 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMARTCAL: An Approach to Self-Aware Tool-Use Evaluation and Calibration
Dec 11, 2024



The tool-use ability of Large Language Models (LLMs) has a profound impact on a wide range of industrial applications. However, LLMs' self-control and calibration capability in appropriately using tools remains understudied. The problem is consequential as it raises potential risks of degraded performance and poses a threat to the trustworthiness of the models. In this paper, we conduct a study on a family of state-of-the-art LLMs on three datasets with two mainstream tool-use frameworks. Our study reveals the tool-abuse behavior of LLMs, a tendency for models to misuse tools with overconfidence. We also find that this is a common issue regardless of model capability. Accordingly, we propose a novel approach, \textit{SMARTCAL}, to mitigate the observed issues, and our results show an average of 8.6 percent increase in the QA performance and a 21.6 percent decrease in Expected Calibration Error (ECE) compared to baseline models.
Reducing Distraction in Long-Context Language Models by Focused Learning
Nov 08, 2024



Recent advancements in Large Language Models (LLMs) have significantly enhanced their capacity to process long contexts. However, effectively utilizing this long context remains a challenge due to the issue of distraction, where irrelevant information dominates lengthy contexts, causing LLMs to lose focus on the most relevant segments. To address this, we propose a novel training method that enhances LLMs' ability to discern relevant information through a unique combination of retrieval-based data augmentation and contrastive learning. Specifically, during fine-tuning with long contexts, we employ a retriever to extract the most relevant segments, serving as augmented inputs. We then introduce an auxiliary contrastive learning objective to explicitly ensure that outputs from the original context and the retrieved sub-context are closely aligned. Extensive experiments on long single-document and multi-document QA benchmarks demonstrate the effectiveness of our proposed method.
Enhancing ID-based Recommendation with Large Language Models
Nov 04, 2024Large Language Models (LLMs) have recently garnered significant attention in various domains, including recommendation systems. Recent research leverages the capabilities of LLMs to improve the performance and user modeling aspects of recommender systems. These studies primarily focus on utilizing LLMs to interpret textual data in recommendation tasks. However, it's worth noting that in ID-based recommendations, textual data is absent, and only ID data is available. The untapped potential of LLMs for ID data within the ID-based recommendation paradigm remains relatively unexplored. To this end, we introduce a pioneering approach called "LLM for ID-based Recommendation" (LLM4IDRec). This innovative approach integrates the capabilities of LLMs while exclusively relying on ID data, thus diverging from the previous reliance on textual data. The basic idea of LLM4IDRec is that by employing LLM to augment ID data, if augmented ID data can improve recommendation performance, it demonstrates the ability of LLM to interpret ID data effectively, exploring an innovative way for the integration of LLM in ID-based recommendation. We evaluate the effectiveness of our LLM4IDRec approach using three widely-used datasets. Our results demonstrate a notable improvement in recommendation performance, with our approach consistently outperforming existing methods in ID-based recommendation by solely augmenting input data.
ProGen: Revisiting Probabilistic Spatial-Temporal Time Series Forecasting from a Continuous Generative Perspective Using Stochastic Differential Equations
Nov 02, 2024



Accurate forecasting of spatiotemporal data remains challenging due to complex spatial dependencies and temporal dynamics. The inherent uncertainty and variability in such data often render deterministic models insufficient, prompting a shift towards probabilistic approaches, where diffusion-based generative models have emerged as effective solutions. In this paper, we present ProGen, a novel framework for probabilistic spatiotemporal time series forecasting that leverages Stochastic Differential Equations (SDEs) and diffusion-based generative modeling techniques in the continuous domain. By integrating a novel denoising score model, graph neural networks, and a tailored SDE, ProGen provides a robust solution that effectively captures spatiotemporal dependencies while managing uncertainty. Our extensive experiments on four benchmark traffic datasets demonstrate that ProGen outperforms state-of-the-art deterministic and probabilistic models. This work contributes a continuous, diffusion-based generative approach to spatiotemporal forecasting, paving the way for future research in probabilistic modeling and stochastic processes.
Unauthorized UAV Countermeasure for Low-Altitude Economy: Joint Communications and Jamming based on MIMO Cellular Systems
Oct 31, 2024



To ensure the thriving development of low-altitude economy, countering unauthorized unmanned aerial vehicles (UAVs) is an essential task. The existing widely deployed base stations hold great potential for joint communication and jamming. In light of this, this paper investigates the joint design of beamforming to simultaneously support communication with legitimate users and countermeasure against unauthorized UAVs based on dual-functional multiple-input multiple-output (MIMO) cellular systems. We first formulate a joint communication and jamming (JCJ) problem, relaxing it through semi-definite relaxation (SDR) to obtain a tractable semi-definite programming (SDP) problem, with SDR providing an essential step toward simplifying the complex JCJ design. Although the solution to the relaxed SDP problem cannot directly solve the original problem, it offers valuable insights for further refinement. Therefore, we design a novel constraint specifically tailored to the structure of the SDP problem, ensuring that the solution adheres to the rank-1 constraint of the original problem. Finally, we validate effectiveness of the proposed JCJ scheme through extensive simulations. Simulation codes are provided to reproduce the results in this paper: https://github.com/LiZhuoRan0. The results confirm that the proposed JCJ scheme can operate effectively when the total number of legitimate users and unauthorized UAVs exceeds the number of antennas.
AgentSense: Benchmarking Social Intelligence of Language Agents through Interactive Scenarios
Oct 25, 2024



Large language models (LLMs) are increasingly leveraged to empower autonomous agents to simulate human beings in various fields of behavioral research. However, evaluating their capacity to navigate complex social interactions remains a challenge. Previous studies face limitations due to insufficient scenario diversity, complexity, and a single-perspective focus. To this end, we introduce AgentSense: Benchmarking Social Intelligence of Language Agents through Interactive Scenarios. Drawing on Dramaturgical Theory, AgentSense employs a bottom-up approach to create 1,225 diverse social scenarios constructed from extensive scripts. We evaluate LLM-driven agents through multi-turn interactions, emphasizing both goal completion and implicit reasoning. We analyze goals using ERG theory and conduct comprehensive experiments. Our findings highlight that LLMs struggle with goals in complex social scenarios, especially high-level growth needs, and even GPT-4o requires improvement in private information reasoning.
SeaDAG: Semi-autoregressive Diffusion for Conditional Directed Acyclic Graph Generation
Oct 21, 2024



We introduce SeaDAG, a semi-autoregressive diffusion model for conditional generation of Directed Acyclic Graphs (DAGs). Considering their inherent layer-wise structure, we simulate layer-wise autoregressive generation by designing different denoising speed for different layers. Unlike conventional autoregressive generation that lacks a global graph structure view, our method maintains a complete graph structure at each diffusion step, enabling operations such as property control that require the full graph structure. Leveraging this capability, we evaluate the DAG properties during training by employing a graph property decoder. We explicitly train the model to learn graph conditioning with a condition loss, which enhances the diffusion model's capacity to generate graphs that are both realistic and aligned with specified properties. We evaluate our method on two representative conditional DAG generation tasks: (1) circuit generation from truth tables, where precise DAG structures are crucial for realizing circuit functionality, and (2) molecule generation based on quantum properties. Our approach demonstrates promising results, generating high-quality and realistic DAGs that closely align with given conditions.
OpenR: An Open Source Framework for Advanced Reasoning with Large Language Models
Oct 12, 2024



In this technical report, we introduce OpenR, an open-source framework designed to integrate key components for enhancing the reasoning capabilities of large language models (LLMs). OpenR unifies data acquisition, reinforcement learning training (both online and offline), and non-autoregressive decoding into a cohesive software platform. Our goal is to establish an open-source platform and community to accelerate the development of LLM reasoning. Inspired by the success of OpenAI's o1 model, which demonstrated improved reasoning abilities through step-by-step reasoning and reinforcement learning, OpenR integrates test-time compute, reinforcement learning, and process supervision to improve reasoning in LLMs. Our work is the first to provide an open-source framework that explores the core techniques of OpenAI's o1 model with reinforcement learning, achieving advanced reasoning capabilities beyond traditional autoregressive methods. We demonstrate the efficacy of OpenR by evaluating it on the MATH dataset, utilising publicly available data and search methods. Our initial experiments confirm substantial gains, with relative improvements in reasoning and performance driven by test-time computation and reinforcement learning through process reward models. The OpenR framework, including code, models, and datasets, is accessible at https://openreasoner.github.io.
Logic Synthesis Optimization with Predictive Self-Supervision via Causal Transformers
Sep 16, 2024



Contemporary hardware design benefits from the abstraction provided by high-level logic gates, streamlining the implementation of logic circuits. Logic Synthesis Optimization (LSO) operates at one level of abstraction within the Electronic Design Automation (EDA) workflow, targeting improvements in logic circuits with respect to performance metrics such as size and speed in the final layout. Recent trends in the field show a growing interest in leveraging Machine Learning (ML) for EDA, notably through ML-guided logic synthesis utilizing policy-based Reinforcement Learning (RL) methods.Despite these advancements, existing models face challenges such as overfitting and limited generalization, attributed to constrained public circuits and the expressiveness limitations of graph encoders. To address these hurdles, and tackle data scarcity issues, we introduce LSOformer, a novel approach harnessing Autoregressive transformer models and predictive SSL to predict the trajectory of Quality of Results (QoR). LSOformer integrates cross-attention modules to merge insights from circuit graphs and optimization sequences, thereby enhancing prediction accuracy for QoR metrics. Experimental studies validate the effectiveness of LSOformer, showcasing its superior performance over baseline architectures in QoR prediction tasks, where it achieves improvements of 5.74%, 4.35%, and 17.06% on the EPFL, OABCD, and proprietary circuits datasets, respectively, in inductive setup.
FuXi-2.0: Advancing machine learning weather forecasting model for practical applications
Sep 11, 2024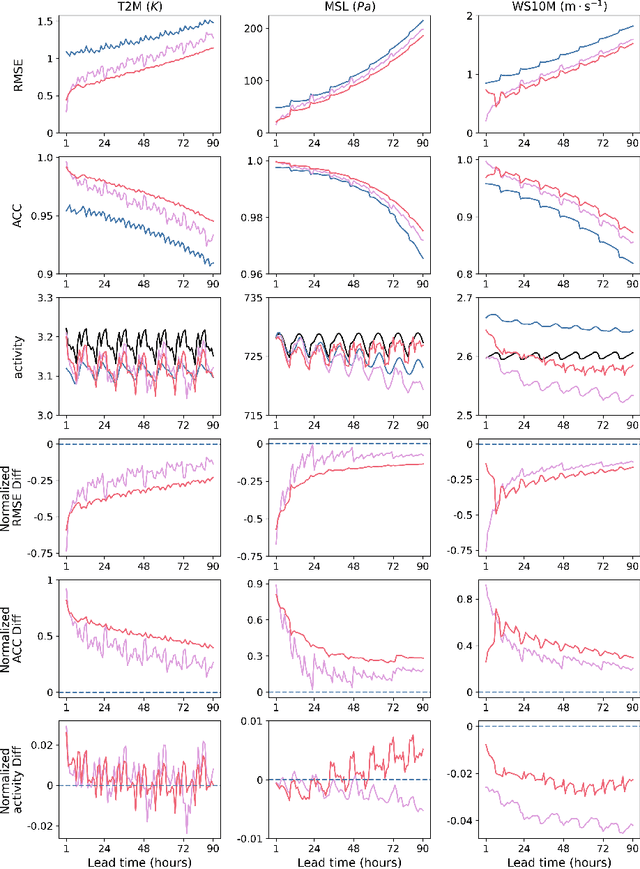
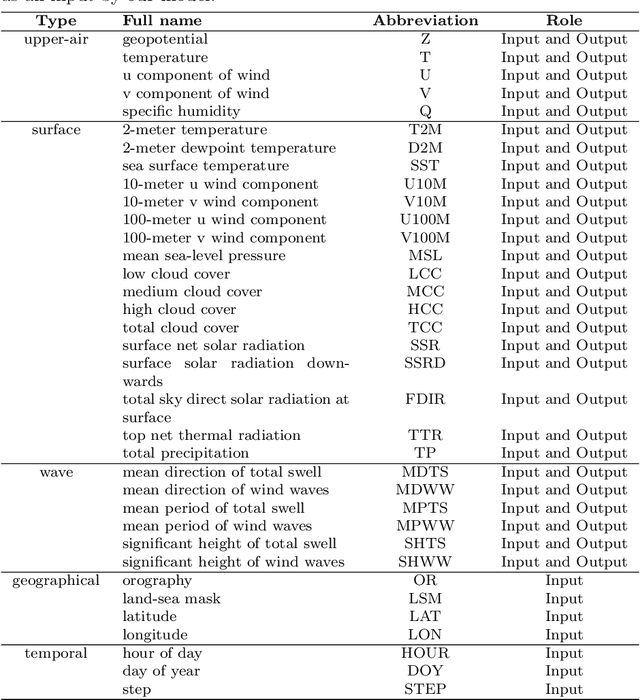
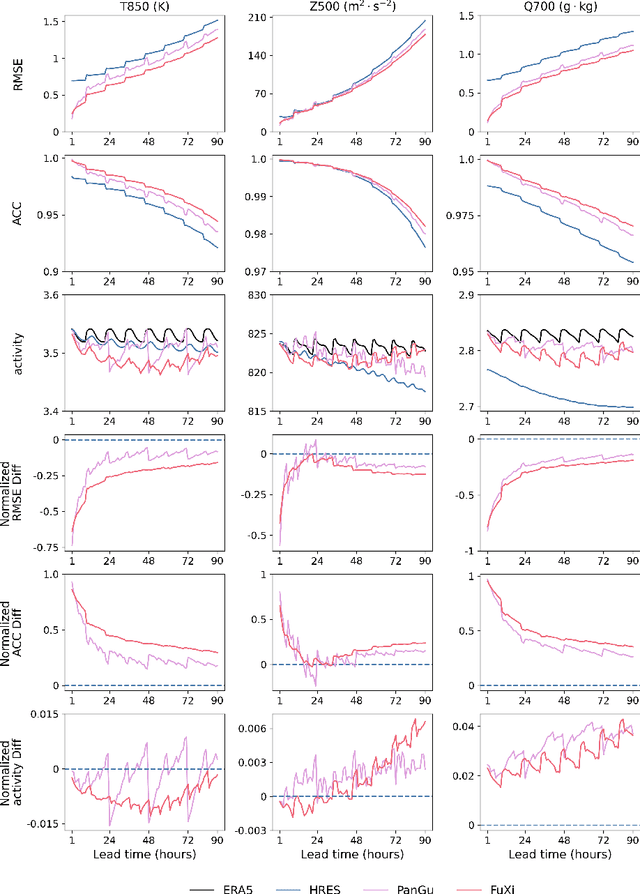
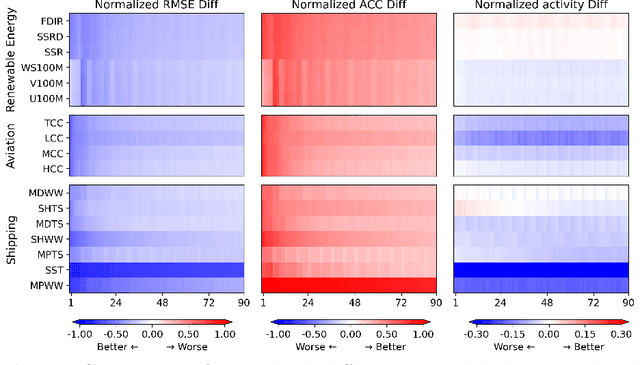
Machine learning (ML) models have become increasingly valuable in weather forecasting, providing forecasts that not only lower computational costs but often match or exceed the accuracy of traditional numerical weather prediction (NWP) models. Despite their potential, ML models typically suffer from limitations such as coarse temporal resolution, typically 6 hours, and a limited set of meteorological variables, limiting their practical applicability. To overcome these challenges, we introduce FuXi-2.0, an advanced ML model that delivers 1-hourly global weather forecasts and includes a comprehensive set of essential meteorological variables, thereby expanding its utility across various sectors like wind and solar energy, aviation, and marine shipping. Our study conducts comparative analyses between ML-based 1-hourly forecasts and those from the high-resolution forecast (HRES) of the European Centre for Medium-Range Weather Forecasts (ECMWF) for various practical scenarios. The results demonstrate that FuXi-2.0 consistently outperforms ECMWF HRES in forecasting key meteorological variables relevant to these sectors. In particular, FuXi-2.0 shows superior performance in wind power forecasting compared to ECMWF HRES, further validating its efficacy as a reliable tool for scenarios demanding precise weather forecasts. Additionally, FuXi-2.0 also integrates both atmospheric and oceanic components, representing a significant step forward in the development of coupled atmospheric-ocean models. Further comparative analyses reveal that FuXi-2.0 provides more accurate forecasts of tropical cyclone intensity than its predecessor, FuXi-1.0, suggesting that there are benefits of an atmosphere-ocean coupled model over atmosphere-only models.