 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLUE: Non-parametric Verification from Experience via Hidden-State Clustering
Oct 02, 2025



Assessing the quality of Large Language Model (LLM) outputs presents a critical challenge. Previous methods either rely on text-level information (e.g., reward models, majority voting), which can overfit to superficial cues, or on calibrated confidence from token probabilities, which would fail on less-calibrated models. Yet both of these signals are, in fact, partial projections of a richer source of information: the model's internal hidden states. Early layers, closer to token embeddings, preserve semantic and lexical features that underpin text-based judgments, while later layers increasingly align with output logits, embedding confidence-related information. This paper explores hidden states directly as a unified foundation for verification. We show that the correctness of a solution is encoded as a geometrically separable signature within the trajectory of hidden activations. To validate this, we present Clue (Clustering and Experience-based Verification), a deliberately minimalist, non-parametric verifier. With no trainable parameters, CLUE only summarizes each reasoning trace by an hidden state delta and classifies correctness via nearest-centroid distance to ``success'' and ``failure'' clusters formed from past experience. The simplicity of this method highlights the strength of the underlying signal. Empirically, CLUE consistently outperforms LLM-as-a-judge baselines and matches or exceeds modern confidence-based methods in reranking candidates, improving both top-1 and majority-vote accuracy across AIME 24/25 and GPQA. As a highlight, on AIME 24 with a 1.5B model, CLUE boosts accuracy from 56.7% (majority@64) to 70.0% (top-maj@16).
R-Zero: Self-Evolving Reasoning LLM from Zero Data
Aug 07, 2025
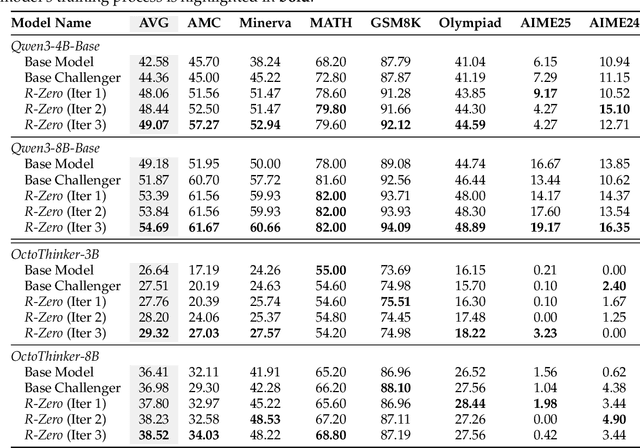

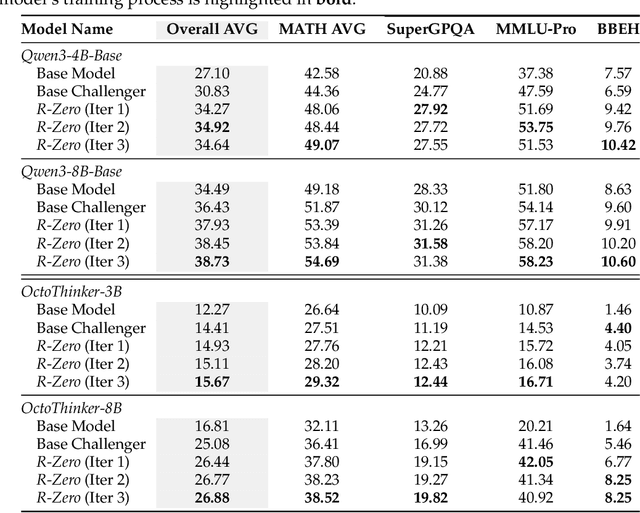
Self-evolving Large Language Models (LLMs) offer a scalable path toward super-intelligence by autonomously generating, refining, and learning from their own experiences. However, existing methods for training such models still rely heavily on vast human-curated tasks and labels, typically via fine-tuning or reinforcement learning, which poses a fundamental bottleneck to advancing AI systems toward capabilities beyond human intelligence. To overcome this limitation, we introduce R-Zero, a fully autonomous framework that generates its own training data from scratch. Starting from a single base LLM, R-Zero initializes two independent models with distinct roles, a Challenger and a Solver. These models are optimized separately and co-evolve through interaction: the Challenger is rewarded for proposing tasks near the edge of the Solver capability, and the Solver is rewarded for solving increasingly challenging tasks posed by the Challenger. This process yields a targeted, self-improving curriculum without any pre-existing tasks and labels. Empirically, R-Zero substantially improves reasoning capability across different backbone LLMs, e.g., boosting the Qwen3-4B-Base by +6.49 on math-reasoning benchmarks and +7.54 on general-domain reasoning benchmarks.
IQA-EVAL: Automatic Evaluation of Human-Model Interactive Question Answering
Aug 24, 2024



To evaluate Large Language Models (LLMs) for question answering (QA), traditional methods typically focus on directly assessing the immediate responses generated by the models based on the given question and context. In the common use case of humans seeking AI assistant's help in finding information, these non-interactive evaluations do not account for the dynamic nature of human-model conversations, and interaction-aware evaluations have shown that accurate QA models are preferred by humans (Lee et al., 2023). Recent works in human-computer interaction (HCI) have employed human evaluators to conduct interactions and evaluations, but they are often prohibitively expensive and time-consuming to scale. In this work, we introduce an automatic evaluation framework IQA-EVAL to Interactive Question Answering Evaluation. More specifically, we introduce LLM-based Evaluation Agent (LEA) that can: (1) simulate human behaviors to generate interactions with IQA models; (2) automatically evaluate the generated interactions. Moreover, we propose assigning personas to LEAs to better simulate groups of real human evaluators. We show that: (1) our evaluation framework with GPT-4 (or Claude) as the backbone model achieves a high correlation with human evaluations on the IQA task; (2) assigning personas to LEA to better represent the crowd further significantly improves correlations. Finally, we use our automatic metric to evaluate five recent representative LLMs with over 1000 questions from complex and ambiguous question answering tasks, which comes with a substantial cost of $5k if evaluated by humans.
Leveraging Structured Information for Explainable Multi-hop Question Answering and Reasoning
Nov 07, 2023Neural models, including large language models (LLMs), achieve superior performance on multi-hop question-answering. To elicit reasoning capabilities from LLMs, recent works propose using the chain-of-thought (CoT) mechanism to generate both the reasoning chain and the answer, which enhances the model's capabilities in conducting multi-hop reasoning. However, several challenges still remain: such as struggling with inaccurate reasoning, hallucinations, and lack of interpretability. On the other hand, information extraction (IE) identifies entities, relations, and events grounded to the text. The extracted structured information can be easily interpreted by humans and machines (Grishman, 2019). In this work, we investigate constructing and leveraging extracted semantic structures (graphs) for multi-hop question answering, especially the reasoning process. Empirical results and human evaluations show that our framework: generates more faithful reasoning chains and substantially improves the QA performance on two benchmark datasets. Moreover, the extracted structures themselves naturally provide grounded explanations that are preferred by humans, as compared to the generated reasoning chains and saliency-based explanations.
FAITHSCORE: Evaluating Hallucinations in Large Vision-Language Models
Nov 02, 2023We introduce FAITHSCORE (Faithfulness to Atomic Image Facts Score), a reference-free and fine-grained evaluation metric that measures the faithfulness of the generated free-form answers from large vision-language models (LVLMs). The FAITHSCORE evaluation first identifies sub-sentences containing descriptive statements that need to be verified, then extracts a comprehensive list of atomic facts from these sub-sentences, and finally conducts consistency verification between fine-grained atomic facts and the input image. Meta-evaluation demonstrates that our metric highly correlates with human judgments of faithfulness. We collect two benchmark datasets (i.e. LLaVA-1k and MSCOCO-Cap) for evaluating LVLMs instruction-following hallucinations. We measure hallucinations in state-of-the-art LVLMs with FAITHSCORE on the datasets. Results reveal that current systems are prone to generate hallucinated content unfaithful to the image, which leaves room for future improvements. Further, we find that current LVLMs despite doing well on color and counting, still struggle with long answers, relations, and multiple objects.
PRD: Peer Rank and Discussion Improve Large Language Model based Evaluations
Jul 06, 2023Nowadays, the quality of responses generated by different modern large language models (LLMs) are hard to evaluate and compare automatically. Recent studies suggest and predominantly use LLMs as a reference-free metric for open-ended question answering. More specifically, they use the recognized "strongest" LLM as the evaluator, which conducts pairwise comparisons of candidate models' answers and provides a ranking score. However, this intuitive method has multiple problems, such as bringing in self-enhancement (favoring its own answers) and positional bias. We draw insights and lessons from the educational domain (Cho and MacArthur, 2011; Walsh, 2014) to improve LLM-based evaluations. Specifically, we propose the (1) peer rank (PR) algorithm that takes into account each peer LLM's pairwise preferences of all answer pairs, and outputs a final ranking of models; and (2) peer discussion (PD), where we prompt two LLMs to discuss and try to reach a mutual agreement on preferences of two answers. We conduct experiments on two benchmark datasets. We find that our approaches achieve higher accuracy and align better with human judgments, respectively. Interestingly, PR can induce a relatively accurate self-ranking of models under the anonymous setting, where each model's name is unrevealed. Our work provides space to explore evaluating models that are hard to compare for humans.