 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCheers: Decoupling Patch Details from Semantic Representations Enables Unified Multimodal Comprehension and Generation
Mar 13, 2026A recent cutting-edge topic in multimodal modeling is to unify visual comprehension and generation within a single model. However, the two tasks demand mismatched decoding regimes and visual representations, making it non-trivial to jointly optimize within a shared feature space. In this work, we present Cheers, a unified multimodal model that decouples patch-level details from semantic representations, thereby stabilizing semantics for multimodal understanding and improving fidelity for image generation via gated detail residuals. Cheers includes three key components: (i) a unified vision tokenizer that encodes and compresses image latent states into semantic tokens for efficient LLM conditioning, (ii) an LLM-based Transformer that unifies autoregressive decoding for text generation and diffusion decoding for image generation, and (iii) a cascaded flow matching head that decodes visual semantics first and then injects semantically gated detail residuals from the vision tokenizer to refine high-frequency content. Experiments on popular benchmarks demonstrate that Cheers matches or surpasses advanced UMMs in both visual understanding and generation. Cheers also achieves 4x token compression, enabling more efficient high-resolution image encoding and generation. Notably, Cheers outperforms the Tar-1.5B on the popular benchmarks GenEval and MMBench, while requiring only 20% of the training cost, indicating effective and efficient (i.e., 4x token compression) unified multimodal modeling. We will release all code and data for future research.
MiLDEdit: Reasoning-Based Multi-Layer Design Document Editing
Jan 08, 2026Real-world design documents (e.g., posters) are inherently multi-layered, combining decoration, text, and images. Editing them from natural-language instructions requires fine-grained, layer-aware reasoning to identify relevant layers and coordinate modifications. Prior work largely overlooks multi-layer design document editing, focusing instead on single-layer image editing or multi-layer generation, which assume a flat canvas and lack the reasoning needed to determine what and where to modify. To address this gap, we introduce the Multi-Layer Document Editing Agent (MiLDEAgent), a reasoning-based framework that combines an RL-trained multimodal reasoner for layer-wise understanding with an image editor for targeted modifications. To systematically benchmark this setting, we introduce the MiLDEBench, a human-in-the-loop corpus of over 20K design documents paired with diverse editing instructions. The benchmark is complemented by a task-specific evaluation protocol, MiLDEEval, which spans four dimensions including instruction following, layout consistency, aesthetics, and text rendering. Extensive experiments on 14 open-source and 2 closed-source models reveal that existing approaches fail to generalize: open-source models often cannot complete multi-layer document editing tasks, while closed-source models suffer from format violations. In contrast, MiLDEAgent achieves strong layer-aware reasoning and precise editing, significantly outperforming all open-source baselines and attaining performance comparable to closed-source models, thereby establishing the first strong baseline for multi-layer document editing.
Encyclo-K: Evaluating LLMs with Dynamically Composed Knowledge Statements
Dec 31, 2025Benchmarks play a crucial role in tracking the rapid advancement of large language models (LLMs) and identifying their capability boundaries. However, existing benchmarks predominantly curate questions at the question level, suffering from three fundamental limitations: vulnerability to data contamination, restriction to single-knowledge-point assessment, and reliance on costly domain expert annotation. We propose Encyclo-K, a statement-based benchmark that rethinks benchmark construction from the ground up. Our key insight is that knowledge statements, not questions, can serve as the unit of curation, and questions can then be constructed from them. We extract standalone knowledge statements from authoritative textbooks and dynamically compose them into evaluation questions through random sampling at test time. This design directly addresses all three limitations: the combinatorial space is too vast to memorize, and model rankings remain stable across dynamically generated question sets, enabling reliable periodic dataset refresh; each question aggregates 8-10 statements for comprehensive multi-knowledge assessment; annotators only verify formatting compliance without requiring domain expertise, substantially reducing annotation costs. Experiments on over 50 LLMs demonstrate that Encyclo-K poses substantial challenges with strong discriminative power. Even the top-performing OpenAI-GPT-5.1 achieves only 62.07% accuracy, and model performance displays a clear gradient distribution--reasoning models span from 16.04% to 62.07%, while chat models range from 9.71% to 50.40%. These results validate the challenges introduced by dynamic evaluation and multi-statement comprehensive understanding. These findings establish Encyclo-K as a scalable framework for dynamic evaluation of LLMs' comprehensive understanding over multiple fine-grained disciplinary knowledge statements.
OIDA-QA: A Multimodal Benchmark for Analyzing the Opioid Industry Documents Archive
Nov 14, 2025The opioid crisis represents a significant moment in public health that reveals systemic shortcomings across regulatory systems, healthcare practices, corporate governance, and public policy. Analyzing how these interconnected systems simultaneously failed to protect public health requires innovative analytic approaches for exploring the vast amounts of data and documents disclosed in the UCSF-JHU Opioid Industry Documents Archive (OIDA). The complexity, multimodal nature, and specialized characteristics of these healthcare-related legal and corporate documents necessitate more advanced methods and models tailored to specific data types and detailed annotations, ensuring the precision and professionalism in the analysis. In this paper, we tackle this challenge by organizing the original dataset according to document attributes and constructing a benchmark with 400k training documents and 10k for testing. From each document, we extract rich multimodal information-including textual content, visual elements, and layout structures-to capture a comprehensive range of features. Using multiple AI models, we then generate a large-scale dataset comprising 360k training QA pairs and 10k testing QA pairs. Building on this foundation, we develop domain-specific multimodal Large Language Models (LLMs) and explore the impact of multimodal inputs on task performance. To further enhance response accuracy, we incorporate historical QA pairs as contextual grounding for answering current queries. Additionally, we incorporate page references within the answers and introduce an importance-based page classifier, further improving the precision and relevance of the information provided. Preliminary results indicate the improvements with our AI assistant in document information extraction and question-answering tasks. The dataset is available at: https://huggingface.co/datasets/opioidarchive/oida-qa
ROD: RGB-Only Fast and Efficient Off-road Freespace Detection
Aug 12, 2025



Off-road freespace detection is more challenging than on-road scenarios because of the blurred boundaries of traversable areas. Previous state-of-the-art (SOTA) methods employ multi-modal fusion of RGB images and LiDAR data. However, due to the significant increase in inference time when calculating surface normal maps from LiDAR data, multi-modal methods are not suitable for real-time applications, particularly in real-world scenarios where higher FPS is required compared to slow navigation. This paper presents a novel RGB-only approach for off-road freespace detection, named ROD, eliminating the reliance on LiDAR data and its computational demands. Specifically, we utilize a pre-trained Vision Transformer (ViT) to extract rich features from RGB images. Additionally, we design a lightweight yet efficient decoder, which together improve both precision and inference speed. ROD establishes a new SOTA on ORFD and RELLIS-3D datasets, as well as an inference speed of 50 FPS, significantly outperforming prior models.
StructVRM: Aligning Multimodal Reasoning with Structured and Verifiable Reward Models
Aug 07, 2025



Existing Vision-Language Models often struggle with complex, multi-question reasoning tasks where partial correctness is crucial for effective learning. Traditional reward mechanisms, which provide a single binary score for an entire response, are too coarse to guide models through intricate problems with multiple sub-parts. To address this, we introduce StructVRM, a method that aligns multimodal reasoning with Structured and Verifiable Reward Models. At its core is a model-based verifier trained to provide fine-grained, sub-question-level feedback, assessing semantic and mathematical equivalence rather than relying on rigid string matching. This allows for nuanced, partial credit scoring in previously intractable problem formats. Extensive experiments demonstrate the effectiveness of StructVRM. Our trained model, Seed-StructVRM, achieves state-of-the-art performance on six out of twelve public multimodal benchmarks and our newly curated, high-difficulty STEM-Bench. The success of StructVRM validates that training with structured, verifiable rewards is a highly effective approach for advancing the capabilities of multimodal models in complex, real-world reasoning domains.
Scaling Up Audio-Synchronized Visual Animation: An Efficient Training Paradigm
Aug 05, 2025Recent advances in audio-synchronized visual animation enable control of video content using audios from specific classes. However, existing methods rely heavily on expensive manual curation of high-quality, class-specific training videos, posing challenges to scaling up to diverse audio-video classes in the open world. In this work, we propose an efficient two-stage training paradigm to scale up audio-synchronized visual animation using abundant but noisy videos. In stage one, we automatically curate large-scale videos for pretraining, allowing the model to learn diverse but imperfect audio-video alignments. In stage two, we finetune the model on manually curated high-quality examples, but only at a small scale, significantly reducing the required human effort. We further enhance synchronization by allowing each frame to access rich audio context via multi-feature conditioning and window attention. To efficiently train the model, we leverage pretrained text-to-video generator and audio encoders, introducing only 1.9\% additional trainable parameters to learn audio-conditioning capability without compromising the generator's prior knowledge. For evaluation, we introduce AVSync48, a benchmark with videos from 48 classes, which is 3$\times$ more diverse than previous benchmarks. Extensive experiments show that our method significantly reduces reliance on manual curation by over 10$\times$, while generalizing to many open classes.
Seed-Prover: Deep and Broad Reasoning for Automated Theorem Proving
Aug 01, 2025LLMs have demonstrated strong mathematical reasoning abilities by leveraging reinforcement learning with long chain-of-thought, yet they continue to struggle with theorem proving due to the lack of clear supervision signals when solely using natural language. Dedicated domain-specific languages like Lean provide clear supervision via formal verification of proofs, enabling effective training through reinforcement learning. In this work, we propose \textbf{Seed-Prover}, a lemma-style whole-proof reasoning model. Seed-Prover can iteratively refine its proof based on Lean feedback, proved lemmas, and self-summarization. To solve IMO-level contest problems, we design three test-time inference strategies that enable both deep and broad reasoning. Seed-Prover proves $78.1\%$ of formalized past IMO problems, saturates MiniF2F, and achieves over 50\% on PutnamBench, outperforming the previous state-of-the-art by a large margin. To address the lack of geometry support in Lean, we introduce a geometry reasoning engine \textbf{Seed-Geometry}, which outperforms previous formal geometry engines. We use these two systems to participate in IMO 2025 and fully prove 5 out of 6 problems. This work represents a significant advancement in automated mathematical reasoning, demonstrating the effectiveness of formal verification with long chain-of-thought reasoning.
Towards Visual Text Grounding of Multimodal Large Language Model
Apr 07, 2025

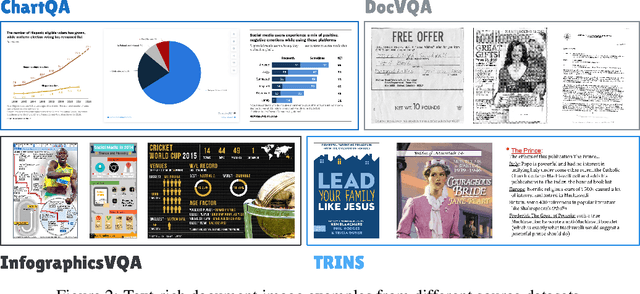

Despite the existing evolution of Multimodal Large Language Models (MLLMs), a non-neglectable limitation remains in their struggle with visual text grounding, especially in text-rich images of documents. Document images, such as scanned forms and infographics, highlight critical challenges due to their complex layouts and textual content. However, current benchmarks do not fully address these challenges, as they mostly focus on visual grounding on natural images, rather than text-rich document images. Thus, to bridge this gap, we introduce TRIG, a novel task with a newly designed instruction dataset for benchmarking and improving the Text-Rich Image Grounding capabilities of MLLMs in document question-answering. Specifically, we propose an OCR-LLM-human interaction pipeline to create 800 manually annotated question-answer pairs as a benchmark and a large-scale training set of 90$ synthetic data based on four diverse datasets. A comprehensive evaluation of various MLLMs on our proposed benchmark exposes substantial limitations in their grounding capability on text-rich images. In addition, we propose two simple and effective TRIG methods based on general instruction tuning and plug-and-play efficient embedding, respectively. By finetuning MLLMs on our synthetic dataset, they promisingly improve spatial reasoning and grounding capabilities.
MDocAgent: A Multi-Modal Multi-Agent Framework for Document Understanding
Mar 18, 2025Document Question Answering (DocQA) is a very common task. Existing methods using Large Language Models (LLMs) or Large Vision Language Models (LVLMs) and Retrieval Augmented Generation (RAG) often prioritize information from a single modal, failing to effectively integrate textual and visual cues. These approaches struggle with complex multi-modal reasoning, limiting their performance on real-world documents. We present MDocAgent (A Multi-Modal Multi-Agent Framework for Document Understanding), a novel RAG and multi-agent framework that leverages both text and image. Our system employs five specialized agents: a general agent, a critical agent, a text agent, an image agent and a summarizing agent. These agents engage in multi-modal context retrieval, combining their individual insights to achieve a more comprehensive understanding of the document's content. This collaborative approach enables the system to synthesize information from both textual and visual components, leading to improved accuracy in question answering. Preliminary experiments on five benchmarks like MMLongBench, LongDocURL demonstrate the effectiveness of our MDocAgent, achieve an average improvement of 12.1% compared to current state-of-the-art method. This work contributes to the development of more robust and comprehensive DocQA systems capable of handling the complexities of real-world documents containing rich textual and visual information. Our data and code are available at https://github.com/aiming-lab/MDocAgent.