 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeechEditBench: A Bilingual Multi-Attribute Benchmark for Instruction-Guided Speech Editing
Jun 01, 2026Instruction-guided speech editing requires a model to modify specified speech attributes while preserving unrelated characteristics. Despite rapid progress in Speech Large Language Models (Speech LLMs), systematic evaluation of this capability remains challenging, as existing benchmarks are fragmented across isolated editing tasks. To bridge this gap, we introduce \textbf{SpeechEditBench}, a bilingual multi-attribute benchmark for instruction-guided speech editing. SpeechEditBench encompasses seven atomic editing tasks, as well as compositional editing tasks that integrate multiple operations within a single instruction. We propose an anchor-based evaluation protocol that separately assesses the edit success of target attributes and the preservation of untargeted attributes, leading to three metrics: target success, preservation success, and joint success. Using this benchmark, we evaluate mainstream Speech LLMs and specialized speech editing systems. The results reveal three key findings: (1) no single model performs well across all editing dimensions; (2) closed-source Speech LLMs generally outperform open-source models; (3) compositional editing remains highly challenging, with even the most advanced models struggling to achieve high joint success. SpeechEditBench provides a rigorous diagnostic framework to identify bottlenecks in Speech LLMs, thereby facilitating the development of next-generation Speech LLMs with more robust and precise instruction-guided editing capabilities. Data and code will be released upon acceptance.
GRPO-VPS: Enhancing Group Relative Policy Optimization with Verifiable Process Supervision for Effective Reasoning
Apr 22, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has advanced the reasoning capabilities of Large Language Models (LLMs) by leveraging direct outcome verification instead of learned reward models. Building on this paradigm, Group Relative Policy Optimization (GRPO) eliminates the need for critic models but suffers from indiscriminate credit assignment for intermediate steps, which limits its ability to identify effective reasoning strategies and incurs overthinking. In this work, we introduce a model-free and verifiable process supervision via probing the model's belief in the correct answer throughout its reasoning trajectory. By segmenting the generation into discrete steps and tracking the conditional probability of the correct answer appended at each segment boundary, we efficiently compute interpretable segment-wise progress measurements to refine GRPO's trajectory-level feedback. This approach enables more targeted and sample-efficient policy updates, while avoiding the need for intermediate supervision derived from costly Monte Carlo rollouts or auxiliary models. Experiments on mathematical and general-domain benchmarks show consistent gains over GRPO across diverse models: up to 2.6-point accuracy improvements and 13.7% reasoning-length reductions on math tasks, and up to 2.4 points and 4% on general-domain tasks, demonstrating strong generalization.
Merging Beyond: Streaming LLM Updates via Activation-Guided Rotations
Feb 03, 2026The escalating scale of Large Language Models (LLMs) necessitates efficient adaptation techniques. Model merging has gained prominence for its efficiency and controllability. However, existing merging techniques typically serve as post-hoc refinements or focus on mitigating task interference, often failing to capture the dynamic optimization benefits of supervised fine-tuning (SFT). In this work, we propose Streaming Merging, an innovative model updating paradigm that conceptualizes merging as an iterative optimization process. Central to this paradigm is \textbf{ARM} (\textbf{A}ctivation-guided \textbf{R}otation-aware \textbf{M}erging), a strategy designed to approximate gradient descent dynamics. By treating merging coefficients as learning rates and deriving rotation vectors from activation subspaces, ARM effectively steers parameter updates along data-driven trajectories. Unlike conventional linear interpolation, ARM aligns semantic subspaces to preserve the geometric structure of high-dimensional parameter evolution. Remarkably, ARM requires only early SFT checkpoints and, through iterative merging, surpasses the fully converged SFT model. Experimental results across model scales (1.7B to 14B) and diverse domains (e.g., math, code) demonstrate that ARM can transcend converged checkpoints. Extensive experiments show that ARM provides a scalable and lightweight framework for efficient model adaptation.
OVD: On-policy Verbal Distillation
Jan 29, 2026Knowledge distillation offers a promising path to transfer reasoning capabilities from large teacher models to efficient student models; however, existing token-level on-policy distillation methods require token-level alignment between the student and teacher models, which restricts the student model's exploration ability, prevent effective use of interactive environment feedback, and suffer from severe memory bottlenecks in reinforcement learning. We introduce On-policy Verbal Distillation (OVD), a memory-efficient framework that replaces token-level probability matching with trajectory matching using discrete verbal scores (0--9) from teacher models. OVD dramatically reduces memory consumption while enabling on-policy distillation from teacher models with verbal feedback, and avoids token-level alignment, allowing the student model to freely explore the output space. Extensive experiments on Web question answering and mathematical reasoning tasks show that OVD substantially outperforms existing methods, delivering up to +12.9% absolute improvement in average EM on Web Q&A tasks and a up to +25.7% gain on math benchmarks (when trained with only one random samples), while also exhibiting superior training efficiency. Our project page is available at https://OVD.github.io
DSA-Tokenizer: Disentangled Semantic-Acoustic Tokenization via Flow Matching-based Hierarchical Fusion
Jan 15, 2026Speech tokenizers serve as the cornerstone of discrete Speech Large Language Models (Speech LLMs). Existing tokenizers either prioritize semantic encoding, fuse semantic content with acoustic style inseparably, or achieve incomplete semantic-acoustic disentanglement. To achieve better disentanglement, we propose DSA-Tokenizer, which explicitly disentangles speech into discrete semantic and acoustic tokens via distinct optimization constraints. Specifically, semantic tokens are supervised by ASR to capture linguistic content, while acoustic tokens focus on mel-spectrograms restoration to encode style. To eliminate rigid length constraints between the two sequences, we introduce a hierarchical Flow-Matching decoder that further improve speech generation quality. Furthermore, We employ a joint reconstruction-recombination training strategy to enforce this separation. DSA-Tokenizer enables high fidelity reconstruction and flexible recombination through robust disentanglement, facilitating controllable generation in speech LLMs. Our analysis highlights disentangled tokenization as a pivotal paradigm for future speech modeling. Audio samples are avaialble at https://anonymous.4open.science/w/DSA_Tokenizer_demo/. The code and model will be made publicly available after the paper has been accepted.
A1: Asynchronous Test-Time Scaling via Conformal Prediction
Sep 18, 2025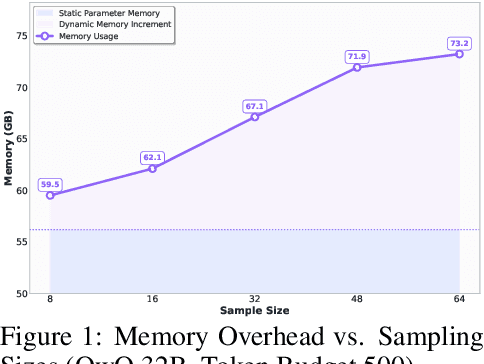
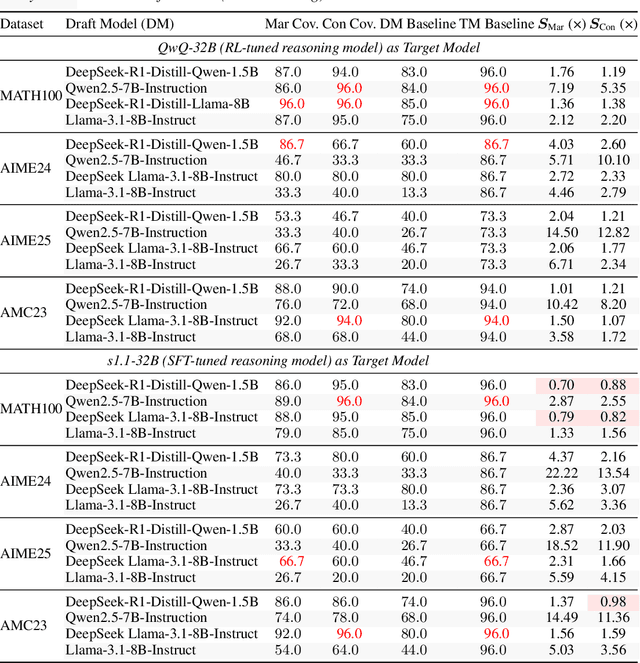
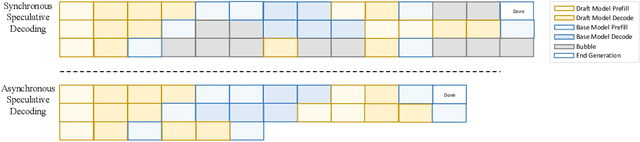
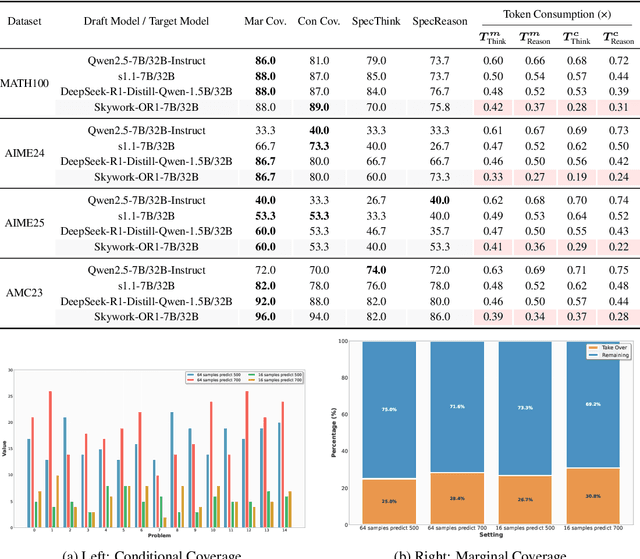
Large language models (LLMs) benefit from test-time scaling, but existing methods face significant challenges, including severe synchronization overhead, memory bottlenecks, and latency, especially during speculative decoding with long reasoning chains. We introduce A1 (Asynchronous Test-Time Scaling), a statistically guaranteed adaptive inference framework that addresses these challenges. A1 refines arithmetic intensity to identify synchronization as the dominant bottleneck, proposes an online calibration strategy to enable asynchronous inference, and designs a three-stage rejection sampling pipeline that supports both sequential and parallel scaling. Through experiments on the MATH, AMC23, AIME24, and AIME25 datasets, across various draft-target model families, we demonstrate that A1 achieves a remarkable 56.7x speedup in test-time scaling and a 4.14x improvement in throughput, all while maintaining accurate rejection-rate control, reducing latency and memory overhead, and no accuracy loss compared to using target model scaling alone. These results position A1 as an efficient and principled solution for scalable LLM inference. We have released the code at https://github.com/menik1126/asynchronous-test-time-scaling.
Pangu DeepDiver: Adaptive Search Intensity Scaling via Open-Web Reinforcement Learning
May 30, 2025Information seeking demands iterative evidence gathering and reflective reasoning, yet large language models (LLMs) still struggle with it in open-web question answering. Existing methods rely on static prompting rules or training with Wikipedia-based corpora and retrieval environments, limiting adaptability to the real-world web environment where ambiguity, conflicting evidence, and noise are prevalent. These constrained training settings hinder LLMs from learning to dynamically decide when and where to search, and how to adjust search depth and frequency based on informational demands. We define this missing capacity as Search Intensity Scaling (SIS)--the emergent skill to intensify search efforts under ambiguous or conflicting conditions, rather than settling on overconfident, under-verification answers. To study SIS, we introduce WebPuzzle, the first dataset designed to foster information-seeking behavior in open-world internet environments. WebPuzzle consists of 24K training instances and 275 test questions spanning both wiki-based and open-web queries. Building on this dataset, we propose DeepDiver, a Reinforcement Learning (RL) framework that promotes SIS by encouraging adaptive search policies through exploration under a real-world open-web environment. Experimental results show that Pangu-7B-Reasoner empowered by DeepDiver achieve performance on real-web tasks comparable to the 671B-parameter DeepSeek-R1. We detail DeepDiver's training curriculum from cold-start supervised fine-tuning to a carefully designed RL phase, and present that its capability of SIS generalizes from closed-form QA to open-ended tasks such as long-form writing. Our contributions advance adaptive information seeking in LLMs and provide a valuable benchmark and dataset for future research.
TIME: A Multi-level Benchmark for Temporal Reasoning of LLMs in Real-World Scenarios
May 19, 2025Temporal reasoning is pivotal for Large Language Models (LLMs) to comprehend the real world. However, existing works neglect the real-world challenges for temporal reasoning: (1) intensive temporal information, (2) fast-changing event dynamics, and (3) complex temporal dependencies in social interactions. To bridge this gap, we propose a multi-level benchmark TIME, designed for temporal reasoning in real-world scenarios. TIME consists of 38,522 QA pairs, covering 3 levels with 11 fine-grained sub-tasks. This benchmark encompasses 3 sub-datasets reflecting different real-world challenges: TIME-Wiki, TIME-News, and TIME-Dial. We conduct extensive experiments on reasoning models and non-reasoning models. And we conducted an in-depth analysis of temporal reasoning performance across diverse real-world scenarios and tasks, and summarized the impact of test-time scaling on temporal reasoning capabilities. Additionally, we release TIME-Lite, a human-annotated subset to foster future research and standardized evaluation in temporal reasoning. The code is available at https://github.com/sylvain-wei/TIME , and the dataset is available at https://huggingface.co/datasets/SylvainWei/TIME .
MR-BEN: A Comprehensive Meta-Reasoning Benchmark for Large Language Models
Jun 20, 2024



Large language models (LLMs) have shown increasing capability in problem-solving and decision-making, largely based on the step-by-step chain-of-thought reasoning processes. However, it has been increasingly challenging to evaluate the reasoning capability of LLMs. Concretely, existing outcome-based benchmarks begin to saturate and become less sufficient to monitor the progress. To this end, we present a process-based benchmark MR-BEN that demands a meta reasoning skill, where LMs are asked to locate and analyse potential errors in automatically generated reasoning steps. MR-BEN is a comprehensive benchmark comprising 5,975 questions collected from human experts, covering various subjects such as physics, chemistry, logic, coding, and more. Through our designed metrics for assessing meta-reasoning on this benchmark, we identify interesting limitations and weaknesses of current LLMs (open-source and closed-source models). For example, open-source models are seemingly comparable to GPT-4 on outcome-based benchmarks, but they lag far behind on our benchmark, revealing the underlying reasoning capability gap between them. Our dataset and codes are available on https://randolph-zeng.github.io/Mr-Ben.github.io/.
MHPP: Exploring the Capabilities and Limitations of Language Models Beyond Basic Code Generation
May 19, 2024



Recent advancements in large language models (LLMs) have greatly improved code generation, specifically at the function level. For instance, GPT-4 has achieved an 88.4% pass rate on HumanEval. However, this draws into question the adequacy of existing benchmarks in thoroughly assessing function-level code generation capabilities. Our study analyzed two common benchmarks, HumanEval and MBPP, and found that these might not thoroughly evaluate LLMs' code generation capacities due to limitations in quality, difficulty, and granularity. To resolve this, we introduce the Mostly Hard Python Problems (MHPP) dataset, consisting of 140 unique human-curated problems. By focusing on the combination of natural language and code reasoning, MHPP gauges LLMs' abilities to comprehend specifications and restrictions, engage in multi-step reasoning, and apply coding knowledge effectively. Initial evaluations of 22 LLMs using MHPP showed many high-performing models on HumanEval failed to achieve similar success on MHPP. Moreover, MHPP highlighted various previously undiscovered limitations within various LLMs, leading us to believe that it could pave the way for a better understanding of LLMs' capabilities and limitations. Dataset and code are available at https://github.com/SparksofAGI/MHPP.