 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevising Context, Shifting Simulated Stance: Auditing LLM-Based Stance Simulation in Online Discussions
Jun 04, 2026Large language models are increasingly used to simulate social media users and infer how individuals may respond to online discussions. However, it remains unclear whether these simulations reflect precise user-specific beliefs or whether they are highly sensitive to semantically independent changes in conversational contexts. In this work, we study counterfactual context revision as a framework for auditing LLM-based stance simulation. Given an original online conversation, we first infer a target user's stance toward a specific topic. We then apply controlled revision strategies to the conversational context and simulate the user's stance again under the revised context. We compare text-only revision strategies with a multimodal one that incorporates meme-based context and evaluate two main effectiveness metrics, i.e., average directional stance shift and stance transition rate. The results reveal effective and robust stance transitions in both text-only and multimodal strategies across different polarization-preference mechanisms. Our study contributes an evaluation framework for understanding the context sensitivity of LLM-based stance simulation. More broadly, it highlights both the promise and risk of using LLMs to simulate online opinion dynamics.
Probing Outcome-Level Resemblance and Mechanism-Level Alignment in LLM Risk Decisions: Evidence from the St. Petersburg Game
Jun 03, 2026LLMs can appear cautious in risk decision-making tasks, yet cautious-looking outputs do not necessarily indicate alignment with human decision-making mechanisms. We investigate this distinction using the St. Petersburg game as a controlled testbed, a classical paradox in which the expected payoff is infinite, yet humans typically report low, finite willingness to pay. We evaluate 28 LLMs with a structured prompt suite that includes the original game; controlled decision variants that perturb truncation, repeated play, numeric endowment, and occupational identity; a human-perspective prompt that asks models to reason as human decision makers; and paired comparisons between base models and their instruction-tuned counterparts. In the original game, most models generate finite bids, creating the appearance of human-like risk behavior. However, this outcome-level resemblance masks substantial mechanism-level differences. The controlled variants reveal that rather than maintaining human-like behavior seen in the original game, models often shift to conditionally and computationally rational behavior. Human-cue prompting and instruction tuning often lower bids and reduce some visible pathologies, but most mechanism-level response patterns remain largely unchanged. These findings show that behavioral alignment in risk decision-making can be surface-level: LLMs may produce human-like risk decisions without exhibiting human-consistent mechanisms. High-stakes evaluations of LLM decision-making should therefore move beyond outcome similarity and examine whether the alignment is supported by mechanism-level consistency.
Seeing the Poem: Image-Semantic Detection of AI-Generated Modern Chinese Poetry with MLLMs
May 21, 2026Previous detection studies have shown that LLMs cannot be effectively used as detectors, but these studies have not addressed modern Chinese poetry. Moreover, no relevant research has explored the performance of LLMs in detecting modern Chinese poetry. This paper evaluates and enhances the performance of LLMs as detectors for modern Chinese poetry, and proposes an image-semantic guided poetry detection method. Compared with traditional detection approaches, our method innovatively incorporates images that reflect the content of the poetry. Through example-driven approaches, our method effectively integrates information such as meaning, imagery, and feeling from the image, then forms a complementary judgment with the poem text. Experimental results demonstrate that the LLM detectors based on our method outperform baseline detectors based on plain text, and even surpass the best-performing traditional detector, RoBERTa. The Gemini detector using our method achieves a Macro-F1 score of 85.65%, reaching the state-of-the-art level. The performance improvements of different LLM detectors on multiple LLMs-generated data prove the effectiveness of our method.
Assessing Historical Structural Oppression Worldwide via Rule-Guided Prompting of Large Language Models
Sep 18, 2025



Traditional efforts to measure historical structural oppression struggle with cross-national validity due to the unique, locally specified histories of exclusion, colonization, and social status in each country, and often have relied on structured indices that privilege material resources while overlooking lived, identity-based exclusion. We introduce a novel framework for oppression measurement that leverages Large Language Models (LLMs) to generate context-sensitive scores of lived historical disadvantage across diverse geopolitical settings. Using unstructured self-identified ethnicity utterances from a multilingual COVID-19 global study, we design rule-guided prompting strategies that encourage models to produce interpretable, theoretically grounded estimations of oppression. We systematically evaluate these strategies across multiple state-of-the-art LLMs. Our results demonstrate that LLMs, when guided by explicit rules, can capture nuanced forms of identity-based historical oppression within nations. This approach provides a complementary measurement tool that highlights dimensions of systemic exclusion, offering a scalable, cross-cultural lens for understanding how oppression manifests in data-driven research and public health contexts. To support reproducible evaluation, we release an open-sourced benchmark dataset for assessing LLMs on oppression measurement (https://github.com/chattergpt/llm-oppression-benchmark).
Characterizing Bias: Benchmarking Large Language Models in Simplified versus Traditional Chinese
May 28, 2025



While the capabilities of Large Language Models (LLMs) have been studied in both Simplified and Traditional Chinese, it is yet unclear whether LLMs exhibit differential performance when prompted in these two variants of written Chinese. This understanding is critical, as disparities in the quality of LLM responses can perpetuate representational harms by ignoring the different cultural contexts underlying Simplified versus Traditional Chinese, and can exacerbate downstream harms in LLM-facilitated decision-making in domains such as education or hiring. To investigate potential LLM performance disparities, we design two benchmark tasks that reflect real-world scenarios: regional term choice (prompting the LLM to name a described item which is referred to differently in Mainland China and Taiwan), and regional name choice (prompting the LLM to choose who to hire from a list of names in both Simplified and Traditional Chinese). For both tasks, we audit the performance of 11 leading commercial LLM services and open-sourced models -- spanning those primarily trained on English, Simplified Chinese, or Traditional Chinese. Our analyses indicate that biases in LLM responses are dependent on both the task and prompting language: while most LLMs disproportionately favored Simplified Chinese responses in the regional term choice task, they surprisingly favored Traditional Chinese names in the regional name choice task. We find that these disparities may arise from differences in training data representation, written character preferences, and tokenization of Simplified and Traditional Chinese. These findings highlight the need for further analysis of LLM biases; as such, we provide an open-sourced benchmark dataset to foster reproducible evaluations of future LLM behavior across Chinese language variants (https://github.com/brucelyu17/SC-TC-Bench).
SocioVerse: A World Model for Social Simulation Powered by LLM Agents and A Pool of 10 Million Real-World Users
Apr 14, 2025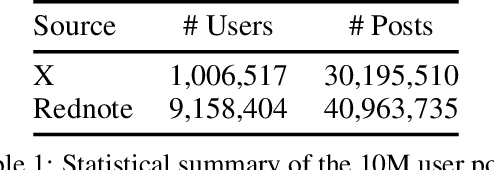
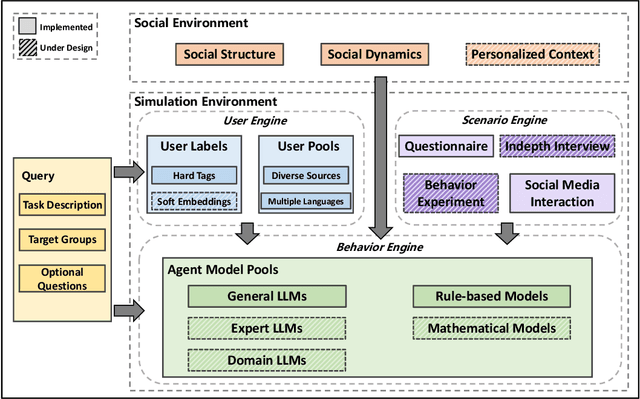

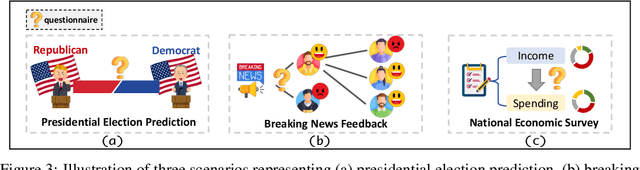
Social simulation is transforming traditional social science research by modeling human behavior through interactions between virtual individuals and their environments. With recent advances in large language models (LLMs), this approach has shown growing potential in capturing individual differences and predicting group behaviors. However, existing methods face alignment challenges related to the environment, target users, interaction mechanisms, and behavioral patterns. To this end, we introduce SocioVerse, an LLM-agent-driven world model for social simulation. Our framework features four powerful alignment components and a user pool of 10 million real individuals. To validate its effectiveness, we conducted large-scale simulation experiments across three distinct domains: politics, news, and economics. Results demonstrate that SocioVerse can reflect large-scale population dynamics while ensuring diversity, credibility, and representativeness through standardized procedures and minimal manual adjustments.
From Selection to Generation: A Survey of LLM-based Active Learning
Feb 17, 2025Active Learning (AL) has been a powerful paradigm for improving model efficiency and performance by selecting the most informative data points for labeling and training. In recent active learning frameworks, Large Language Models (LLMs) have been employed not only for selection but also for generating entirely new data instances and providing more cost-effective annotations. Motivated by the increasing importance of high-quality data and efficient model training in the era of LLMs, we present a comprehensive survey on LLM-based Active Learning. We introduce an intuitive taxonomy that categorizes these techniques and discuss the transformative roles LLMs can play in the active learning loop. We further examine the impact of AL on LLM learning paradigms and its applications across various domains. Finally, we identify open challenges and propose future research directions. This survey aims to serve as an up-to-date resource for researchers and practitioners seeking to gain an intuitive understanding of LLM-based AL techniques and deploy them to new applications.
Can LLMs Simulate Social Media Engagement? A Study on Action-Guided Response Generation
Feb 17, 2025



Social media enables dynamic user engagement with trending topics, and recent research has explored the potential of large language models (LLMs) for response generation. While some studies investigate LLMs as agents for simulating user behavior on social media, their focus remains on practical viability and scalability rather than a deeper understanding of how well LLM aligns with human behavior. This paper analyzes LLMs' ability to simulate social media engagement through action guided response generation, where a model first predicts a user's most likely engagement action-retweet, quote, or rewrite-towards a trending post before generating a personalized response conditioned on the predicted action. We benchmark GPT-4o-mini, O1-mini, and DeepSeek-R1 in social media engagement simulation regarding a major societal event discussed on X. Our findings reveal that zero-shot LLMs underperform BERT in action prediction, while few-shot prompting initially degrades the prediction accuracy of LLMs with limited examples. However, in response generation, few-shot LLMs achieve stronger semantic alignment with ground truth posts.
Irony in Emojis: A Comparative Study of Human and LLM Interpretation
Jan 20, 2025Emojis have become a universal language in online communication, often carrying nuanced and context-dependent meanings. Among these, irony poses a significant challenge for Large Language Models (LLMs) due to its inherent incongruity between appearance and intent. This study examines the ability of GPT-4o to interpret irony in emojis. By prompting GPT-4o to evaluate the likelihood of specific emojis being used to express irony on social media and comparing its interpretations with human perceptions, we aim to bridge the gap between machine and human understanding. Our findings reveal nuanced insights into GPT-4o's interpretive capabilities, highlighting areas of alignment with and divergence from human behavior. Additionally, this research underscores the importance of demographic factors, such as age and gender, in shaping emoji interpretation and evaluates how these factors influence GPT-4o's performance.
GUI Agents: A Survey
Dec 18, 2024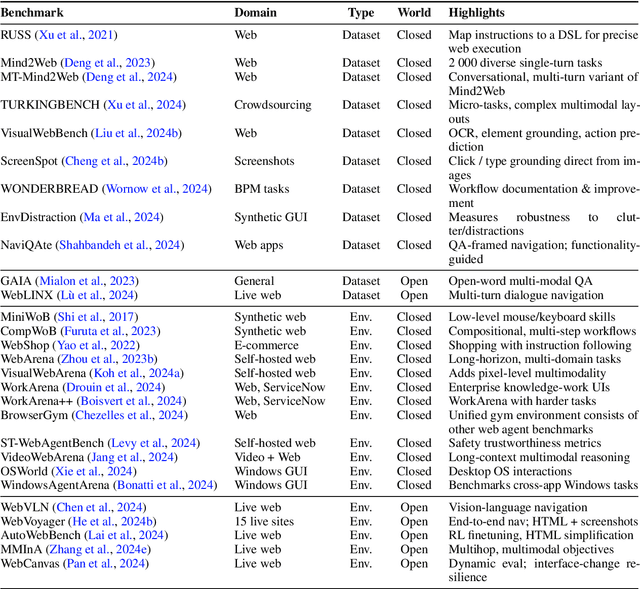
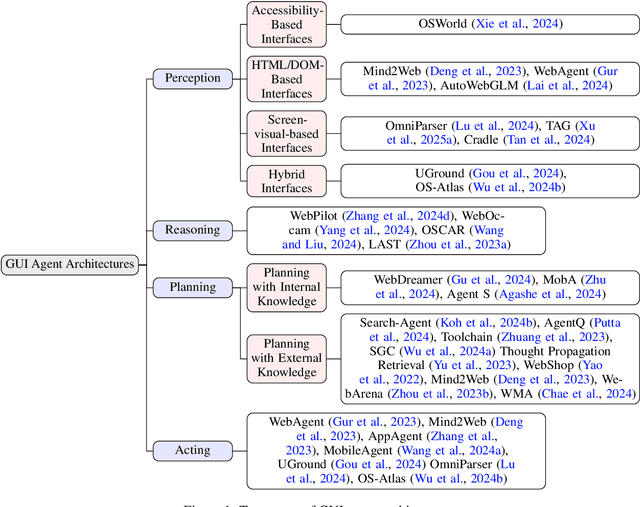

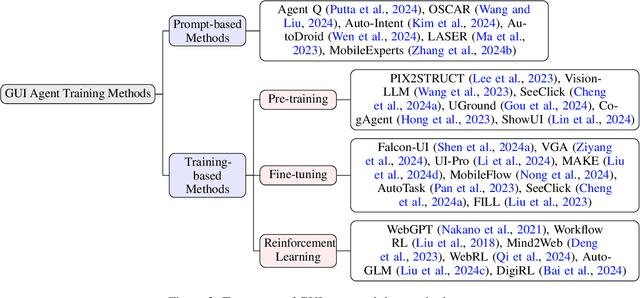
Graphical User Interface (GUI) agents, powered by Large Foundation Models, have emerged as a transformative approach to automating human-computer interaction. These agents autonomously interact with digital systems or software applications via GUIs, emulating human actions such as clicking, typing, and navigating visual elements across diverse platforms. Motivated by the growing interest and fundamental importance of GUI agents, we provide a comprehensive survey that categorizes their benchmarks, evaluation metrics, architectures, and training methods. We propose a unified framework that delineates their perception, reasoning, planning, and acting capabilities. Furthermore, we identify important open challenges and discuss key future directions. Finally, this work serves as a basis for practitioners and researchers to gain an intuitive understanding of current progress, techniques, benchmarks, and critical open problems that remain to be addressed.