 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinear Image Generation by Synthesizing Exposure Brackets
Apr 22, 2026The life of a photo begins with photons striking the sensor, whose signals are passed through a sophisticated image signal processing (ISP) pipeline to produce a display-referred image. However, such images are no longer faithful to the incident light, being compressed in dynamic range and stylized by subjective preferences. In contrast, RAW images record direct sensor signals before non-linear tone mapping. After camera response curve correction and demosaicing, they can be converted into linear images, which are scene-referred representations that directly reflect true irradiance and are invariant to sensor-specific factors. Since image sensors have better dynamic range and bit depth, linear images contain richer information than display-referred ones, leaving users more room for editing during post-processing. Despite this advantage, current generative models mainly synthesize display-referred images, which inherently limits downstream editing. In this paper, we address the task of text-to-linear-image generation: synthesizing a high-quality, scene-referred linear image that preserves full dynamic range, conditioned on a text prompt, for professional post-processing. Generating linear images is challenging, as pre-trained VAEs in latent diffusion models struggle to simultaneously preserve extreme highlights and shadows due to the higher dynamic range and bit depth. To this end, we represent a linear image as a sequence of exposure brackets, each capturing a specific portion of the dynamic range, and propose a DiT-based flow-matching architecture for text-conditioned exposure bracket generation. We further demonstrate downstream applications including text-guided linear image editing and structure-conditioned generation via ControlNet.
SemLayer: Semantic-aware Generative Segmentation and Layer Construction for Abstract Icons
Mar 25, 2026Graphic icons are a cornerstone of modern design workflows, yet they are often distributed as flattened single-path or compound-path graphics, where the original semantic layering is lost. This absence of semantic decomposition hinders downstream tasks such as editing, restyling, and animation. We formalize this problem as semantic layer construction for flattened vector art and introduce SemLayer, a visual generation empowered pipeline that restores editable layered structures. Given an abstract icon, SemLayer first generates a chromatically differentiated representation in which distinct semantic components become visually separable. To recover the complete geometry of each part, including occluded regions, we then perform a semantic completion step that reconstructs coherent object-level shapes. Finally, the recovered parts are assembled into a layered vector representation with inferred occlusion relationships. Extensive qualitative comparisons and quantitative evaluations demonstrate the effectiveness of SemLayer, enabling editing workflows previously inapplicable to flattened vector graphics and establishing semantic layer reconstruction as a practical and valuable task. Project page: https://xxuhaiyang.github.io/SemLayer/
Tri-Prompting: Video Diffusion with Unified Control over Scene, Subject, and Motion
Mar 16, 2026Recent video diffusion models have made remarkable strides in visual quality, yet precise, fine-grained control remains a key bottleneck that limits practical customizability for content creation. For AI video creators, three forms of control are crucial: (i) scene composition, (ii) multi-view consistent subject customization, and (iii) camera-pose or object-motion adjustment. Existing methods typically handle these dimensions in isolation, with limited support for multi-view subject synthesis and identity preservation under arbitrary pose changes. This lack of a unified architecture makes it difficult to support versatile, jointly controllable video. We introduce Tri-Prompting, a unified framework and two-stage training paradigm that integrates scene composition, multi-view subject consistency, and motion control. Our approach leverages a dual-condition motion module driven by 3D tracking points for background scenes and downsampled RGB cues for foreground subjects. To ensure a balance between controllability and visual realism, we further propose an inference ControlNet scale schedule. Tri-Prompting supports novel workflows, including 3D-aware subject insertion into any scenes and manipulation of existing subjects in an image. Experimental results demonstrate that Tri-Prompting significantly outperforms specialized baselines such as Phantom and DaS in multi-view subject identity, 3D consistency, and motion accuracy.
DuetSVG: Unified Multimodal SVG Generation with Internal Visual Guidance
Dec 11, 2025Recent vision-language model (VLM)-based approaches have achieved impressive results on SVG generation. However, because they generate only text and lack visual signals during decoding, they often struggle with complex semantics and fail to produce visually appealing or geometrically coherent SVGs. We introduce DuetSVG, a unified multimodal model that jointly generates image tokens and corresponding SVG tokens in an end-to-end manner. DuetSVG is trained on both image and SVG datasets. At inference, we apply a novel test-time scaling strategy that leverages the model's native visual predictions as guidance to improve SVG decoding quality. Extensive experiments show that our method outperforms existing methods, producing visually faithful, semantically aligned, and syntactically clean SVGs across a wide range of applications.
Learning an Image Editing Model without Image Editing Pairs
Oct 16, 2025



Recent image editing models have achieved impressive results while following natural language editing instructions, but they rely on supervised fine-tuning with large datasets of input-target pairs. This is a critical bottleneck, as such naturally occurring pairs are hard to curate at scale. Current workarounds use synthetic training pairs that leverage the zero-shot capabilities of existing models. However, this can propagate and magnify the artifacts of the pretrained model into the final trained model. In this work, we present a new training paradigm that eliminates the need for paired data entirely. Our approach directly optimizes a few-step diffusion model by unrolling it during training and leveraging feedback from vision-language models (VLMs). For each input and editing instruction, the VLM evaluates if an edit follows the instruction and preserves unchanged content, providing direct gradients for end-to-end optimization. To ensure visual fidelity, we incorporate distribution matching loss (DMD), which constrains generated images to remain within the image manifold learned by pretrained models. We evaluate our method on standard benchmarks and include an extensive ablation study. Without any paired data, our method performs on par with various image editing diffusion models trained on extensive supervised paired data, under the few-step setting. Given the same VLM as the reward model, we also outperform RL-based techniques like Flow-GRPO.
Style Customization of Text-to-Vector Generation with Image Diffusion Priors
May 15, 2025



Scalable Vector Graphics (SVGs) are highly favored by designers due to their resolution independence and well-organized layer structure. Although existing text-to-vector (T2V) generation methods can create SVGs from text prompts, they often overlook an important need in practical applications: style customization, which is vital for producing a collection of vector graphics with consistent visual appearance and coherent aesthetics. Extending existing T2V methods for style customization poses certain challenges. Optimization-based T2V models can utilize the priors of text-to-image (T2I) models for customization, but struggle with maintaining structural regularity. On the other hand, feed-forward T2V models can ensure structural regularity, yet they encounter difficulties in disentangling content and style due to limited SVG training data. To address these challenges, we propose a novel two-stage style customization pipeline for SVG generation, making use of the advantages of both feed-forward T2V models and T2I image priors. In the first stage, we train a T2V diffusion model with a path-level representation to ensure the structural regularity of SVGs while preserving diverse expressive capabilities. In the second stage, we customize the T2V diffusion model to different styles by distilling customized T2I models. By integrating these techniques, our pipeline can generate high-quality and diverse SVGs in custom styles based on text prompts in an efficient feed-forward manner. The effectiveness of our method has been validated through extensive experiments. The project page is https://customsvg.github.io.
3D-Fixup: Advancing Photo Editing with 3D Priors
May 15, 2025
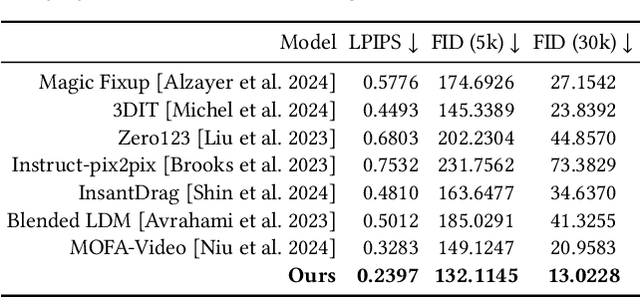


Despite significant advances in modeling image priors via diffusion models, 3D-aware image editing remains challenging, in part because the object is only specified via a single image. To tackle this challenge, we propose 3D-Fixup, a new framework for editing 2D images guided by learned 3D priors. The framework supports difficult editing situations such as object translation and 3D rotation. To achieve this, we leverage a training-based approach that harnesses the generative power of diffusion models. As video data naturally encodes real-world physical dynamics, we turn to video data for generating training data pairs, i.e., a source and a target frame. Rather than relying solely on a single trained model to infer transformations between source and target frames, we incorporate 3D guidance from an Image-to-3D model, which bridges this challenging task by explicitly projecting 2D information into 3D space. We design a data generation pipeline to ensure high-quality 3D guidance throughout training. Results show that by integrating these 3D priors, 3D-Fixup effectively supports complex, identity coherent 3D-aware edits, achieving high-quality results and advancing the application of diffusion models in realistic image manipulation. The code is provided at https://3dfixup.github.io/
From Fragment to One Piece: A Survey on AI-Driven Graphic Design
Mar 24, 2025This survey provides a comprehensive overview of the advancements in Artificial Intelligence in Graphic Design (AIGD), focusing on integrating AI techniques to support design interpretation and enhance the creative process. We categorize the field into two primary directions: perception tasks, which involve understanding and analyzing design elements, and generation tasks, which focus on creating new design elements and layouts. The survey covers various subtasks, including visual element perception and generation, aesthetic and semantic understanding, layout analysis, and generation. We highlight the role of large language models and multimodal approaches in bridging the gap between localized visual features and global design intent. Despite significant progress, challenges remain to understanding human intent, ensuring interpretability, and maintaining control over multilayered compositions. This survey serves as a guide for researchers, providing information on the current state of AIGD and potential future directions\footnote{https://github.com/zhangtianer521/excellent\_Intelligent\_graphic\_design}.
Bézier Splatting for Fast and Differentiable Vector Graphics
Mar 20, 2025



Differentiable vector graphics (VGs) are widely used in image vectorization and vector synthesis, while existing representations are costly to optimize and struggle to achieve high-quality rendering results for high-resolution images. This work introduces a new differentiable VG representation, dubbed B\'ezier splatting, that enables fast yet high-fidelity VG rasterization. B\'ezier splatting samples 2D Gaussians along B\'ezier curves, which naturally provide positional gradients at object boundaries. Thanks to the efficient splatting-based differentiable rasterizer, B\'ezier splatting achieves over 20x and 150x faster per forward and backward rasterization step for open curves compared to DiffVG. Additionally, we introduce an adaptive pruning and densification strategy that dynamically adjusts the spatial distribution of curves to escape local minima, further improving VG quality. Experimental results show that B\'ezier splatting significantly outperforms existing methods with better visual fidelity and 10x faster optimization speed.
Mean-Shift Distillation for Diffusion Mode Seeking
Feb 21, 2025We present mean-shift distillation, a novel diffusion distillation technique that provides a provably good proxy for the gradient of the diffusion output distribution. This is derived directly from mean-shift mode seeking on the distribution, and we show that its extrema are aligned with the modes. We further derive an efficient product distribution sampling procedure to evaluate the gradient. Our method is formulated as a drop-in replacement for score distillation sampling (SDS), requiring neither model retraining nor extensive modification of the sampling procedure. We show that it exhibits superior mode alignment as well as improved convergence in both synthetic and practical setups, yielding higher-fidelity results when applied to both text-to-image and text-to-3D applications with Stable Diffusion.