 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA1: Asynchronous Test-Time Scaling via Conformal Prediction
Sep 18, 2025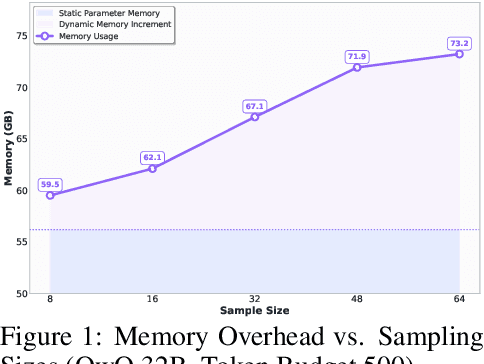
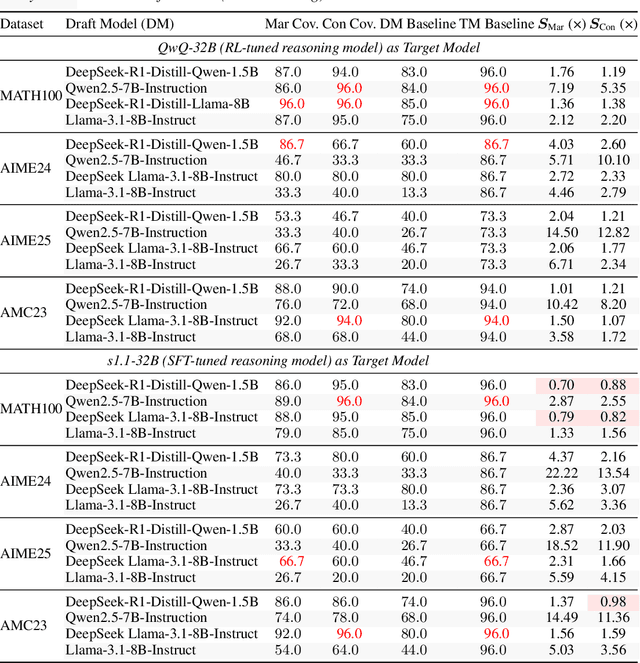
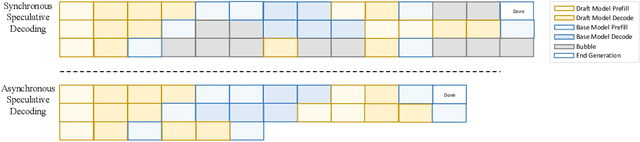
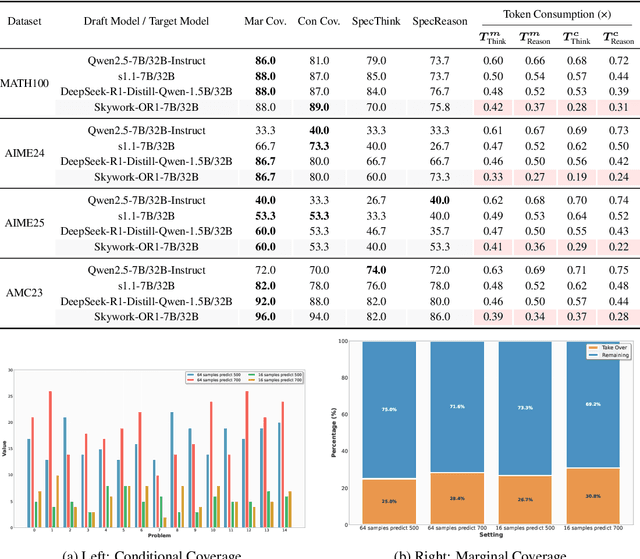
Large language models (LLMs) benefit from test-time scaling, but existing methods face significant challenges, including severe synchronization overhead, memory bottlenecks, and latency, especially during speculative decoding with long reasoning chains. We introduce A1 (Asynchronous Test-Time Scaling), a statistically guaranteed adaptive inference framework that addresses these challenges. A1 refines arithmetic intensity to identify synchronization as the dominant bottleneck, proposes an online calibration strategy to enable asynchronous inference, and designs a three-stage rejection sampling pipeline that supports both sequential and parallel scaling. Through experiments on the MATH, AMC23, AIME24, and AIME25 datasets, across various draft-target model families, we demonstrate that A1 achieves a remarkable 56.7x speedup in test-time scaling and a 4.14x improvement in throughput, all while maintaining accurate rejection-rate control, reducing latency and memory overhead, and no accuracy loss compared to using target model scaling alone. These results position A1 as an efficient and principled solution for scalable LLM inference. We have released the code at https://github.com/menik1126/asynchronous-test-time-scaling.
The Synergy Dilemma of Long-CoT SFT and RL: Investigating Post-Training Techniques for Reasoning VLMs
Jul 10, 2025



Large vision-language models (VLMs) increasingly adopt post-training techniques such as long chain-of-thought (CoT) supervised fine-tuning (SFT) and reinforcement learning (RL) to elicit sophisticated reasoning. While these methods exhibit synergy in language-only models, their joint effectiveness in VLMs remains uncertain. We present a systematic investigation into the distinct roles and interplay of long-CoT SFT and RL across multiple multimodal reasoning benchmarks. We find that SFT improves performance on difficult questions by in-depth, structured reasoning, but introduces verbosity and degrades performance on simpler ones. In contrast, RL promotes generalization and brevity, yielding consistent improvements across all difficulty levels, though the improvements on the hardest questions are less prominent compared to SFT. Surprisingly, combining them through two-staged, interleaved, or progressive training strategies, as well as data mixing and model merging, all fails to produce additive benefits, instead leading to trade-offs in accuracy, reasoning style, and response length. This ``synergy dilemma'' highlights the need for more seamless and adaptive approaches to unlock the full potential of combined post-training techniques for reasoning VLMs.
QFFT, Question-Free Fine-Tuning for Adaptive Reasoning
Jun 15, 2025



Recent advancements in Long Chain-of-Thought (CoT) reasoning models have improved performance on complex tasks, but they suffer from overthinking, which generates redundant reasoning steps, especially for simple questions. This paper revisits the reasoning patterns of Long and Short CoT models, observing that the Short CoT patterns offer concise reasoning efficiently, while the Long CoT patterns excel in challenging scenarios where the Short CoT patterns struggle. To enable models to leverage both patterns, we propose Question-Free Fine-Tuning (QFFT), a fine-tuning approach that removes the input question during training and learns exclusively from Long CoT responses. This approach enables the model to adaptively employ both reasoning patterns: it prioritizes the Short CoT patterns and activates the Long CoT patterns only when necessary. Experiments on various mathematical datasets demonstrate that QFFT reduces average response length by more than 50\%, while achieving performance comparable to Supervised Fine-Tuning (SFT). Additionally, QFFT exhibits superior performance compared to SFT in noisy, out-of-domain, and low-resource scenarios.
Safe: Enhancing Mathematical Reasoning in Large Language Models via Retrospective Step-aware Formal Verification
Jun 05, 2025



Chain-of-Thought (CoT) prompting has become the de facto method to elicit reasoning capabilities from large language models (LLMs). However, to mitigate hallucinations in CoT that are notoriously difficult to detect, current methods such as process reward models (PRMs) or self-consistency operate as opaque boxes and do not provide checkable evidence for their judgments, possibly limiting their effectiveness. To address this issue, we draw inspiration from the idea that "the gold standard for supporting a mathematical claim is to provide a proof". We propose a retrospective, step-aware formal verification framework $Safe$. Rather than assigning arbitrary scores, we strive to articulate mathematical claims in formal mathematical language Lean 4 at each reasoning step and provide formal proofs to identify hallucinations. We evaluate our framework $Safe$ across multiple language models and various mathematical datasets, demonstrating a significant performance improvement while offering interpretable and verifiable evidence. We also propose $FormalStep$ as a benchmark for step correctness theorem proving with $30,809$ formal statements. To the best of our knowledge, our work represents the first endeavor to utilize formal mathematical language Lean 4 for verifying natural language content generated by LLMs, aligning with the reason why formal mathematical languages were created in the first place: to provide a robust foundation for hallucination-prone human-written proofs.
Pangu DeepDiver: Adaptive Search Intensity Scaling via Open-Web Reinforcement Learning
May 30, 2025Information seeking demands iterative evidence gathering and reflective reasoning, yet large language models (LLMs) still struggle with it in open-web question answering. Existing methods rely on static prompting rules or training with Wikipedia-based corpora and retrieval environments, limiting adaptability to the real-world web environment where ambiguity, conflicting evidence, and noise are prevalent. These constrained training settings hinder LLMs from learning to dynamically decide when and where to search, and how to adjust search depth and frequency based on informational demands. We define this missing capacity as Search Intensity Scaling (SIS)--the emergent skill to intensify search efforts under ambiguous or conflicting conditions, rather than settling on overconfident, under-verification answers. To study SIS, we introduce WebPuzzle, the first dataset designed to foster information-seeking behavior in open-world internet environments. WebPuzzle consists of 24K training instances and 275 test questions spanning both wiki-based and open-web queries. Building on this dataset, we propose DeepDiver, a Reinforcement Learning (RL) framework that promotes SIS by encouraging adaptive search policies through exploration under a real-world open-web environment. Experimental results show that Pangu-7B-Reasoner empowered by DeepDiver achieve performance on real-web tasks comparable to the 671B-parameter DeepSeek-R1. We detail DeepDiver's training curriculum from cold-start supervised fine-tuning to a carefully designed RL phase, and present that its capability of SIS generalizes from closed-form QA to open-ended tasks such as long-form writing. Our contributions advance adaptive information seeking in LLMs and provide a valuable benchmark and dataset for future research.
Self-Error-Instruct: Generalizing from Errors for LLMs Mathematical Reasoning
May 28, 2025



Although large language models demonstrate strong performance across various domains, they still struggle with numerous bad cases in mathematical reasoning. Previous approaches to learning from errors synthesize training data by solely extrapolating from isolated bad cases, thereby failing to generalize the extensive patterns inherent within these cases. This paper presents Self-Error-Instruct (SEI), a framework that addresses these model weaknesses and synthesizes more generalized targeted training data. Specifically, we explore a target model on two mathematical datasets, GSM8K and MATH, to pinpoint bad cases. Then, we generate error keyphrases for these cases based on the instructor model's (GPT-4o) analysis and identify error types by clustering these keyphrases. Next, we sample a few bad cases during each generation for each identified error type and input them into the instructor model, which synthesizes additional training data using a self-instruct approach. This new data is refined through a one-shot learning process to ensure that only the most effective examples are kept. Finally, we use these curated data to fine-tune the target model, iteratively repeating the process to enhance performance. We apply our framework to various models and observe improvements in their reasoning abilities across both in-domain and out-of-domain mathematics datasets. These results demonstrate the effectiveness of self-error instruction in improving LLMs' mathematical reasoning through error generalization.
The Real Barrier to LLM Agent Usability is Agentic ROI
May 23, 2025Large Language Model (LLM) agents represent a promising shift in human-AI interaction, moving beyond passive prompt-response systems to autonomous agents capable of reasoning, planning, and goal-directed action. Despite the widespread application in specialized, high-effort tasks like coding and scientific research, we highlight a critical usability gap in high-demand, mass-market applications. This position paper argues that the limited real-world adoption of LLM agents stems not only from gaps in model capabilities, but also from a fundamental tradeoff between the value an agent can provide and the costs incurred during real-world use. Hence, we call for a shift from solely optimizing model performance to a broader, utility-driven perspective: evaluating agents through the lens of the overall agentic return on investment (Agent ROI). By identifying key factors that determine Agentic ROI--information quality, agent time, and cost--we posit a zigzag development trajectory in optimizing agentic ROI: first scaling up to improve the information quality, then scaling down to minimize the time and cost. We outline the roadmap across different development stages to bridge the current usability gaps, aiming to make LLM agents truly scalable, accessible, and effective in real-world contexts.
Stepwise Reasoning Checkpoint Analysis: A Test Time Scaling Method to Enhance LLMs' Reasoning
May 23, 2025Mathematical reasoning through Chain-of-Thought (CoT) has emerged as a powerful capability of Large Language Models (LLMs), which can be further enhanced through Test-Time Scaling (TTS) methods like Beam Search and DVTS. However, these methods, despite improving accuracy by allocating more computational resources during inference, often suffer from path homogenization and inefficient use of intermediate results. To address these limitations, we propose Stepwise Reasoning Checkpoint Analysis (SRCA), a framework that introduces checkpoints between reasoning steps. It incorporates two key strategies: (1) Answer-Clustered Search, which groups reasoning paths by their intermediate checkpoint answers to maintain diversity while ensuring quality, and (2) Checkpoint Candidate Augmentation, which leverages all intermediate answers for final decision-making. Our approach effectively reduces path homogenization and creates a fault-tolerant mechanism by utilizing high-quality intermediate results. Experimental results show that SRCA improves reasoning accuracy compared to existing TTS methods across various mathematical datasets.
How Should We Enhance the Safety of Large Reasoning Models: An Empirical Study
May 21, 2025Large Reasoning Models (LRMs) have achieved remarkable success on reasoning-intensive tasks such as mathematics and programming. However, their enhanced reasoning capabilities do not necessarily translate to improved safety performance-and in some cases, may even degrade it. This raises an important research question: how can we enhance the safety of LRMs? In this paper, we present a comprehensive empirical study on how to enhance the safety of LRMs through Supervised Fine-Tuning (SFT). Our investigation begins with an unexpected observation: directly distilling safe responses from DeepSeek-R1 fails to significantly enhance safety. We analyze this phenomenon and identify three key failure patterns that contribute to it. We then demonstrate that explicitly addressing these issues during the data distillation process can lead to substantial safety improvements. Next, we explore whether a long and complex reasoning process is necessary for achieving safety. Interestingly, we find that simply using short or template-based reasoning process can attain comparable safety performance-and are significantly easier for models to learn than more intricate reasoning chains. These findings prompt a deeper reflection on the role of reasoning in ensuring safety. Finally, we find that mixing math reasoning data during safety fine-tuning is helpful to balance safety and over-refusal. Overall, we hope our empirical study could provide a more holistic picture on enhancing the safety of LRMs. The code and data used in our experiments are released in https://github.com/thu-coai/LRM-Safety-Study.
Instruction-Tuning Data Synthesis from Scratch via Web Reconstruction
Apr 22, 2025The improvement of LLMs' instruction-following capabilities depends critically on the availability of high-quality instruction-response pairs. While existing automatic data synthetic methods alleviate the burden of manual curation, they often rely heavily on either the quality of seed data or strong assumptions about the structure and content of web documents. To tackle these challenges, we propose Web Reconstruction (WebR), a fully automated framework for synthesizing high-quality instruction-tuning (IT) data directly from raw web documents with minimal assumptions. Leveraging the inherent diversity of raw web content, we conceptualize web reconstruction as an instruction-tuning data synthesis task via a novel dual-perspective paradigm--Web as Instruction and Web as Response--where each web document is designated as either an instruction or a response to trigger the reconstruction process. Comprehensive experiments show that datasets generated by WebR outperform state-of-the-art baselines by up to 16.65% across four instruction-following benchmarks. Notably, WebR demonstrates superior compatibility, data efficiency, and scalability, enabling enhanced domain adaptation with minimal effort. The data and code are publicly available at https://github.com/YJiangcm/WebR.