 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDriving Intents Amplify Planning-Oriented Reinforcement Learning
May 14, 2026Continuous-action policies trained on a single demonstrated trajectory per scene suffer from mode collapse: samples cluster around the demonstrated maneuver and the policy cannot represent semantically distinct alternatives. Under preference-based evaluation, this caps best-of-N performance -- even oracle selection cannot recover what the sampling distribution does not contain. We introduce DIAL, a two-stage Driving-Intent-Amplified reinforcement Learning framework for preference-aligned continuous-action driving policies. In the first stage, DIAL conditions the flow-matching action head on a discrete intent label with classifier-free guidance (CFG), which expands the sampling distribution along distinct maneuver modes and breaks single-demonstration mode collapse. In the second stage, DIAL carries this expanded distribution into preference RL through multi-intent GRPO, which spans all intent classes within every preference group and prevents fine-tuning from re-collapsing around the currently preferred mode. Instantiated for end-to-end driving with eight rule-derived intents and evaluated on WOD-E2E: competitive Vision-to-Action (VA) and Vision-Language-Action (VLA) Supervised Finetuning (SFT) baselines plateau below the human-driven demonstration at best-of-128, with the strongest prior (RAP) capping at Rater Feedback Score (RFS) 8.5 even with best-of-64; intent-CFG sampling lifts this ceiling to RFS 9.14 at best-of-128, surpassing both the prior best (RAP 8.5) and the human-driven demonstration (8.13) for the first time; and multi-intent GRPO improves held-out RFS from 7.681 to 8.211, while every single-intent baseline peaks lower and degrades by training end. These results suggest that the bottleneck of preference RL on continuous-action policies trained from demonstrations is not only how to update the policy, but to expand and preserve the sampling distribution being optimized.
Action Emergence from Streaming Intent
May 14, 2026We formalize action emergence as a target capability for end-to-end autonomous driving: the ability to generate physically feasible, semantically appropriate, and safety-compliant actions in arbitrary, long-tail traffic scenes through scene-conditioned reasoning rather than retrieval or interpolation of learned scene-action mappings. We show that previous paradigms cannot deliver action emergence: autoregressive trajectory decoders collapse the inherently multimodal future into a single averaged output, while diffusion and flow-matching generators express multimodality but are not steerable by reasoned intent. We propose Streaming Intent as a concrete way to approach action emergence: a mechanism that makes driving intent (i) semantically streamed through a continuous chain-of-thought that causally derives the intent from scene understanding, and (ii) temporally streamed across clips so that intent commitments remain coherent along the driving horizon. We realize Streaming Intent in a VLA model we call SI (Streaming Intent). SI autoregressively decodes a four-step chain-of-thought and emits an intent token; the decoded intent then drives classifier-free guidance (CFG) on a flow-matching action head, requiring only two denoising steps to generate the final trajectory. On the Waymo End-to-End benchmark, SI achieves competitive aggregate performance, with an RFS score of 7.96 on the validation set and 7.74 on the test set. Beyond aggregate metrics, the model demonstrates -- to our knowledge for the first time in a fully end-to-end VLA -- intent-faithful controllability: for a fixed scene, varying the intent class at inference yields qualitatively distinct yet consistently high-quality plans, arising purely from data-driven learning without any pre-built trajectory bank or hand-coded post-hoc selector.
MindVLA-U1: VLA Beats VA with Unified Streaming Architecture for Autonomous Driving
May 14, 2026Autonomous driving has progressed from modular pipelines toward end-to-end unification, and Vision-Language-Action (VLA) models are a natural extension of this journey beyond Vision-to-Action (VA). In practice, driving VLAs have often trailed VA on planning quality, suggesting that the difficulty is not simply model scale but the interface through which semantic reasoning, temporal context, and continuous control are combined. We argue that this gap reflects how VLA has been built -- as isolated subtask improvements that fail to compose coherent driving capabilities -- rather than what VLA is. We present MindVLA-U1, the first unified streaming VLA architecture for autonomous driving. A unified VLM backbone produces AR language tokens (optional) and flow-matching continuous action trajectories in a single forward pass over one shared representation, preserving the natural output form of each modality. A full streaming design processes the driving video framewise rather than as fixed video-action chunks under costly temporal VLM modeling. Planned trajectories evolve smoothly across frames while a learned streaming memory channel carries temporal context and updates. The unified architecture enables fast/slow systems on dense & sparse MoT backbones via flexible self-attention context management, and exposes a measurable language-control path for action: language-predicted driving intents steers the action diffusion via classifier-free guidance (CFG), turning language-side intent into control signals for continuous action planning. On the long-tail WOD-E2E benchmark, MindVLA-U1 surpasses experienced human drivers for the first time (8.20 RFS vs. 8.13 GT RFS) with 2 diffusion steps, achieves state-of-the-art planning ADEs over prior VA/VLA by large margins, and matches VA latency (16 FPS vs. RAP's 18 FPS at 1B scale) while preserving natural language interfaces for human-vehicle interaction.
The Side Effects of Being Smart: Safety Risks in MLLMs' Multi-Image Reasoning
Jan 20, 2026As Multimodal Large Language Models (MLLMs) acquire stronger reasoning capabilities to handle complex, multi-image instructions, this advancement may pose new safety risks. We study this problem by introducing MIR-SafetyBench, the first benchmark focused on multi-image reasoning safety, which consists of 2,676 instances across a taxonomy of 9 multi-image relations. Our extensive evaluations on 19 MLLMs reveal a troubling trend: models with more advanced multi-image reasoning can be more vulnerable on MIR-SafetyBench. Beyond attack success rates, we find that many responses labeled as safe are superficial, often driven by misunderstanding or evasive, non-committal replies. We further observe that unsafe generations exhibit lower attention entropy than safe ones on average. This internal signature suggests a possible risk that models may over-focus on task solving while neglecting safety constraints. Our code and data are available at https://github.com/thu-coai/MIR-SafetyBench.
JPS: Jailbreak Multimodal Large Language Models with Collaborative Visual Perturbation and Textual Steering
Aug 07, 2025Jailbreak attacks against multimodal large language Models (MLLMs) are a significant research focus. Current research predominantly focuses on maximizing attack success rate (ASR), often overlooking whether the generated responses actually fulfill the attacker's malicious intent. This oversight frequently leads to low-quality outputs that bypass safety filters but lack substantial harmful content. To address this gap, we propose JPS, \underline{J}ailbreak MLLMs with collaborative visual \underline{P}erturbation and textual \underline{S}teering, which achieves jailbreaks via corporation of visual image and textually steering prompt. Specifically, JPS utilizes target-guided adversarial image perturbations for effective safety bypass, complemented by "steering prompt" optimized via a multi-agent system to specifically guide LLM responses fulfilling the attackers' intent. These visual and textual components undergo iterative co-optimization for enhanced performance. To evaluate the quality of attack outcomes, we propose the Malicious Intent Fulfillment Rate (MIFR) metric, assessed using a Reasoning-LLM-based evaluator. Our experiments show JPS sets a new state-of-the-art in both ASR and MIFR across various MLLMs and benchmarks, with analyses confirming its efficacy. Codes are available at \href{https://github.com/thu-coai/JPS}{https://github.com/thu-coai/JPS}. \color{warningcolor}{Warning: This paper contains potentially sensitive contents.}
Lumina-mGPT 2.0: Stand-Alone AutoRegressive Image Modeling
Jul 23, 2025
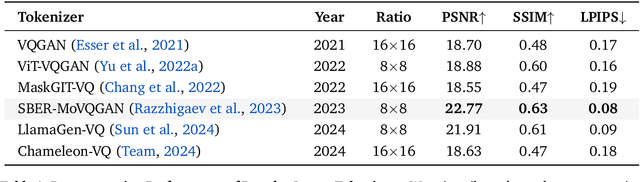
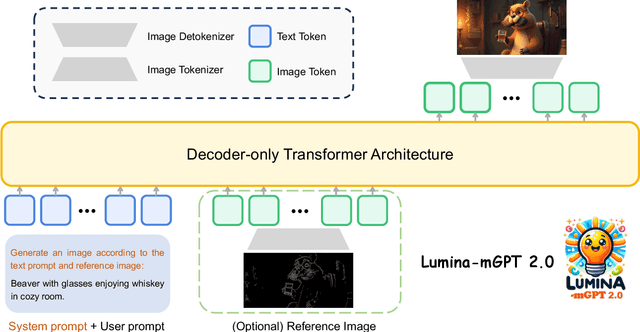

We present Lumina-mGPT 2.0, a stand-alone, decoder-only autoregressive model that revisits and revitalizes the autoregressive paradigm for high-quality image generation and beyond. Unlike existing approaches that rely on pretrained components or hybrid architectures, Lumina-mGPT 2.0 is trained entirely from scratch, enabling unrestricted architectural design and licensing freedom. It achieves generation quality on par with state-of-the-art diffusion models such as DALL-E 3 and SANA, while preserving the inherent flexibility and compositionality of autoregressive modeling. Our unified tokenization scheme allows the model to seamlessly handle a wide spectrum of tasks-including subject-driven generation, image editing, controllable synthesis, and dense prediction-within a single generative framework. To further boost usability, we incorporate efficient decoding strategies like inference-time scaling and speculative Jacobi sampling to improve quality and speed, respectively. Extensive evaluations on standard text-to-image benchmarks (e.g., GenEval, DPG) demonstrate that Lumina-mGPT 2.0 not only matches but in some cases surpasses diffusion-based models. Moreover, we confirm its multi-task capabilities on the Graph200K benchmark, with the native Lumina-mGPT 2.0 performing exceptionally well. These results position Lumina-mGPT 2.0 as a strong, flexible foundation model for unified multimodal generation. We have released our training details, code, and models at https://github.com/Alpha-VLLM/Lumina-mGPT-2.0.
How Should We Enhance the Safety of Large Reasoning Models: An Empirical Study
May 21, 2025Large Reasoning Models (LRMs) have achieved remarkable success on reasoning-intensive tasks such as mathematics and programming. However, their enhanced reasoning capabilities do not necessarily translate to improved safety performance-and in some cases, may even degrade it. This raises an important research question: how can we enhance the safety of LRMs? In this paper, we present a comprehensive empirical study on how to enhance the safety of LRMs through Supervised Fine-Tuning (SFT). Our investigation begins with an unexpected observation: directly distilling safe responses from DeepSeek-R1 fails to significantly enhance safety. We analyze this phenomenon and identify three key failure patterns that contribute to it. We then demonstrate that explicitly addressing these issues during the data distillation process can lead to substantial safety improvements. Next, we explore whether a long and complex reasoning process is necessary for achieving safety. Interestingly, we find that simply using short or template-based reasoning process can attain comparable safety performance-and are significantly easier for models to learn than more intricate reasoning chains. These findings prompt a deeper reflection on the role of reasoning in ensuring safety. Finally, we find that mixing math reasoning data during safety fine-tuning is helpful to balance safety and over-refusal. Overall, we hope our empirical study could provide a more holistic picture on enhancing the safety of LRMs. The code and data used in our experiments are released in https://github.com/thu-coai/LRM-Safety-Study.
Vision-to-Music Generation: A Survey
Mar 27, 2025Vision-to-music Generation, including video-to-music and image-to-music tasks, is a significant branch of multimodal artificial intelligence demonstrating vast application prospects in fields such as film scoring, short video creation, and dance music synthesis. However, compared to the rapid development of modalities like text and images, research in vision-to-music is still in its preliminary stage due to its complex internal structure and the difficulty of modeling dynamic relationships with video. Existing surveys focus on general music generation without comprehensive discussion on vision-to-music. In this paper, we systematically review the research progress in the field of vision-to-music generation. We first analyze the technical characteristics and core challenges for three input types: general videos, human movement videos, and images, as well as two output types of symbolic music and audio music. We then summarize the existing methodologies on vision-to-music generation from the architecture perspective. A detailed review of common datasets and evaluation metrics is provided. Finally, we discuss current challenges and promising directions for future research. We hope our survey can inspire further innovation in vision-to-music generation and the broader field of multimodal generation in academic research and industrial applications. To follow latest works and foster further innovation in this field, we are continuously maintaining a GitHub repository at https://github.com/wzk1015/Awesome-Vision-to-Music-Generation.
TIDE : Temporal-Aware Sparse Autoencoders for Interpretable Diffusion Transformers in Image Generation
Mar 10, 2025Diffusion Transformers (DiTs) are a powerful yet underexplored class of generative models compared to U-Net-based diffusion models. To bridge this gap, we introduce TIDE (Temporal-aware Sparse Autoencoders for Interpretable Diffusion transformErs), a novel framework that enhances temporal reconstruction within DiT activation layers across denoising steps. TIDE employs Sparse Autoencoders (SAEs) with a sparse bottleneck layer to extract interpretable and hierarchical features, revealing that diffusion models inherently learn hierarchical features at multiple levels (e.g., 3D, semantic, class) during generative pre-training. Our approach achieves state-of-the-art reconstruction performance, with a mean squared error (MSE) of 1e-3 and a cosine similarity of 0.97, demonstrating superior accuracy in capturing activation dynamics along the denoising trajectory. Beyond interpretability, we showcase TIDE's potential in downstream applications such as sparse activation-guided image editing and style transfer, enabling improved controllability for generative systems. By providing a comprehensive training and evaluation protocol tailored for DiTs, TIDE contributes to developing more interpretable, transparent, and trustworthy generative models.
Beyond Sight: Towards Cognitive Alignment in LVLM via Enriched Visual Knowledge
Nov 25, 2024



Does seeing always mean knowing? Large Vision-Language Models (LVLMs) integrate separately pre-trained vision and language components, often using CLIP-ViT as vision backbone. However, these models frequently encounter a core issue of "cognitive misalignment" between the vision encoder (VE) and the large language model (LLM). Specifically, the VE's representation of visual information may not fully align with LLM's cognitive framework, leading to a mismatch where visual features exceed the language model's interpretive range. To address this, we investigate how variations in VE representations influence LVLM comprehension, especially when the LLM faces VE-Unknown data-images whose ambiguous visual representations challenge the VE's interpretive precision. Accordingly, we construct a multi-granularity landmark dataset and systematically examine the impact of VE-Known and VE-Unknown data on interpretive abilities. Our results show that VE-Unknown data limits LVLM's capacity for accurate understanding, while VE-Known data, rich in distinctive features, helps reduce cognitive misalignment. Building on these insights, we propose Entity-Enhanced Cognitive Alignment (EECA), a method that employs multi-granularity supervision to generate visually enriched, well-aligned tokens that not only integrate within the LLM's embedding space but also align with the LLM's cognitive framework. This alignment markedly enhances LVLM performance in landmark recognition. Our findings underscore the challenges posed by VE-Unknown data and highlight the essential role of cognitive alignment in advancing multimodal systems.