 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAffectVerse: Emotional World Models for Multimodal Affective Computing
May 19, 2026Humans infer emotions by integrating observed multimodal cues with expectations about how affective states may unfold. Existing multimodal large language models (MLLMs), however, often treat emotion recognition as static fusion over complete audiovisual-text inputs, leaving affective dynamics implicit. We propose AffectVerse, a Qwen2.5-Omni-based model equipped with an Emotion World Module (EWM), an action-free representation-level module for short-horizon latent affective prediction. \rev{EWM contains three modules: 1) Cross-Modal Temporal Imagination predicts future video/audio representations from past tokens with multi-step rollout. 2) MAMA(Modality-Aware Multi-step Attention) Belief Aggregation compresses imagined tokens into modality-aware belief tokens. 3) Belief Injection inserts these belief tokens into the LLM for affective reasoning.} AffectVerse uses future prediction as a past-conditioned self-supervised signal: it does not replace modeling observed history or require unseen signals at inference, but forces the current belief state to encode transition cues that are predictive of subsequent affective change. Across nine benchmarks, AffectVerse improves at least 2.57\% over other models, while controlled ablations show additive gains from temporal imagination, cross-modal rollout, and belief aggregation. These results suggest predictive belief-state modeling is a practical alternative for affective computing.
Context-Fidelity Boosting: Enhancing Faithful Generation through Watermark-Inspired Decoding
Apr 24, 2026Large language models (LLMs) often produce content that contradicts or overlooks information provided in the input context, a phenomenon known as faithfulness hallucination. In this paper, we propose Context-Fidelity Boosting (CFB), a lightweight and general decoding-time framework that reduces such hallucinations by increasing the generation probability of source-supported tokens. Motivated by logit-shaping principles from watermarking techniques, CFB applies additive token-level logit adjustments based on a token's degree of support from the input context. Specifically, we develop three boosting strategies: static boosting, which applies a fixed bias to source-supported tokens; context-aware boosting, which scales this bias using the divergence between next-token distributions with and without context; and token-aware boosting, which further redistributes the adaptive bias according to local relevance estimated from source-position attention and source-scoped semantic similarity. CFB requires no retraining or architectural changes, making it compatible with a wide range of LLMs. Experiments on summarization and question answering tasks across multiple open-source LLMs show that CFB consistently improves faithfulness metrics with minimal generation overhead. Our implementation is fully open-sourced.
Think Fast and Slow: Step-Level Cognitive Depth Adaptation for LLM Agents
Feb 13, 2026Large language models (LLMs) are increasingly deployed as autonomous agents for multi-turn decision-making tasks. However, current agents typically rely on fixed cognitive patterns: non-thinking models generate immediate responses, while thinking models engage in deep reasoning uniformly. This rigidity is inefficient for long-horizon tasks, where cognitive demands vary significantly from step to step, with some requiring strategic planning and others only routine execution. In this paper, we introduce CogRouter, a framework that trains agents to dynamically adapt cognitive depth at each step. Grounded in ACT-R theory, we design four hierarchical cognitive levels ranging from instinctive responses to strategic planning. Our two-stage training approach includes Cognition-aware Supervised Fine-tuning (CoSFT) to instill stable level-specific patterns, and Cognition-aware Policy Optimization (CoPO) for step-level credit assignment via confidence-aware advantage reweighting. The key insight is that appropriate cognitive depth should maximize the confidence of the resulting action. Experiments on ALFWorld and ScienceWorld demonstrate that CogRouter achieves state-of-the-art performance with superior efficiency. With Qwen2.5-7B, it reaches an 82.3% success rate, outperforming GPT-4o (+40.3%), OpenAI-o3 (+18.3%), and GRPO (+14.0%), while using 62% fewer tokens.
On-Policy Supervised Fine-Tuning for Efficient Reasoning
Feb 13, 2026Large reasoning models (LRMs) are commonly trained with reinforcement learning (RL) to explore long chain-of-thought reasoning, achieving strong performance at high computational cost. Recent methods add multi-reward objectives to jointly optimize correctness and brevity, but these complex extensions often destabilize training and yield suboptimal trade-offs. We revisit this objective and challenge the necessity of such complexity. Through principled analysis, we identify fundamental misalignments in this paradigm: KL regularization loses its intended role when correctness and length are directly verifiable, and group-wise normalization becomes ambiguous under multiple reward signals. By removing these two items and simplifying the reward to a truncation-based length penalty, we show that the optimization problem reduces to supervised fine-tuning on self-generated data filtered for both correctness and conciseness. We term this simplified training strategy on-policy SFT. Despite its simplicity, on-policy SFT consistently defines the accuracy-efficiency Pareto frontier. It reduces CoT length by up to 80 while maintaining original accuracy, surpassing more complex RL-based methods across five benchmarks. Furthermore, it significantly enhances training efficiency, reducing GPU memory usage by 50% and accelerating convergence by 70%. Our code is available at https://github.com/EIT-NLP/On-Policy-SFT.
The Script is All You Need: An Agentic Framework for Long-Horizon Dialogue-to-Cinematic Video Generation
Jan 27, 2026Recent advances in video generation have produced models capable of synthesizing stunning visual content from simple text prompts. However, these models struggle to generate long-form, coherent narratives from high-level concepts like dialogue, revealing a ``semantic gap'' between a creative idea and its cinematic execution. To bridge this gap, we introduce a novel, end-to-end agentic framework for dialogue-to-cinematic-video generation. Central to our framework is ScripterAgent, a model trained to translate coarse dialogue into a fine-grained, executable cinematic script. To enable this, we construct ScriptBench, a new large-scale benchmark with rich multimodal context, annotated via an expert-guided pipeline. The generated script then guides DirectorAgent, which orchestrates state-of-the-art video models using a cross-scene continuous generation strategy to ensure long-horizon coherence. Our comprehensive evaluation, featuring an AI-powered CriticAgent and a new Visual-Script Alignment (VSA) metric, shows our framework significantly improves script faithfulness and temporal fidelity across all tested video models. Furthermore, our analysis uncovers a crucial trade-off in current SOTA models between visual spectacle and strict script adherence, providing valuable insights for the future of automated filmmaking.
From LLMs to LRMs: Rethinking Pruning for Reasoning-Centric Models
Jan 26, 2026Large language models (LLMs) are increasingly costly to deploy, motivating extensive research on model pruning. However, most existing studies focus on instruction-following LLMs, leaving it unclear whether established pruning strategies transfer to reasoning-augmented models that explicitly generate long intermediate reasoning traces. In this work, we conduct a controlled study of pruning for both instruction-following ($\textbf{LLM-instruct}$) and reasoning-augmented ($\textbf{LLM-think}$) models. To isolate the effects of pruning, we align pruning calibration and post-pruning recovery data with each model's original training distribution, which we show yields more stable and reliable pruning behavior. We evaluate static depth pruning, static width pruning, and dynamic pruning across 17 tasks spanning classification, generation, and reasoning. Our results reveal clear paradigm-dependent differences: depth pruning outperforms width pruning on classification tasks, while width pruning is more robust for generation and reasoning. Moreover, static pruning better preserves reasoning performance, whereas dynamic pruning excels on classification and generation but remains challenging for long-chain reasoning. These findings underscore the need for pruning strategies that explicitly account for the distinct characteristics of reasoning-augmented LLMs. Our code is publicly available at https://github.com/EIT-NLP/LRM-Pruning.
Too Good to be Bad: On the Failure of LLMs to Role-Play Villains
Nov 12, 2025Large Language Models (LLMs) are increasingly tasked with creative generation, including the simulation of fictional characters. However, their ability to portray non-prosocial, antagonistic personas remains largely unexamined. We hypothesize that the safety alignment of modern LLMs creates a fundamental conflict with the task of authentically role-playing morally ambiguous or villainous characters. To investigate this, we introduce the Moral RolePlay benchmark, a new dataset featuring a four-level moral alignment scale and a balanced test set for rigorous evaluation. We task state-of-the-art LLMs with role-playing characters from moral paragons to pure villains. Our large-scale evaluation reveals a consistent, monotonic decline in role-playing fidelity as character morality decreases. We find that models struggle most with traits directly antithetical to safety principles, such as ``Deceitful'' and ``Manipulative'', often substituting nuanced malevolence with superficial aggression. Furthermore, we demonstrate that general chatbot proficiency is a poor predictor of villain role-playing ability, with highly safety-aligned models performing particularly poorly. Our work provides the first systematic evidence of this critical limitation, highlighting a key tension between model safety and creative fidelity. Our benchmark and findings pave the way for developing more nuanced, context-aware alignment methods.
BatonVoice: An Operationalist Framework for Enhancing Controllable Speech Synthesis with Linguistic Intelligence from LLMs
Sep 30, 2025The rise of Large Language Models (LLMs) is reshaping multimodel models, with speech synthesis being a prominent application. However, existing approaches often underutilize the linguistic intelligence of these models, typically failing to leverage their powerful instruction-following capabilities. This limitation hinders the model's ability to follow text instructions for controllable Text-to-Speech~(TTS). To address this, we propose a new paradigm inspired by ``operationalism'' that decouples instruction understanding from speech generation. We introduce BatonVoice, a framework where an LLM acts as a ``conductor'', understanding user instructions and generating a textual ``plan'' -- explicit vocal features (e.g., pitch, energy). A separate TTS model, the ``orchestra'', then generates the speech from these features. To realize this component, we develop BatonTTS, a TTS model trained specifically for this task. Our experiments demonstrate that BatonVoice achieves strong performance in controllable and emotional speech synthesis, outperforming strong open- and closed-source baselines. Notably, our approach enables remarkable zero-shot cross-lingual generalization, accurately applying feature control abilities to languages unseen during post-training. This demonstrates that objectifying speech into textual vocal features can more effectively unlock the linguistic intelligence of LLMs.
A1: Asynchronous Test-Time Scaling via Conformal Prediction
Sep 18, 2025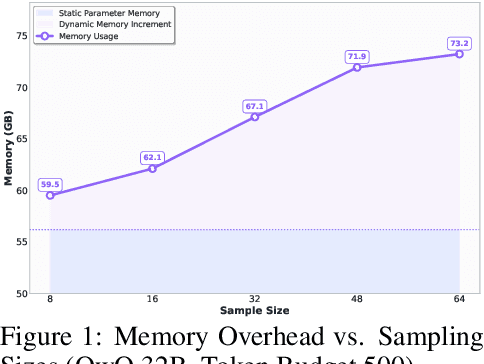
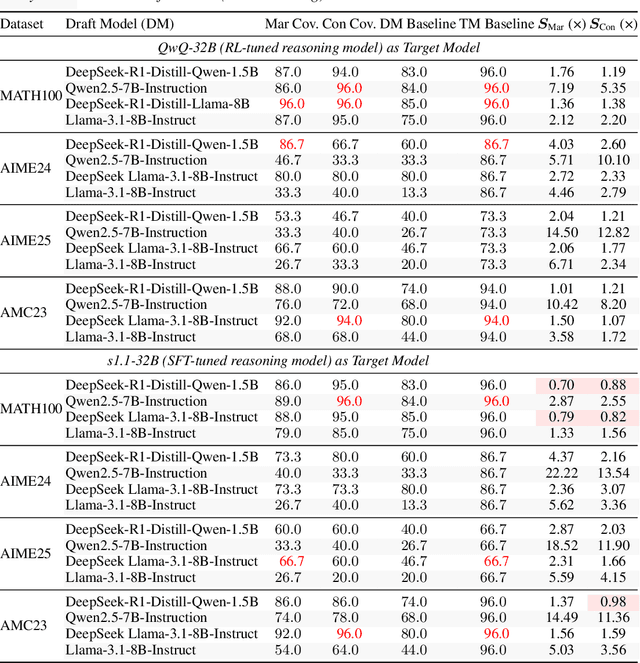
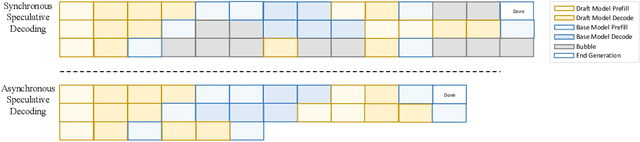
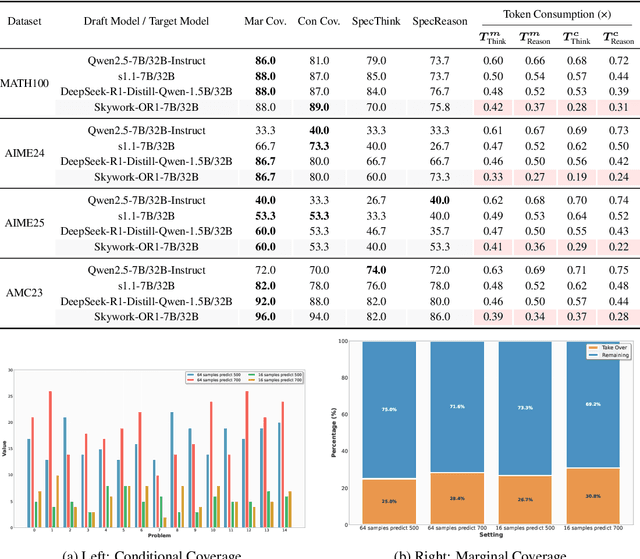
Large language models (LLMs) benefit from test-time scaling, but existing methods face significant challenges, including severe synchronization overhead, memory bottlenecks, and latency, especially during speculative decoding with long reasoning chains. We introduce A1 (Asynchronous Test-Time Scaling), a statistically guaranteed adaptive inference framework that addresses these challenges. A1 refines arithmetic intensity to identify synchronization as the dominant bottleneck, proposes an online calibration strategy to enable asynchronous inference, and designs a three-stage rejection sampling pipeline that supports both sequential and parallel scaling. Through experiments on the MATH, AMC23, AIME24, and AIME25 datasets, across various draft-target model families, we demonstrate that A1 achieves a remarkable 56.7x speedup in test-time scaling and a 4.14x improvement in throughput, all while maintaining accurate rejection-rate control, reducing latency and memory overhead, and no accuracy loss compared to using target model scaling alone. These results position A1 as an efficient and principled solution for scalable LLM inference. We have released the code at https://github.com/menik1126/asynchronous-test-time-scaling.
CogDual: Enhancing Dual Cognition of LLMs via Reinforcement Learning with Implicit Rule-Based Rewards
Jul 23, 2025



Role-Playing Language Agents (RPLAs) have emerged as a significant application direction for Large Language Models (LLMs). Existing approaches typically rely on prompt engineering or supervised fine-tuning to enable models to imitate character behaviors in specific scenarios, but often neglect the underlying \emph{cognitive} mechanisms driving these behaviors. Inspired by cognitive psychology, we introduce \textbf{CogDual}, a novel RPLA adopting a \textit{cognize-then-respond } reasoning paradigm. By jointly modeling external situational awareness and internal self-awareness, CogDual generates responses with improved character consistency and contextual alignment. To further optimize the performance, we employ reinforcement learning with two general-purpose reward schemes designed for open-domain text generation. Extensive experiments on the CoSER benchmark, as well as Cross-MR and LifeChoice, demonstrate that CogDual consistently outperforms existing baselines and generalizes effectively across diverse role-playing tasks.