 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodeV-R1: Reasoning-Enhanced Verilog Generation
May 30, 2025Large language models (LLMs) trained via reinforcement learning with verifiable reward (RLVR) have achieved breakthroughs on tasks with explicit, automatable verification, such as software programming and mathematical problems. Extending RLVR to electronic design automation (EDA), especially automatically generating hardware description languages (HDLs) like Verilog from natural-language (NL) specifications, however, poses three key challenges: the lack of automated and accurate verification environments, the scarcity of high-quality NL-code pairs, and the prohibitive computation cost of RLVR. To this end, we introduce CodeV-R1, an RLVR framework for training Verilog generation LLMs. First, we develop a rule-based testbench generator that performs robust equivalence checking against golden references. Second, we propose a round-trip data synthesis method that pairs open-source Verilog snippets with LLM-generated NL descriptions, verifies code-NL-code consistency via the generated testbench, and filters out inequivalent examples to yield a high-quality dataset. Third, we employ a two-stage "distill-then-RL" training pipeline: distillation for the cold start of reasoning abilities, followed by adaptive DAPO, our novel RLVR algorithm that can reduce training cost by adaptively adjusting sampling rate. The resulting model, CodeV-R1-7B, achieves 68.6% and 72.9% pass@1 on VerilogEval v2 and RTLLM v1.1, respectively, surpassing prior state-of-the-art by 12~20%, while matching or even exceeding the performance of 671B DeepSeek-R1. We will release our model, training pipeline, and dataset to facilitate research in EDA and LLM communities.
Pangu DeepDiver: Adaptive Search Intensity Scaling via Open-Web Reinforcement Learning
May 30, 2025Information seeking demands iterative evidence gathering and reflective reasoning, yet large language models (LLMs) still struggle with it in open-web question answering. Existing methods rely on static prompting rules or training with Wikipedia-based corpora and retrieval environments, limiting adaptability to the real-world web environment where ambiguity, conflicting evidence, and noise are prevalent. These constrained training settings hinder LLMs from learning to dynamically decide when and where to search, and how to adjust search depth and frequency based on informational demands. We define this missing capacity as Search Intensity Scaling (SIS)--the emergent skill to intensify search efforts under ambiguous or conflicting conditions, rather than settling on overconfident, under-verification answers. To study SIS, we introduce WebPuzzle, the first dataset designed to foster information-seeking behavior in open-world internet environments. WebPuzzle consists of 24K training instances and 275 test questions spanning both wiki-based and open-web queries. Building on this dataset, we propose DeepDiver, a Reinforcement Learning (RL) framework that promotes SIS by encouraging adaptive search policies through exploration under a real-world open-web environment. Experimental results show that Pangu-7B-Reasoner empowered by DeepDiver achieve performance on real-web tasks comparable to the 671B-parameter DeepSeek-R1. We detail DeepDiver's training curriculum from cold-start supervised fine-tuning to a carefully designed RL phase, and present that its capability of SIS generalizes from closed-form QA to open-ended tasks such as long-form writing. Our contributions advance adaptive information seeking in LLMs and provide a valuable benchmark and dataset for future research.
InverseCoder: Unleashing the Power of Instruction-Tuned Code LLMs with Inverse-Instruct
Jul 08, 2024Recent advancements in open-source code large language models (LLMs) have demonstrated remarkable coding abilities by fine-tuning on the data generated from powerful closed-source LLMs such as GPT-3.5 and GPT-4 for instruction tuning. This paper explores how to further improve an instruction-tuned code LLM by generating data from itself rather than querying closed-source LLMs. Our key observation is the misalignment between the translation of formal and informal languages: translating formal language (i.e., code) to informal language (i.e., natural language) is more straightforward than the reverse. Based on this observation, we propose INVERSE-INSTRUCT, which summarizes instructions from code snippets instead of the reverse. Specifically, given an instruction tuning corpus for code and the resulting instruction-tuned code LLM, we ask the code LLM to generate additional high-quality instructions for the original corpus through code summarization and self-evaluation. Then, we fine-tune the base LLM on the combination of the original corpus and the self-generated one, which yields a stronger instruction-tuned LLM. We present a series of code LLMs named InverseCoder, which surpasses the performance of the original code LLMs on a wide range of benchmarks, including Python text-to-code generation, multilingual coding, and data-science code generation.
Evaluating the External and Parametric Knowledge Fusion of Large Language Models
May 29, 2024



Integrating external knowledge into large language models (LLMs) presents a promising solution to overcome the limitations imposed by their antiquated and static parametric memory. Prior studies, however, have tended to over-reliance on external knowledge, underestimating the valuable contributions of an LLMs' intrinsic parametric knowledge. The efficacy of LLMs in blending external and parametric knowledge remains largely unexplored, especially in cases where external knowledge is incomplete and necessitates supplementation by their parametric knowledge. We propose to deconstruct knowledge fusion into four distinct scenarios, offering the first thorough investigation of LLM behavior across each. We develop a systematic pipeline for data construction and knowledge infusion to simulate these fusion scenarios, facilitating a series of controlled experiments. Our investigation reveals that enhancing parametric knowledge within LLMs can significantly bolster their capability for knowledge integration. Nonetheless, we identify persistent challenges in memorizing and eliciting parametric knowledge, and determining parametric knowledge boundaries. Our findings aim to steer future explorations on harmonizing external and parametric knowledge within LLMs.
Entity-centered Cross-document Relation Extraction
Oct 29, 2022



Relation Extraction (RE) is a fundamental task of information extraction, which has attracted a large amount of research attention. Previous studies focus on extracting the relations within a sentence or document, while currently researchers begin to explore cross-document RE. However, current cross-document RE methods directly utilize text snippets surrounding target entities in multiple given documents, which brings considerable noisy and non-relevant sentences. Moreover, they utilize all the text paths in a document bag in a coarse-grained way, without considering the connections between these text paths.In this paper, we aim to address both of these shortages and push the state-of-the-art for cross-document RE. First, we focus on input construction for our RE model and propose an entity-based document-context filter to retain useful information in the given documents by using the bridge entities in the text paths. Second, we propose a cross-document RE model based on cross-path entity relation attention, which allow the entity relations across text paths to interact with each other. We compare our cross-document RE method with the state-of-the-art methods in the dataset CodRED. Our method outperforms them by at least 10% in F1, thus demonstrating its effectiveness.
Effective Token Graph Modeling using a Novel Labeling Strategy for Structured Sentiment Analysis
Mar 21, 2022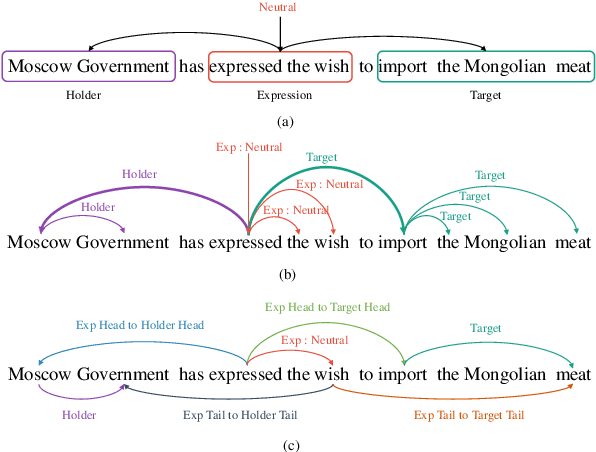
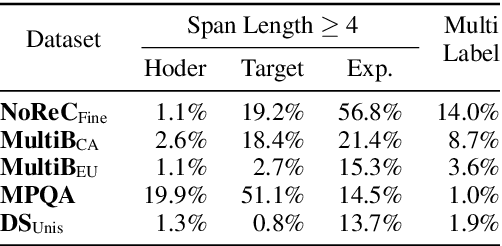

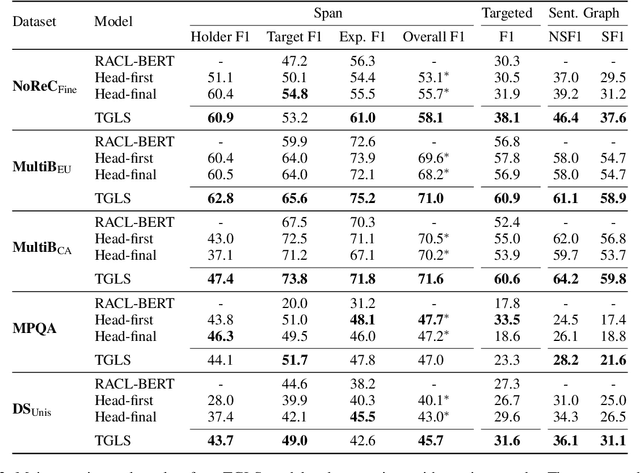
The state-of-the-art model for structured sentiment analysis casts the task as a dependency parsing problem, which has some limitations: (1) The label proportions for span prediction and span relation prediction are imbalanced. (2) The span lengths of sentiment tuple components may be very large in this task, which will further exacerbate the imbalance problem. (3) Two nodes in a dependency graph cannot have multiple arcs, therefore some overlapped sentiment tuples cannot be recognized. In this work, we propose nichetargeting solutions for these issues. First, we introduce a novel labeling strategy, which contains two sets of token pair labels, namely essential label set and whole label set. The essential label set consists of the basic labels for this task, which are relatively balanced and applied in the prediction layer. The whole label set includes rich labels to help our model capture various token relations, which are applied in the hidden layer to softly influence our model. Moreover, we also propose an effective model to well collaborate with our labeling strategy, which is equipped with the graph attention networks to iteratively refine token representations, and the adaptive multi-label classifier to dynamically predict multiple relations between token pairs. We perform extensive experiments on 5 benchmark datasets in four languages. Experimental results show that our model outperforms previous SOTA models by a large margin.