate geometric and semantic alignment; and (3) a visual-semantic path evolution reward that penalizes repetitive reasoning and promotes exploration of complementary cues to build richer evidence chains. Experiments show RS-HyRe-R1 effectively mitigates "perceptual inertia", encouraging deeper, more diverse reasoning. With only 3B parameters, it achieves state-of-the-art performance on REC, OVD, and VQA tasks, outperforming models up to 7B parameters. It also demonstrates strong zero-shot generalization, surpassing the second-best model by 3.16%, 3.97%, and 2.72% on VQA, OVD, and REC, respectively. Code and datasets are available at https://github.com/geox-lab/RS-HyRe-R1.
FarmMind: Reasoning-Query-Driven Dynamic Segmentation for Farmland Remote Sensing Images
Jan 30, 2026Existing methods for farmland remote sensing image (FRSI) segmentation generally follow a static segmentation paradigm, where analysis relies solely on the limited information contained within a single input patch. Consequently, their reasoning capability is limited when dealing with complex scenes characterized by ambiguity and visual uncertainty. In contrast, human experts, when interpreting remote sensing images in such ambiguous cases, tend to actively query auxiliary images (such as higher-resolution, larger-scale, or temporally adjacent data) to conduct cross-verification and achieve more comprehensive reasoning. Inspired by this, we propose a reasoning-query-driven dynamic segmentation framework for FRSIs, named FarmMind. This framework breaks through the limitations of the static segmentation paradigm by introducing a reasoning-query mechanism, which dynamically and on-demand queries external auxiliary images to compensate for the insufficient information in a single input image. Unlike direct queries, this mechanism simulates the thinking process of human experts when faced with segmentation ambiguity: it first analyzes the root causes of segmentation ambiguities through reasoning, and then determines what type of auxiliary image needs to be queried based on this analysis. Extensive experiments demonstrate that FarmMind achieves superior segmentation performance and stronger generalization ability compared with existing methods. The source code and dataset used in this work are publicly available at: https://github.com/WithoutOcean/FarmMind.
MMedExpert-R1: Strengthening Multimodal Medical Reasoning via Domain-Specific Adaptation and Clinical Guideline Reinforcement
Jan 16, 2026Medical Vision-Language Models (MedVLMs) excel at perception tasks but struggle with complex clinical reasoning required in real-world scenarios. While reinforcement learning (RL) has been explored to enhance reasoning capabilities, existing approaches face critical mismatches: the scarcity of deep reasoning data, cold-start limits multi-specialty alignment, and standard RL algorithms fail to model clinical reasoning diversity. We propose MMedExpert-R1, a novel reasoning MedVLM that addresses these challenges through domain-specific adaptation and clinical guideline reinforcement. We construct MMedExpert, a high-quality dataset of 10K samples across four specialties with step-by-step reasoning traces. Our Domain-Specific Adaptation (DSA) creates specialty-specific LoRA modules to provide diverse initialization, while Guideline-Based Advantages (GBA) explicitly models different clinical reasoning perspectives to align with real-world diagnostic strategies. Conflict-Aware Capability Integration then merges these specialized experts into a unified agent, ensuring robust multi-specialty alignment. Comprehensive experiments demonstrate state-of-the-art performance, with our 7B model achieving 27.50 on MedXpert-MM and 83.03 on OmniMedVQA, establishing a robust foundation for reliable multimodal medical reasoning systems.
Layer-Order Inversion: Rethinking Latent Multi-Hop Reasoning in Large Language Models
Jan 07, 2026Large language models (LLMs) perform well on multi-hop reasoning, yet how they internally compose multiple facts remains unclear. Recent work proposes \emph{hop-aligned circuit hypothesis}, suggesting that bridge entities are computed sequentially across layers before later-hop answers. Through systematic analyses on real-world multi-hop queries, we show that this hop-aligned assumption does not generalize: later-hop answer entities can become decodable earlier than bridge entities, a phenomenon we call \emph{layer-order inversion}, which strengthens with total hops. To explain this behavior, we propose a \emph{probabilistic recall-and-extract} framework that models multi-hop reasoning as broad probabilistic recall in shallow MLP layers followed by selective extraction in deeper attention layers. This framework is empirically validated through systematic probing analyses, reinterpreting prior layer-wise decoding evidence, explaining chain-of-thought gains, and providing a mechanistic diagnosis of multi-hop failures despite correct single-hop knowledge. Code is available at https://github.com/laquabe/Layer-Order-Inversion.
MarineEval: Assessing the Marine Intelligence of Vision-Language Models
Dec 24, 2025We have witnessed promising progress led by large language models (LLMs) and further vision language models (VLMs) in handling various queries as a general-purpose assistant. VLMs, as a bridge to connect the visual world and language corpus, receive both visual content and various text-only user instructions to generate corresponding responses. Though great success has been achieved by VLMs in various fields, in this work, we ask whether the existing VLMs can act as domain experts, accurately answering marine questions, which require significant domain expertise and address special domain challenges/requirements. To comprehensively evaluate the effectiveness and explore the boundary of existing VLMs, we construct the first large-scale marine VLM dataset and benchmark called MarineEval, with 2,000 image-based question-answering pairs. During our dataset construction, we ensure the diversity and coverage of the constructed data: 7 task dimensions and 20 capacity dimensions. The domain requirements are specially integrated into the data construction and further verified by the corresponding marine domain experts. We comprehensively benchmark 17 existing VLMs on our MarineEval and also investigate the limitations of existing models in answering marine research questions. The experimental results reveal that existing VLMs cannot effectively answer the domain-specific questions, and there is still a large room for further performance improvements. We hope our new benchmark and observations will facilitate future research. Project Page: http://marineeval.hkustvgd.com/
LongVideoAgent: Multi-Agent Reasoning with Long Videos
Dec 23, 2025



Recent advances in multimodal LLMs and systems that use tools for long-video QA point to the promise of reasoning over hour-long episodes. However, many methods still compress content into lossy summaries or rely on limited toolsets, weakening temporal grounding and missing fine-grained cues. We propose a multi-agent framework in which a master LLM coordinates a grounding agent to localize question-relevant segments and a vision agent to extract targeted textual observations. The master agent plans with a step limit, and is trained with reinforcement learning to encourage concise, correct, and efficient multi-agent cooperation. This design helps the master agent focus on relevant clips via grounding, complements subtitles with visual detail, and yields interpretable trajectories. On our proposed LongTVQA and LongTVQA+ which are episode-level datasets aggregated from TVQA/TVQA+, our multi-agent system significantly outperforms strong non-agent baselines. Experiments also show reinforcement learning further strengthens reasoning and planning for the trained agent. Code and data will be shared at https://longvideoagent.github.io/.
Skin-R1: Toward Trustworthy Clinical Reasoning for Dermatological Diagnosis
Nov 18, 2025The emergence of vision-language models (VLMs) has opened new possibilities for clinical reasoning and has shown promising performance in dermatological diagnosis. However, their trustworthiness and clinical utility are often limited by three major factors: (1) Data heterogeneity, where diverse datasets lack consistent diagnostic labels and clinical concept annotations; (2) Absence of grounded diagnostic rationales, leading to a scarcity of reliable reasoning supervision; and (3) Limited scalability and generalization, as models trained on small, densely annotated datasets struggle to transfer nuanced reasoning to large, sparsely-annotated ones. To address these limitations, we propose SkinR1, a novel dermatological VLM that combines deep, textbook-based reasoning with the broad generalization capabilities of reinforcement learning (RL). SkinR1 systematically resolves the key challenges through a unified, end-to-end framework. First, we design a textbook-based reasoning generator that synthesizes high-fidelity, hierarchy-aware, and differential-diagnosis (DDx)-informed trajectories, providing reliable expert-level supervision. Second, we leverage the constructed trajectories for supervised fine-tuning (SFT) empowering the model with grounded reasoning ability. Third, we develop a novel RL paradigm that, by incorporating the hierarchical structure of diseases, effectively transfers these grounded reasoning patterns to large-scale, sparse data. Extensive experiments on multiple dermatology datasets demonstrate that SkinR1 achieves superior diagnostic accuracy. The ablation study demonstrates the importance of the reasoning foundation instilled by SFT.
RIDE: Difficulty Evolving Perturbation with Item Response Theory for Mathematical Reasoning
Nov 06, 2025Large language models (LLMs) achieve high performance on mathematical reasoning, but these results can be inflated by training data leakage or superficial pattern matching rather than genuine reasoning. To this end, an adversarial perturbation-based evaluation is needed to measure true mathematical reasoning ability. Current rule-based perturbation methods often generate ill-posed questions and impede the systematic evaluation of question difficulty and the evolution of benchmarks. To bridge this gap, we propose RIDE, a novel adversarial question-rewriting framework that leverages Item Response Theory (IRT) to rigorously measure question difficulty and to generate intrinsically more challenging, well-posed variations of mathematical problems. We employ 35 LLMs to simulate students and build a difficulty ranker from their responses. This ranker provides a reward signal during reinforcement learning and guides a question-rewriting model to reformulate existing questions across difficulty levels. Applying RIDE to competition-level mathematical benchmarks yields perturbed versions that degrade advanced LLM performance, with experiments showing an average 21.73% drop across 26 models, thereby exposing limited robustness in mathematical reasoning and confirming the validity of our evaluation approach.
Pointing to a Llama and Call it a Camel: On the Sycophancy of Multimodal Large Language Models
Sep 19, 2025



Multimodal large language models (MLLMs) have demonstrated extraordinary capabilities in conducting conversations based on image inputs. However, we observe that MLLMs exhibit a pronounced form of visual sycophantic behavior. While similar behavior has also been noted in text-based large language models (LLMs), it becomes significantly more prominent when MLLMs process image inputs. We refer to this phenomenon as the "sycophantic modality gap." To better understand this issue, we further analyze the factors that contribute to the exacerbation of this gap. To mitigate the visual sycophantic behavior, we first experiment with naive supervised fine-tuning to help the MLLM resist misleading instructions from the user. However, we find that this approach also makes the MLLM overly resistant to corrective instructions (i.e., stubborn even if it is wrong). To alleviate this trade-off, we propose Sycophantic Reflective Tuning (SRT), which enables the MLLM to engage in reflective reasoning, allowing it to determine whether a user's instruction is misleading or corrective before drawing a conclusion. After applying SRT, we observe a significant reduction in sycophantic behavior toward misleading instructions, without resulting in excessive stubbornness when receiving corrective instructions.
Remote Sensing Image Intelligent Interpretation with the Language-Centered Perspective: Principles, Methods and Challenges
Aug 09, 2025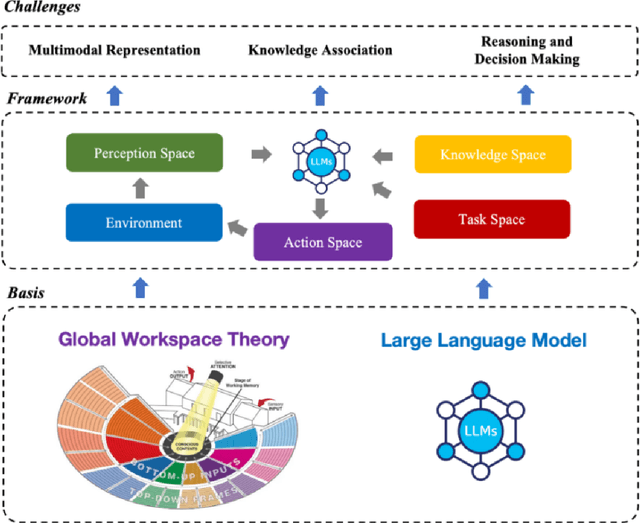
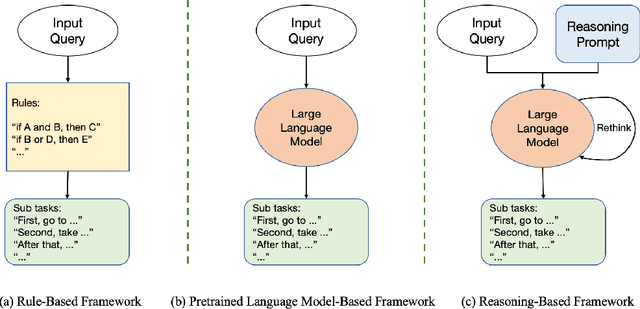
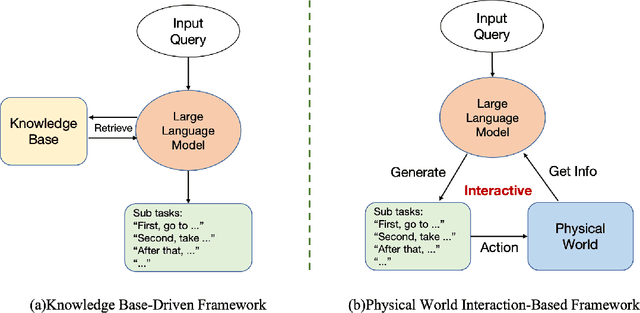
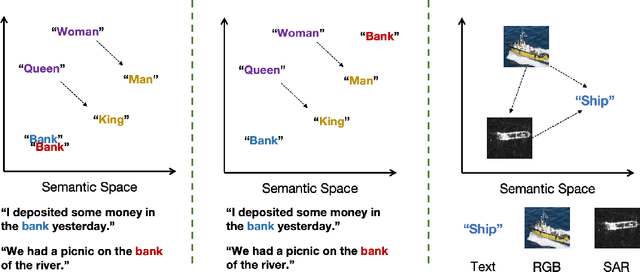
The mainstream paradigm of remote sensing image interpretation has long been dominated by vision-centered models, which rely on visual features for semantic understanding. However, these models face inherent limitations in handling multi-modal reasoning, semantic abstraction, and interactive decision-making. While recent advances have introduced Large Language Models (LLMs) into remote sensing workflows, existing studies primarily focus on downstream applications, lacking a unified theoretical framework that explains the cognitive role of language. This review advocates a paradigm shift from vision-centered to language-centered remote sensing interpretation. Drawing inspiration from the Global Workspace Theory (GWT) of human cognition, We propose a language-centered framework for remote sensing interpretation that treats LLMs as the cognitive central hub integrating perceptual, task, knowledge and action spaces to enable unified understanding, reasoning, and decision-making. We first explore the potential of LLMs as the central cognitive component in remote sensing interpretation, and then summarize core technical challenges, including unified multimodal representation, knowledge association, and reasoning and decision-making. Furthermore, we construct a global workspace-driven interpretation mechanism and review how language-centered solutions address each challenge. Finally, we outline future research directions from four perspectives: adaptive alignment of multimodal data, task understanding under dynamic knowledge constraints, trustworthy reasoning, and autonomous interaction. This work aims to provide a conceptual foundation for the next generation of remote sensing interpretation systems and establish a roadmap toward cognition-driven intelligent geospatial analysis.