 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodeComp: Structural KV Cache Compression for Agentic Coding
Apr 11, 2026Agentic code tasks such as fault localization and patch generation require processing long codebases under tight memory constraints, where the Key-Value (KV) cache becomes the primary inference bottleneck. Existing compression methods rely exclusively on attention signals to estimate token importance, systematically discarding structurally critical tokens such as call sites, branch conditions, and assignments that are essential for code understanding. We present CodeComp, a training-free KV cache compression framework that incorporates static program analysis into LLM inference via Code Property Graph priors extracted by Joern. Across bug localization and code generation benchmarks, CodeComp consistently outperforms attention-only compression baselines under equal memory budgets, recovering the majority of full-context accuracy under aggressive KV cache compression, while matching the patch generation quality of uncompressed full-context inference and integrating seamlessly into SGLang-based agentic coding pipelines without model modification.
A1: Asynchronous Test-Time Scaling via Conformal Prediction
Sep 18, 2025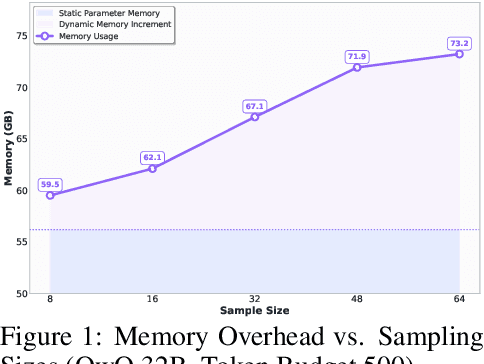
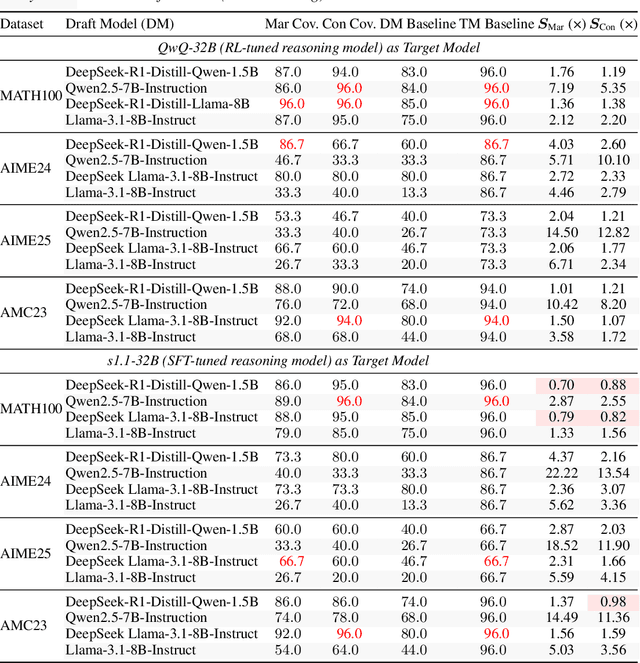
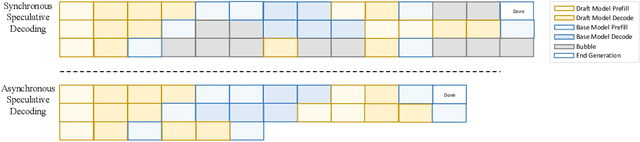
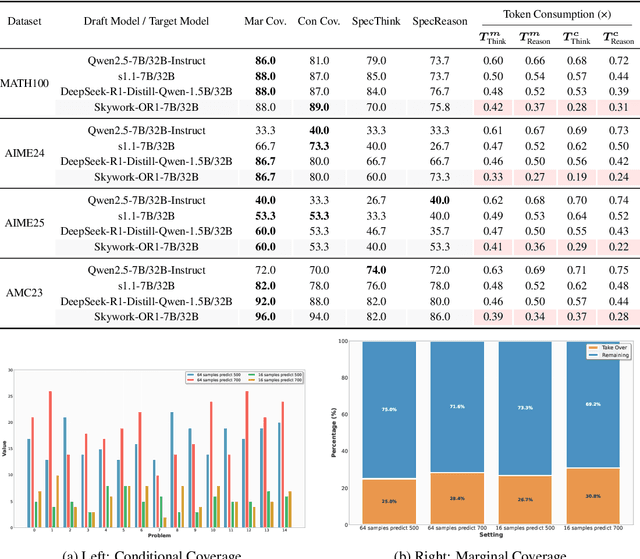
Large language models (LLMs) benefit from test-time scaling, but existing methods face significant challenges, including severe synchronization overhead, memory bottlenecks, and latency, especially during speculative decoding with long reasoning chains. We introduce A1 (Asynchronous Test-Time Scaling), a statistically guaranteed adaptive inference framework that addresses these challenges. A1 refines arithmetic intensity to identify synchronization as the dominant bottleneck, proposes an online calibration strategy to enable asynchronous inference, and designs a three-stage rejection sampling pipeline that supports both sequential and parallel scaling. Through experiments on the MATH, AMC23, AIME24, and AIME25 datasets, across various draft-target model families, we demonstrate that A1 achieves a remarkable 56.7x speedup in test-time scaling and a 4.14x improvement in throughput, all while maintaining accurate rejection-rate control, reducing latency and memory overhead, and no accuracy loss compared to using target model scaling alone. These results position A1 as an efficient and principled solution for scalable LLM inference. We have released the code at https://github.com/menik1126/asynchronous-test-time-scaling.
SwingArena: Competitive Programming Arena for Long-context GitHub Issue Solving
May 29, 2025



We present SwingArena, a competitive evaluation framework for Large Language Models (LLMs) that closely mirrors real-world software development workflows. Unlike traditional static benchmarks, SwingArena models the collaborative process of software iteration by pairing LLMs as submitters, who generate patches, and reviewers, who create test cases and verify the patches through continuous integration (CI) pipelines. To support these interactive evaluations, we introduce a retrieval-augmented code generation (RACG) module that efficiently handles long-context challenges by providing syntactically and semantically relevant code snippets from large codebases, supporting multiple programming languages (C++, Python, Rust, and Go). This enables the framework to scale across diverse tasks and contexts while respecting token limitations. Our experiments, using over 400 high-quality real-world GitHub issues selected from a pool of 2,300 issues, show that models like GPT-4o excel at aggressive patch generation, whereas DeepSeek and Gemini prioritize correctness in CI validation. SwingArena presents a scalable and extensible methodology for evaluating LLMs in realistic, CI-driven software development settings. More details are available on our project page: swing-bench.github.io