 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLing and Ring 2.6 Technical Report: Efficient and Instant Agentic Intelligence at Trillion-Parameter Scale
Jun 13, 2026Efficient and scalable agentic intelligence requires models that can deliver both low-latency responses and strong reasoning capabilities while remaining practical to train, serve, and deploy. In this report, we present Ling-2.6 and Ring-2.6, a family of models designed to address this challenge at scale. Ling-2.6 is optimized for instant response generation and high capability per output token, whereas Ring-2.6 is tailored for deeper reasoning and more advanced agentic workflows. Instead of training from scratch, we upgrade the Ling-2.0 base model through architectural migration pre-training and large-scale post-training. This upgrade is guided by a unified co-design of model architecture, optimization objectives, serving systems, and agent training environments, enabling improvements in both model capability and deployment efficiency. At the architectural level, we introduce a hybrid linear attention design that integrates Lightning Attention with MLA, improving the efficiency of long-context training and decoding. To further enhance token efficiency, we optimize capability per output token through Evolutionary Chain-of-Thought, Linguistic Unit Policy Optimization, bidirectional preference alignment, and shortest-correct-response distillation. For agentic capabilities, we propose KPop, a reinforcement learning framework designed to support stable training of Ring-2.6-1T on large-scale environment-grounded data. KPop improves training efficiency through asynchronous scheduling across coding, search, tool use, and workflow execution, enabling scalable learning from complex agent-environment interactions. Together, Ling-2.6 and Ring-2.6 provide a practical pathway toward efficient, scalable, and open agentic systems. We open-source all checkpoints in the 2.6 family to support further research and development in practical agentic intelligence.
From Agent Traces to Trust: Evidence Tracing and Execution Provenance in LLM Agents
Jun 03, 2026Large language model (LLM)-based agents increasingly solve complex tasks by interacting with external tools, retrieval systems, memory modules, environments, and other agents. These capabilities expand agent autonomy, but also make agent behavior harder to verify, debug, and audit. Final-answer accuracy alone cannot explain how an output was produced, which evidence supported each claim, whether tool calls were justified, how memory influenced later decisions, or where execution failures originated. Evidence tracing and execution provenance address this gap by modeling how retrieved evidence, tool outputs, memory items, environment observations, intermediate claims, actions, and final answers are connected throughout agent execution. This survey provides a systematic review and conceptual framework for evidence tracing and execution provenance in LLM agents. We organize related work around a unified provenance perspective that connects retrieval grounding, claim support, tool-use safety, memory lineage, observability, debugging, audit, and recovery. We introduce a taxonomy covering trace sources, evidence and execution units, provenance relations, tracing granularity and timing, representation forms, and trust functions. We review key methodological directions, including provenance representation, evidence attribution, tool-use provenance, runtime guardrails, provenance-bearing memory, trace-based observability, and failure diagnosis. We also map existing benchmarks, datasets, and evaluation metrics to provenance-related capabilities, and discuss how evaluation can move from final-answer correctness toward process-level accountability. Finally, we outline open challenges, including unified trace schemas, claim-level and semantic provenance, provenance-aware safety mechanisms, realistic execution-trace benchmarks, recovery-oriented evaluation, and privacy-aware audit infrastructure.
Sheet as Token: A Graph-Enhanced Representation for Multi-Sheet Spreadsheet Understanding
May 07, 2026Workbook-scale spreadsheet understanding is increasingly important for language-model-based data analysis agents, but remains challenging because relevant information is often distributed across multiple sheets with heterogeneous schemas, layouts, and implicit relationships. Existing retrieval-augmented approaches typically decompose spreadsheets into rows, columns, or blocks to improve scalability; however, such chunk-centric representations can fragment worksheets into isolated text spans and weaken global sheet-level semantics. We propose Sheet as Token, a graph-enhanced framework that treats each worksheet as a unified semantic unit for multi-sheet spreadsheet retrieval. Our method extracts schema-aware records from sheet names, column headers, representative values, and layout features, and encodes each worksheet into a compact dense token. Given a natural-language query, a Graph Retriever constructs a query-specific candidate graph over sheet tokens using semantic, query-conditioned, schema-consistency, and shape-compatibility relations, and composes these channels through a multi-stage graph transformer to retrieve supporting sheet sets. Experiments on a constructed multi-sheet spreadsheet corpus show that sheet-level tokenization learns stable representations, and that graph-enhanced cross-sheet reasoning improves listwise retrieval over a shallow graph baseline with limited additional graph-side computation. These results suggest that sheet-level tokenization is a promising abstraction for scalable multi-sheet spreadsheet understanding.
SEARCH-R: Structured Entity-Aware Retrieval with Chain-of-Reasoning Navigator for Multi-hop Question Answering
Apr 27, 2026Multi-hop Question Answering (MHQA) aims to answer questions that require multi-step reasoning. It presents two key challenges: generating correct reasoning paths in response to the complex user queries, and accurately retrieving essential knowledge in the face of potential limitations in large language models (LLMs). Existing approaches primarily rely on prompt-based methods to generate reasoning paths, which are further combined with traditional sparse or dense retrieval to produce the final answer. However, the generation of reasoning paths commonly lacks effective control over the generative process, thus leading the reasoning astray. Meanwhile, the retrieval methods over-rely on knowledge matching or similarity scores rather than evaluating the practical utility of the information, resulting in retrieving homogeneous or non-useful information. Therefore, we propose a Structured Entity-Aware Retrieval with Chain-of-Reasoning Navigator framework named SEARCH-R. Specifically, SEARCH-R trains an end-to-end reasoning path navigator, which is able to provide a powerful sub-question decomposer by fine-tuning the Llama3.1-8B model. Moreover, a novel dependency tree-based retrieval is designed to evaluate the informational contribution of the document quantitatively. Extensive experiments on three challenging multi-hop datasets validate the effectiveness of the proposed framework. The code and dataset are available at: https://github.com/Applied-Machine-Learning-Lab/ACL2026_SEARCH-R.
Cognitive Chunking for Soft Prompts: Accelerating Compressor Learning via Block-wise Causal Masking
Feb 15, 2026Providing extensive context via prompting is vital for leveraging the capabilities of Large Language Models (LLMs). However, lengthy contexts significantly increase inference latency, as the computational cost of self-attention grows quadratically with sequence length. To mitigate this issue, context compression-particularly soft prompt compressio-has emerged as a widely studied solution, which converts long contexts into shorter memory embeddings via a trained compressor. Existing methods typically compress the entire context indiscriminately into a set of memory tokens, requiring the compressor to capture global dependencies and necessitating extensive pre-training data to learn effective patterns. Inspired by the chunking mechanism in human working memory and empirical observations of the spatial specialization of memory embeddings relative to original tokens, we propose Parallelized Iterative Compression (PIC). By simply modifying the Transformer's attention mask, PIC explicitly restricts the receptive field of memory tokens to sequential local chunks, thereby lowering the difficulty of compressor training. Experiments across multiple downstream tasks demonstrate that PIC consistently outperforms competitive baselines, with superiority being particularly pronounced in high compression scenarios (e.g., achieving relative improvements of 29.8\% in F1 score and 40.7\% in EM score on QA tasks at the $64\times$ compression ratio). Furthermore, PIC significantly expedites the training process. Specifically, when training the 16$\times$ compressor, it surpasses the peak performance of the competitive baseline while effectively reducing the training time by approximately 40\%.
Beyond Parameter Finetuning: Test-Time Representation Refinement for Node Classification
Jan 29, 2026Graph Neural Networks frequently exhibit significant performance degradation in the out-of-distribution test scenario. While test-time training (TTT) offers a promising solution, existing Parameter Finetuning (PaFT) paradigm suffer from catastrophic forgetting, hindering their real-world applicability. We propose TTReFT, a novel Test-Time Representation FineTuning framework that transitions the adaptation target from model parameters to latent representations. Specifically, TTReFT achieves this through three key innovations: (1) uncertainty-guided node selection for specific interventions, (2) low-rank representation interventions that preserve pre-trained knowledge, and (3) an intervention-aware masked autoencoder that dynamically adjust masking strategy to accommodate the node selection scheme. Theoretically, we establish guarantees for TTReFT in OOD settings. Empirically, extensive experiments across five benchmark datasets demonstrate that TTReFT achieves consistent and superior performance. Our work establishes representation finetuning as a new paradigm for graph TTT, offering both theoretical grounding and immediate practical utility for real-world deployment.
Renormalization Group Guided Tensor Network Structure Search
Dec 31, 2025Tensor network structure search (TN-SS) aims to automatically discover optimal network topologies and rank configurations for efficient tensor decomposition in high-dimensional data representation. Despite recent advances, existing TN-SS methods face significant limitations in computational tractability, structure adaptivity, and optimization robustness across diverse tensor characteristics. They struggle with three key challenges: single-scale optimization missing multi-scale structures, discrete search spaces hindering smooth structure evolution, and separated structure-parameter optimization causing computational inefficiency. We propose RGTN (Renormalization Group guided Tensor Network search), a physics-inspired framework transforming TN-SS via multi-scale renormalization group flows. Unlike fixed-scale discrete search methods, RGTN uses dynamic scale-transformation for continuous structure evolution across resolutions. Its core innovation includes learnable edge gates for optimization-stage topology modification and intelligent proposals based on physical quantities like node tension measuring local stress and edge information flow quantifying connectivity importance. Starting from low-complexity coarse scales and refining to finer ones, RGTN finds compact structures while escaping local minima via scale-induced perturbations. Extensive experiments on light field data, high-order synthetic tensors, and video completion tasks show RGTN achieves state-of-the-art compression ratios and runs 4-600$\times$ faster than existing methods, validating the effectiveness of our physics-inspired approach.
BlossomRec: Block-level Fused Sparse Attention Mechanism for Sequential Recommendations
Dec 15, 2025Transformer structures have been widely used in sequential recommender systems (SRS). However, as user interaction histories increase, computational time and memory requirements also grow. This is mainly caused by the standard attention mechanism. Although there exist many methods employing efficient attention and SSM-based models, these approaches struggle to effectively model long sequences and may exhibit unstable performance on short sequences. To address these challenges, we design a sparse attention mechanism, BlossomRec, which models both long-term and short-term user interests through attention computation to achieve stable performance across sequences of varying lengths. Specifically, we categorize user interests in recommendation systems into long-term and short-term interests, and compute them using two distinct sparse attention patterns, with the results combined through a learnable gated output. Theoretically, it significantly reduces the number of interactions participating in attention computation. Extensive experiments on four public datasets demonstrate that BlossomRec, when integrated with state-of-the-art Transformer-based models, achieves comparable or even superior performance while significantly reducing memory usage, providing strong evidence of BlossomRec's efficiency and effectiveness.The code is available at https://github.com/ronineume/BlossomRec.
Investigating Data Pruning for Pretraining Biological Foundation Models at Scale
Dec 15, 2025Biological foundation models (BioFMs), pretrained on large-scale biological sequences, have recently shown strong potential in providing meaningful representations for diverse downstream bioinformatics tasks. However, such models often rely on millions to billions of training sequences and billions of parameters, resulting in prohibitive computational costs and significant barriers to reproducibility and accessibility, particularly for academic labs. To address these challenges, we investigate the feasibility of data pruning for BioFM pretraining and propose a post-hoc influence-guided data pruning framework tailored to biological domains. Our approach introduces a subset-based self-influence formulation that enables efficient estimation of sample importance at low computational cost, and builds upon it two simple yet effective selection strategies, namely Top-k Influence (Top I) and Coverage-Centric Influence (CCI). We empirically validate our method on two representative BioFMs, RNA-FM and ESM-C. For RNA, our framework consistently outperforms random selection baselines under an extreme pruning rate of over 99 percent, demonstrating its effectiveness. Furthermore, we show the generalizability of our framework on protein-related tasks using ESM-C. In particular, our coreset even outperforms random subsets that are ten times larger in both RNA and protein settings, revealing substantial redundancy in biological sequence datasets. These findings underscore the potential of influence-guided data pruning to substantially reduce the computational cost of BioFM pretraining, paving the way for more efficient, accessible, and sustainable biological AI research.
Latent Policy Steering with Embodiment-Agnostic Pretrained World Models
Jul 17, 2025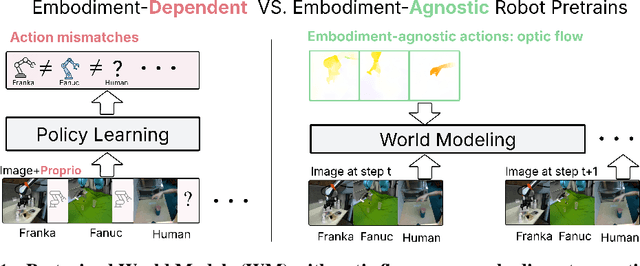
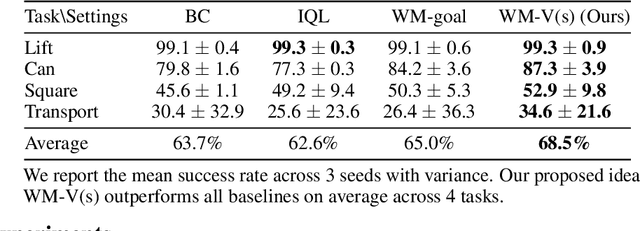

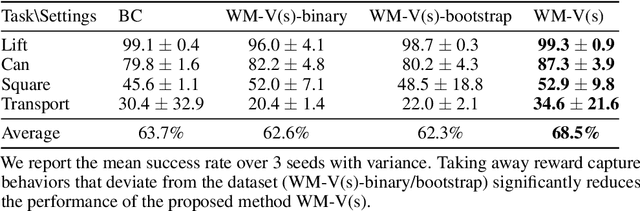
Learning visuomotor policies via imitation has proven effective across a wide range of robotic domains. However, the performance of these policies is heavily dependent on the number of training demonstrations, which requires expensive data collection in the real world. In this work, we aim to reduce data collection efforts when learning visuomotor robot policies by leveraging existing or cost-effective data from a wide range of embodiments, such as public robot datasets and the datasets of humans playing with objects (human data from play). Our approach leverages two key insights. First, we use optic flow as an embodiment-agnostic action representation to train a World Model (WM) across multi-embodiment datasets, and finetune it on a small amount of robot data from the target embodiment. Second, we develop a method, Latent Policy Steering (LPS), to improve the output of a behavior-cloned policy by searching in the latent space of the WM for better action sequences. In real world experiments, we observe significant improvements in the performance of policies trained with a small amount of data (over 50% relative improvement with 30 demonstrations and over 20% relative improvement with 50 demonstrations) by combining the policy with a WM pretrained on two thousand episodes sampled from the existing Open X-embodiment dataset across different robots or a cost-effective human dataset from play.