 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Visual Text Grounding of Multimodal Large Language Model
Apr 07, 2025

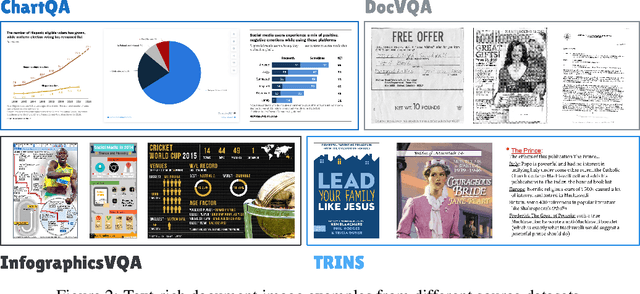

Despite the existing evolution of Multimodal Large Language Models (MLLMs), a non-neglectable limitation remains in their struggle with visual text grounding, especially in text-rich images of documents. Document images, such as scanned forms and infographics, highlight critical challenges due to their complex layouts and textual content. However, current benchmarks do not fully address these challenges, as they mostly focus on visual grounding on natural images, rather than text-rich document images. Thus, to bridge this gap, we introduce TRIG, a novel task with a newly designed instruction dataset for benchmarking and improving the Text-Rich Image Grounding capabilities of MLLMs in document question-answering. Specifically, we propose an OCR-LLM-human interaction pipeline to create 800 manually annotated question-answer pairs as a benchmark and a large-scale training set of 90$ synthetic data based on four diverse datasets. A comprehensive evaluation of various MLLMs on our proposed benchmark exposes substantial limitations in their grounding capability on text-rich images. In addition, we propose two simple and effective TRIG methods based on general instruction tuning and plug-and-play efficient embedding, respectively. By finetuning MLLMs on our synthetic dataset, they promisingly improve spatial reasoning and grounding capabilities.
QuartDepth: Post-Training Quantization for Real-Time Depth Estimation on the Edge
Mar 20, 2025



Monocular Depth Estimation (MDE) has emerged as a pivotal task in computer vision, supporting numerous real-world applications. However, deploying accurate depth estimation models on resource-limited edge devices, especially Application-Specific Integrated Circuits (ASICs), is challenging due to the high computational and memory demands. Recent advancements in foundational depth estimation deliver impressive results but further amplify the difficulty of deployment on ASICs. To address this, we propose QuartDepth which adopts post-training quantization to quantize MDE models with hardware accelerations for ASICs. Our approach involves quantizing both weights and activations to 4-bit precision, reducing the model size and computation cost. To mitigate the performance degradation, we introduce activation polishing and compensation algorithm applied before and after activation quantization, as well as a weight reconstruction method for minimizing errors in weight quantization. Furthermore, we design a flexible and programmable hardware accelerator by supporting kernel fusion and customized instruction programmability, enhancing throughput and efficiency. Experimental results demonstrate that our framework achieves competitive accuracy while enabling fast inference and higher energy efficiency on ASICs, bridging the gap between high-performance depth estimation and practical edge-device applicability. Code: https://github.com/shawnricecake/quart-depth
Robust Latent Matters: Boosting Image Generation with Sampling Error
Mar 11, 2025



Recent image generation schemes typically capture image distribution in a pre-constructed latent space relying on a frozen image tokenizer. Though the performance of tokenizer plays an essential role to the successful generation, its current evaluation metrics (e.g. rFID) fail to precisely assess the tokenizer and correlate its performance to the generation quality (e.g. gFID). In this paper, we comprehensively analyze the reason for the discrepancy of reconstruction and generation qualities in a discrete latent space, and, from which, we propose a novel plug-and-play tokenizer training scheme to facilitate latent space construction. Specifically, a latent perturbation approach is proposed to simulate sampling noises, i.e., the unexpected tokens sampled, from the generative process. With the latent perturbation, we further propose (1) a novel tokenizer evaluation metric, i.e., pFID, which successfully correlates the tokenizer performance to generation quality and (2) a plug-and-play tokenizer training scheme, which significantly enhances the robustness of tokenizer thus boosting the generation quality and convergence speed. Extensive benchmarking are conducted with 11 advanced discrete image tokenizers with 2 autoregressive generation models to validate our approach. The tokenizer trained with our proposed latent perturbation achieve a notable 1.60 gFID with classifier-free guidance (CFG) and 3.45 gFID without CFG with a $\sim$400M generator. Code: https://github.com/lxa9867/ImageFolder.
METAL: A Multi-Agent Framework for Chart Generation with Test-Time Scaling
Feb 24, 2025



Chart generation aims to generate code to produce charts satisfying the desired visual properties, e.g., texts, layout, color, and type. It has great potential to empower the automatic professional report generation in financial analysis, research presentation, education, and healthcare. In this work, we build a vision-language model (VLM) based multi-agent framework for effective automatic chart generation. Generating high-quality charts requires both strong visual design skills and precise coding capabilities that embed the desired visual properties into code. Such a complex multi-modal reasoning process is difficult for direct prompting of VLMs. To resolve these challenges, we propose METAL, a multi-agent framework that decomposes the task of chart generation into the iterative collaboration among specialized agents. METAL achieves 5.2% improvement in accuracy over the current best result in the chart generation task. The METAL framework exhibits the phenomenon of test-time scaling: its performance increases monotonically as the logarithmic computational budget grows from 512 to 8192 tokens. In addition, we find that separating different modalities during the critique process of METAL boosts the self-correction capability of VLMs in the multimodal context.
From Selection to Generation: A Survey of LLM-based Active Learning
Feb 17, 2025Active Learning (AL) has been a powerful paradigm for improving model efficiency and performance by selecting the most informative data points for labeling and training. In recent active learning frameworks, Large Language Models (LLMs) have been employed not only for selection but also for generating entirely new data instances and providing more cost-effective annotations. Motivated by the increasing importance of high-quality data and efficient model training in the era of LLMs, we present a comprehensive survey on LLM-based Active Learning. We introduce an intuitive taxonomy that categorizes these techniques and discuss the transformative roles LLMs can play in the active learning loop. We further examine the impact of AL on LLM learning paradigms and its applications across various domains. Finally, we identify open challenges and propose future research directions. This survey aims to serve as an up-to-date resource for researchers and practitioners seeking to gain an intuitive understanding of LLM-based AL techniques and deploy them to new applications.
Efficient Reasoning with Hidden Thinking
Jan 31, 2025



Chain-of-Thought (CoT) reasoning has become a powerful framework for improving complex problem-solving capabilities in Multimodal Large Language Models (MLLMs). However, the verbose nature of textual reasoning introduces significant inefficiencies. In this work, we propose $\textbf{Heima}$ (as hidden llama), an efficient reasoning framework that leverages reasoning CoTs at hidden latent space. We design the Heima Encoder to condense each intermediate CoT into a compact, higher-level hidden representation using a single thinking token, effectively minimizing verbosity and reducing the overall number of tokens required during the reasoning process. Meanwhile, we design corresponding Heima Decoder with traditional Large Language Models (LLMs) to adaptively interpret the hidden representations into variable-length textual sequence, reconstructing reasoning processes that closely resemble the original CoTs. Experimental results across diverse reasoning MLLM benchmarks demonstrate that Heima model achieves higher generation efficiency while maintaining or even better zero-shot task accuracy. Moreover, the effective reconstruction of multimodal reasoning processes with Heima Decoder validates both the robustness and interpretability of our approach.
MegaSynth: Scaling Up 3D Scene Reconstruction with Synthesized Data
Dec 18, 2024



We propose scaling up 3D scene reconstruction by training with synthesized data. At the core of our work is MegaSynth, a procedurally generated 3D dataset comprising 700K scenes - over 50 times larger than the prior real dataset DL3DV - dramatically scaling the training data. To enable scalable data generation, our key idea is eliminating semantic information, removing the need to model complex semantic priors such as object affordances and scene composition. Instead, we model scenes with basic spatial structures and geometry primitives, offering scalability. Besides, we control data complexity to facilitate training while loosely aligning it with real-world data distribution to benefit real-world generalization. We explore training LRMs with both MegaSynth and available real data. Experiment results show that joint training or pre-training with MegaSynth improves reconstruction quality by 1.2 to 1.8 dB PSNR across diverse image domains. Moreover, models trained solely on MegaSynth perform comparably to those trained on real data, underscoring the low-level nature of 3D reconstruction. Additionally, we provide an in-depth analysis of MegaSynth's properties for enhancing model capability, training stability, and generalization.
LazyDiT: Lazy Learning for the Acceleration of Diffusion Transformers
Dec 17, 2024Diffusion Transformers have emerged as the preeminent models for a wide array of generative tasks, demonstrating superior performance and efficacy across various applications. The promising results come at the cost of slow inference, as each denoising step requires running the whole transformer model with a large amount of parameters. In this paper, we show that performing the full computation of the model at each diffusion step is unnecessary, as some computations can be skipped by lazily reusing the results of previous steps. Furthermore, we show that the lower bound of similarity between outputs at consecutive steps is notably high, and this similarity can be linearly approximated using the inputs. To verify our demonstrations, we propose the \textbf{LazyDiT}, a lazy learning framework that efficiently leverages cached results from earlier steps to skip redundant computations. Specifically, we incorporate lazy learning layers into the model, effectively trained to maximize laziness, enabling dynamic skipping of redundant computations. Experimental results show that LazyDiT outperforms the DDIM sampler across multiple diffusion transformer models at various resolutions. Furthermore, we implement our method on mobile devices, achieving better performance than DDIM with similar latency.
Numerical Pruning for Efficient Autoregressive Models
Dec 17, 2024



Transformers have emerged as the leading architecture in deep learning, proving to be versatile and highly effective across diverse domains beyond language and image processing. However, their impressive performance often incurs high computational costs due to their substantial model size. This paper focuses on compressing decoder-only transformer-based autoregressive models through structural weight pruning to improve the model efficiency while preserving performance for both language and image generation tasks. Specifically, we propose a training-free pruning method that calculates a numerical score with Newton's method for the Attention and MLP modules, respectively. Besides, we further propose another compensation algorithm to recover the pruned model for better performance. To verify the effectiveness of our method, we provide both theoretical support and extensive experiments. Our experiments show that our method achieves state-of-the-art performance with reduced memory usage and faster generation speeds on GPUs.
SUGAR: Subject-Driven Video Customization in a Zero-Shot Manner
Dec 13, 2024We present SUGAR, a zero-shot method for subject-driven video customization. Given an input image, SUGAR is capable of generating videos for the subject contained in the image and aligning the generation with arbitrary visual attributes such as style and motion specified by user-input text. Unlike previous methods, which require test-time fine-tuning or fail to generate text-aligned videos, SUGAR achieves superior results without the need for extra cost at test-time. To enable zero-shot capability, we introduce a scalable pipeline to construct synthetic dataset which is specifically designed for subject-driven customization, leading to 2.5 millions of image-video-text triplets. Additionally, we propose several methods to enhance our model, including special attention designs, improved training strategies, and a refined sampling algorithm. Extensive experiments are conducted. Compared to previous methods, SUGAR achieves state-of-the-art results in identity preservation, video dynamics, and video-text alignment for subject-driven video customization, demonstrating the effectiveness of our proposed method.