 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest-Time Adaptation for Unsupervised Combinatorial Optimization
Jan 28, 2026Unsupervised neural combinatorial optimization (NCO) enables learning powerful solvers without access to ground-truth solutions. Existing approaches fall into two disjoint paradigms: models trained for generalization across instances, and instance-specific models optimized independently at test time. While the former are efficient during inference, they lack effective instance-wise adaptability; the latter are flexible but fail to exploit learned inductive structure and are prone to poor local optima. This motivates the central question of our work: how can we leverage the inductive bias learned through generalization while unlocking the flexibility required for effective instance-wise adaptation? We first identify a challenge in bridging these two paradigms: generalization-focused models often constitute poor warm starts for instance-wise optimization, potentially underperforming even randomly initialized models when fine-tuned at test time. To resolve this incompatibility, we propose TACO, a model-agnostic test-time adaptation framework that unifies and extends the two existing paradigms for unsupervised NCO. TACO applies strategic warm-starting to partially relax trained parameters while preserving inductive bias, enabling rapid and effective unsupervised adaptation. Crucially, compared to naively fine-tuning a trained generalizable model or optimizing an instance-specific model from scratch, TACO achieves better solution quality while incurring negligible additional computational cost. Experiments on canonical CO problems, Minimum Vertex Cover and Maximum Clique, demonstrate the effectiveness and robustness of TACO across static, distribution-shifted, and dynamic combinatorial optimization problems, establishing it as a practical bridge between generalizable and instance-specific unsupervised NCO.
Kling-Omni Technical Report
Dec 18, 2025



We present Kling-Omni, a generalist generative framework designed to synthesize high-fidelity videos directly from multimodal visual language inputs. Adopting an end-to-end perspective, Kling-Omni bridges the functional separation among diverse video generation, editing, and intelligent reasoning tasks, integrating them into a holistic system. Unlike disjointed pipeline approaches, Kling-Omni supports a diverse range of user inputs, including text instructions, reference images, and video contexts, processing them into a unified multimodal representation to deliver cinematic-quality and highly-intelligent video content creation. To support these capabilities, we constructed a comprehensive data system that serves as the foundation for multimodal video creation. The framework is further empowered by efficient large-scale pre-training strategies and infrastructure optimizations for inference. Comprehensive evaluations reveal that Kling-Omni demonstrates exceptional capabilities in in-context generation, reasoning-based editing, and multimodal instruction following. Moving beyond a content creation tool, we believe Kling-Omni is a pivotal advancement toward multimodal world simulators capable of perceiving, reasoning, generating and interacting with the dynamic and complex worlds.
Learning for Dynamic Combinatorial Optimization without Training Data
May 26, 2025We introduce DyCO-GNN, a novel unsupervised learning framework for Dynamic Combinatorial Optimization that requires no training data beyond the problem instance itself. DyCO-GNN leverages structural similarities across time-evolving graph snapshots to accelerate optimization while maintaining solution quality. We evaluate DyCO-GNN on dynamic maximum cut, maximum independent set, and the traveling salesman problem across diverse datasets of varying sizes, demonstrating its superior performance under tight and moderate time budgets. DyCO-GNN consistently outperforms the baseline methods, achieving high-quality solutions up to 3-60x faster, highlighting its practical effectiveness in rapidly evolving resource-constrained settings.
LightSleepNet: Design of a Personalized Portable Sleep Staging System Based on Single-Channel EEG
Jan 24, 2024



This paper proposed LightSleepNet - a light-weight, 1-d Convolutional Neural Network (CNN) based personalized architecture for real-time sleep staging, which can be implemented on various mobile platforms with limited hardware resources. The proposed architecture only requires an input of 30s single-channel EEG signal for the classification. Two residual blocks consisting of group 1-d convolution are used instead of the traditional convolution layers to remove the redundancy in the CNN. Channel shuffles are inserted into each convolution layer to improve the accuracy. In order to avoid over-fitting to the training set, a Global Average Pooling (GAP) layer is used to replace the fully connected layer, which further reduces the total number of the model parameters significantly. A personalized algorithm combining Adaptive Batch Normalization (AdaBN) and gradient re-weighting is proposed for unsupervised domain adaptation. A higher priority is given to examples that are easy to transfer to the new subject, and the algorithm could be personalized for new subjects without re-training. Experimental results show a state-of-the-art overall accuracy of 83.8% with only 45.76 Million Floating-point Operations per Second (MFLOPs) computation and 43.08 K parameters.
* 5 pages, 3 figures, published by IEEE TCAS-II
Multi-Channel Multi-Domain based Knowledge Distillation Algorithm for Sleep Staging with Single-Channel EEG
Jan 07, 2024



This paper proposed a Multi-Channel Multi-Domain (MCMD) based knowledge distillation algorithm for sleep staging using single-channel EEG. Both knowledge from different domains and different channels are learnt in the proposed algorithm, simultaneously. A multi-channel pre-training and single-channel fine-tuning scheme is used in the proposed work. The knowledge from different channels in the source domain is transferred to the single-channel model in the target domain. A pre-trained teacher-student model scheme is used to distill knowledge from the multi-channel teacher model to the single-channel student model combining with output transfer and intermediate feature transfer in the target domain. The proposed algorithm achieves a state-of-the-art single-channel sleep staging accuracy of 86.5%, with only 0.6% deterioration from the state-of-the-art multi-channel model. There is an improvement of 2% compared to the baseline model. The experimental results show that knowledge from multiple domains (different datasets) and multiple channels (e.g. EMG, EOG) could be transferred to single-channel sleep staging.
* 5 pages, 2 figures, published by IEEE TCAS-II
KwaiYiiMath: Technical Report
Oct 19, 2023



Recent advancements in large language models (LLMs) have demonstrated remarkable abilities in handling a variety of natural language processing (NLP) downstream tasks, even on mathematical tasks requiring multi-step reasoning. In this report, we introduce the KwaiYiiMath which enhances the mathematical reasoning abilities of KwaiYiiBase1, by applying Supervised Fine-Tuning (SFT) and Reinforced Learning from Human Feedback (RLHF), including on both English and Chinese mathematical tasks. Meanwhile, we also constructed a small-scale Chinese primary school mathematics test set (named KMath), consisting of 188 examples to evaluate the correctness of the problem-solving process generated by the models. Empirical studies demonstrate that KwaiYiiMath can achieve state-of-the-art (SOTA) performance on GSM8k, CMath, and KMath compared with the similar size models, respectively.
Social Bias Meets Data Bias: The Impacts of Labeling and Measurement Errors on Fairness Criteria
May 31, 2022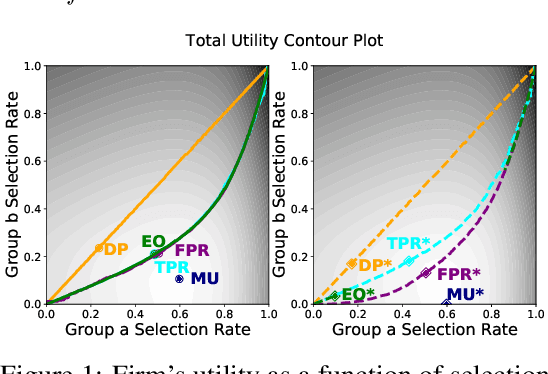
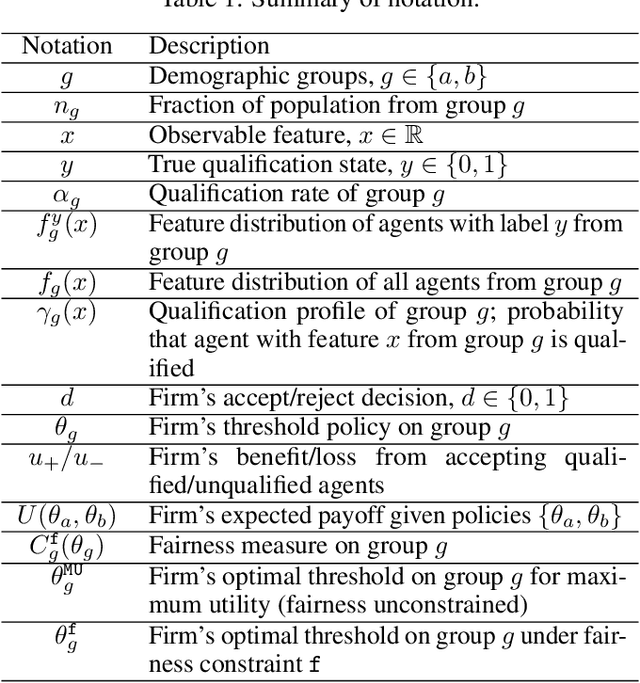
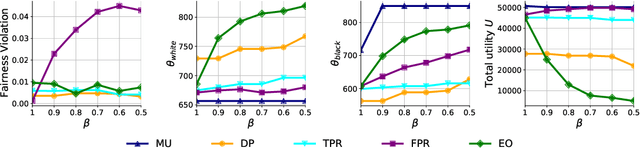
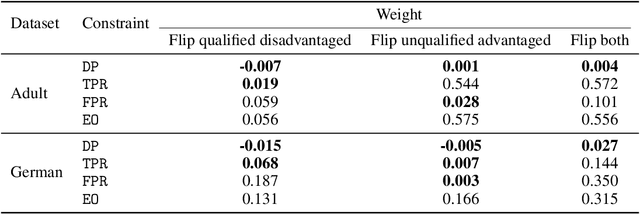
Although many fairness criteria have been proposed to ensure that machine learning algorithms do not exhibit or amplify our existing social biases, these algorithms are trained on datasets that can themselves be statistically biased. In this paper, we investigate the robustness of a number of existing (demographic) fairness criteria when the algorithm is trained on biased data. We consider two forms of dataset bias: errors by prior decision makers in the labeling process, and errors in measurement of the features of disadvantaged individuals. We analytically show that some constraints (such as Demographic Parity) can remain robust when facing certain statistical biases, while others (such as Equalized Odds) are significantly violated if trained on biased data. We also analyze the sensitivity of these criteria and the decision maker's utility to biases. We provide numerical experiments based on three real-world datasets (the FICO, Adult, and German credit score datasets) supporting our analytical findings. Our findings present an additional guideline for choosing among existing fairness criteria, or for proposing new criteria, when available datasets may be biased.
Persia: An Open, Hybrid System Scaling Deep Learning-based Recommenders up to 100 Trillion Parameters
Nov 23, 2021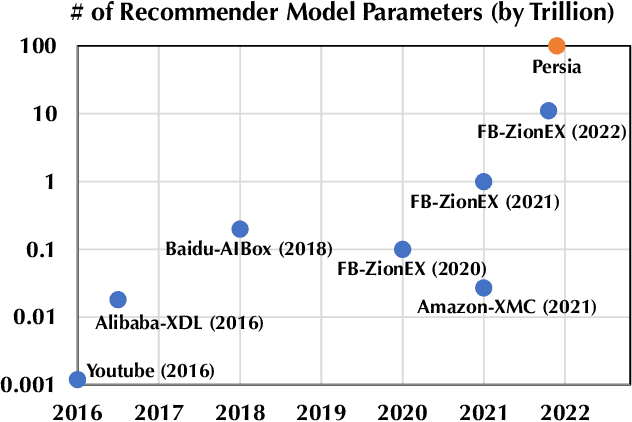
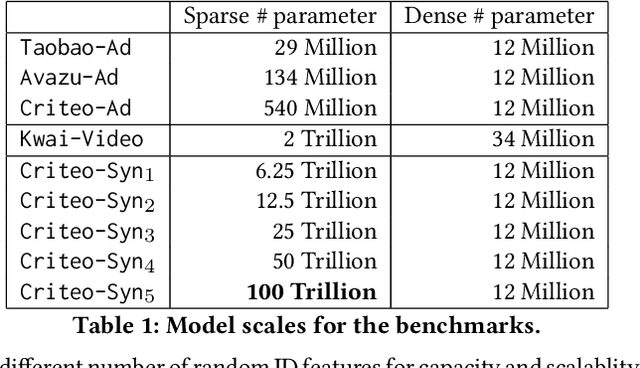
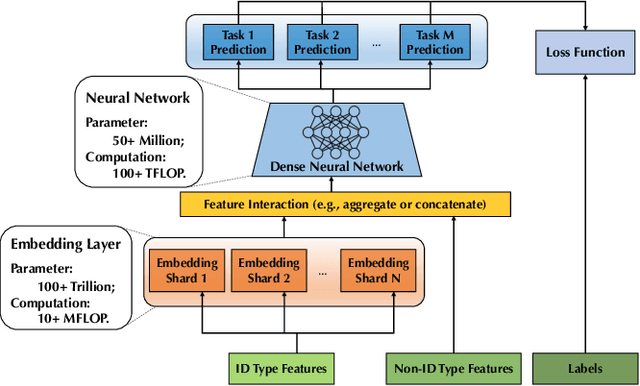
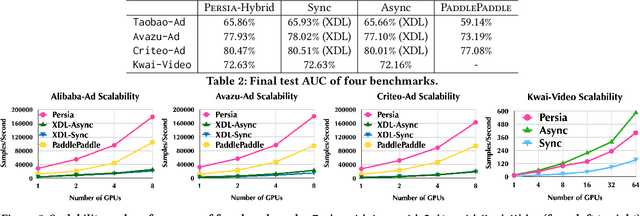
Deep learning based models have dominated the current landscape of production recommender systems. Furthermore, recent years have witnessed an exponential growth of the model scale--from Google's 2016 model with 1 billion parameters to the latest Facebook's model with 12 trillion parameters. Significant quality boost has come with each jump of the model capacity, which makes us believe the era of 100 trillion parameters is around the corner. However, the training of such models is challenging even within industrial scale data centers. This difficulty is inherited from the staggering heterogeneity of the training computation--the model's embedding layer could include more than 99.99% of the total model size, which is extremely memory-intensive; while the rest neural network is increasingly computation-intensive. To support the training of such huge models, an efficient distributed training system is in urgent need. In this paper, we resolve this challenge by careful co-design of both the optimization algorithm and the distributed system architecture. Specifically, in order to ensure both the training efficiency and the training accuracy, we design a novel hybrid training algorithm, where the embedding layer and the dense neural network are handled by different synchronization mechanisms; then we build a system called Persia (short for parallel recommendation training system with hybrid acceleration) to support this hybrid training algorithm. Both theoretical demonstration and empirical study up to 100 trillion parameters have conducted to justified the system design and implementation of Persia. We make Persia publicly available (at https://github.com/PersiaML/Persia) so that anyone would be able to easily train a recommender model at the scale of 100 trillion parameters.