 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt2Effect: Training-Free Image-to-Video Model Specialization via LoRA Generation
Jun 11, 2026Personalizing Image-to-Video (I2V) diffusion models with specific visual effects is increasingly demanded for high-end video generation. Current practice requires training a separate Low-Rank Adaptation (LoRA) module for each effect, incurring substantial data curation and iterative optimization costs that hinder interactive control. We present Prompt2Effect, a weight-driven hypernetwork that amortizes per-effect training by directly synthesizing effect-specific LoRA weights in a single forward pass. Unlike prior hypernetworks that regress adapter weights purely from semantics, Prompt2Effect is explicitly conditioned on the frozen base model weights, grounding weight prediction in the structural geometry of each layer. Furthermore, instead of predicting raw LoRA matrices, we introduce an SVD-canonicalized parameterization that resolves factorization ambiguity and stabilizes large-scale weight synthesis. Together, these design principles enable accurate and scalable LoRA prediction for high-dimensional I2V diffusion models. Extensive experiments demonstrate that Prompt2Effect achieves on-par or superior video quality and effect alignment compared to conventional LoRA fine-tuning, while reducing the computational cost from 56 GPU training hours to 3.3 seconds of hypernetwork inference. When used as initialization for subsequent fine-tuning, our predicted weights further improve final performance and accelerate optimization by approximately 10x.
EFlow: Fast Few-Step Video Generator Training from Scratch via Efficient Solution Flow
Mar 28, 2026Scaling video diffusion transformers is fundamentally bottlenecked by two compounding costs: the expensive quadratic complexity of attention per step, and the iterative sampling steps. In this work, we propose EFlow, an efficient few-step training framework, that tackles these bottlenecks simultaneously. To reduce sampling steps, we build on a solution-flow objective that learns a function mapping a noised state at time t to time s. Making this formulation computationally feasible and high-quality at video scale, however, demands two complementary innovations. First, we propose Gated Local-Global Attention, a token-droppable hybrid block which is efficient, expressive, and remains highly stable under aggressive random token-dropping, substantially reducing per-step compute. Second, we develop an efficient few-step training recipe. We propose Path-Drop Guided training to replace the expensive guidance target with a computationally cheap, weak path. Furthermore, we augment this with a Mean-Velocity Additivity regularizer to ensure high fidelity at extremely low step counts. Together, our EFlow enables a practical from-scratch training pipeline, achieving up to 2.5x higher training throughput over standard solution-flow, and 45.3x lower inference latency than standard iterative models with competitive performance on Kinetics and large-scale text-to-video datasets.
S2DiT: Sandwich Diffusion Transformer for Mobile Streaming Video Generation
Jan 19, 2026Diffusion Transformers (DiTs) have recently improved video generation quality. However, their heavy computational cost makes real-time or on-device generation infeasible. In this work, we introduce S2DiT, a Streaming Sandwich Diffusion Transformer designed for efficient, high-fidelity, and streaming video generation on mobile hardware. S2DiT generates more tokens but maintains efficiency with novel efficient attentions: a mixture of LinConv Hybrid Attention (LCHA) and Stride Self-Attention (SSA). Based on this, we uncover the sandwich design via a budget-aware dynamic programming search, achieving superior quality and efficiency. We further propose a 2-in-1 distillation framework that transfers the capacity of large teacher models (e.g., Wan 2.2-14B) to the compact few-step sandwich model. Together, S2DiT achieves quality on par with state-of-the-art server video models, while streaming at over 10 FPS on an iPhone.
SnapGen++: Unleashing Diffusion Transformers for Efficient High-Fidelity Image Generation on Edge Devices
Jan 13, 2026Recent advances in diffusion transformers (DiTs) have set new standards in image generation, yet remain impractical for on-device deployment due to their high computational and memory costs. In this work, we present an efficient DiT framework tailored for mobile and edge devices that achieves transformer-level generation quality under strict resource constraints. Our design combines three key components. First, we propose a compact DiT architecture with an adaptive global-local sparse attention mechanism that balances global context modeling and local detail preservation. Second, we propose an elastic training framework that jointly optimizes sub-DiTs of varying capacities within a unified supernetwork, allowing a single model to dynamically adjust for efficient inference across different hardware. Finally, we develop Knowledge-Guided Distribution Matching Distillation, a step-distillation pipeline that integrates the DMD objective with knowledge transfer from few-step teacher models, producing high-fidelity and low-latency generation (e.g., 4-step) suitable for real-time on-device use. Together, these contributions enable scalable, efficient, and high-quality diffusion models for deployment on diverse hardware.
Diffusion-DRF: Differentiable Reward Flow for Video Diffusion Fine-Tuning
Jan 07, 2026Direct Preference Optimization (DPO) has recently improved Text-to-Video (T2V) generation by enhancing visual fidelity and text alignment. However, current methods rely on non-differentiable preference signals from human annotations or learned reward models. This reliance makes training label-intensive, bias-prone, and easy-to-game, which often triggers reward hacking and unstable training. We propose Diffusion-DRF, a differentiable reward flow for fine-tuning video diffusion models using a frozen, off-the-shelf Vision-Language Model (VLM) as a training-free critic. Diffusion-DRF directly backpropagates VLM feedback through the diffusion denoising chain, converting logit-level responses into token-aware gradients for optimization. We propose an automated, aspect-structured prompting pipeline to obtain reliable multi-dimensional VLM feedback, while gradient checkpointing enables efficient updates through the final denoising steps. Diffusion-DRF improves video quality and semantic alignment while mitigating reward hacking and collapse -- without additional reward models or preference datasets. It is model-agnostic and readily generalizes to other diffusion-based generative tasks.
Taming Diffusion Transformer for Real-Time Mobile Video Generation
Jul 17, 2025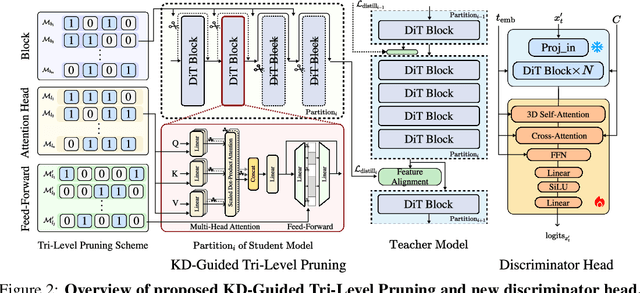
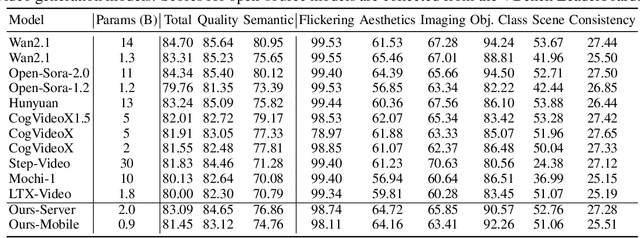

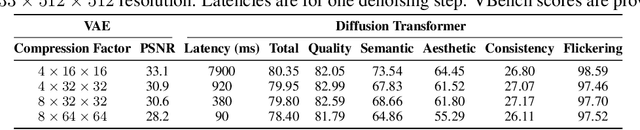
Diffusion Transformers (DiT) have shown strong performance in video generation tasks, but their high computational cost makes them impractical for resource-constrained devices like smartphones, and real-time generation is even more challenging. In this work, we propose a series of novel optimizations to significantly accelerate video generation and enable real-time performance on mobile platforms. First, we employ a highly compressed variational autoencoder (VAE) to reduce the dimensionality of the input data without sacrificing visual quality. Second, we introduce a KD-guided, sensitivity-aware tri-level pruning strategy to shrink the model size to suit mobile platform while preserving critical performance characteristics. Third, we develop an adversarial step distillation technique tailored for DiT, which allows us to reduce the number of inference steps to four. Combined, these optimizations enable our model to achieve over 10 frames per second (FPS) generation on an iPhone 16 Pro Max, demonstrating the feasibility of real-time, high-quality video generation on mobile devices.
CountDiffusion: Text-to-Image Synthesis with Training-Free Counting-Guidance Diffusion
May 07, 2025Stable Diffusion has advanced text-to-image synthesis, but training models to generate images with accurate object quantity is still difficult due to the high computational cost and the challenge of teaching models the abstract concept of quantity. In this paper, we propose CountDiffusion, a training-free framework aiming at generating images with correct object quantity from textual descriptions. CountDiffusion consists of two stages. In the first stage, an intermediate denoising result is generated by the diffusion model to predict the final synthesized image with one-step denoising, and a counting model is used to count the number of objects in this image. In the second stage, a correction module is used to correct the object quantity by changing the attention map of the object with universal guidance. The proposed CountDiffusion can be plugged into any diffusion-based text-to-image (T2I) generation models without further training. Experiment results demonstrate the superiority of our proposed CountDiffusion, which improves the accurate object quantity generation ability of T2I models by a large margin.
H3AE: High Compression, High Speed, and High Quality AutoEncoder for Video Diffusion Models
Apr 14, 2025Autoencoder (AE) is the key to the success of latent diffusion models for image and video generation, reducing the denoising resolution and improving efficiency. However, the power of AE has long been underexplored in terms of network design, compression ratio, and training strategy. In this work, we systematically examine the architecture design choices and optimize the computation distribution to obtain a series of efficient and high-compression video AEs that can decode in real time on mobile devices. We also unify the design of plain Autoencoder and image-conditioned I2V VAE, achieving multifunctionality in a single network. In addition, we find that the widely adopted discriminative losses, i.e., GAN, LPIPS, and DWT losses, provide no significant improvements when training AEs at scale. We propose a novel latent consistency loss that does not require complicated discriminator design or hyperparameter tuning, but provides stable improvements in reconstruction quality. Our AE achieves an ultra-high compression ratio and real-time decoding speed on mobile while outperforming prior art in terms of reconstruction metrics by a large margin. We finally validate our AE by training a DiT on its latent space and demonstrate fast, high-quality text-to-video generation capability.
Improving the Diffusability of Autoencoders
Feb 20, 2025Latent diffusion models have emerged as the leading approach for generating high-quality images and videos, utilizing compressed latent representations to reduce the computational burden of the diffusion process. While recent advancements have primarily focused on scaling diffusion backbones and improving autoencoder reconstruction quality, the interaction between these components has received comparatively less attention. In this work, we perform a spectral analysis of modern autoencoders and identify inordinate high-frequency components in their latent spaces, which are especially pronounced in the autoencoders with a large bottleneck channel size. We hypothesize that this high-frequency component interferes with the coarse-to-fine nature of the diffusion synthesis process and hinders the generation quality. To mitigate the issue, we propose scale equivariance: a simple regularization strategy that aligns latent and RGB spaces across frequencies by enforcing scale equivariance in the decoder. It requires minimal code changes and only up to 20K autoencoder fine-tuning steps, yet significantly improves generation quality, reducing FID by 19% for image generation on ImageNet-1K 256x256 and FVD by at least 44% for video generation on Kinetics-700 17x256x256.
LazyDiT: Lazy Learning for the Acceleration of Diffusion Transformers
Dec 17, 2024Diffusion Transformers have emerged as the preeminent models for a wide array of generative tasks, demonstrating superior performance and efficacy across various applications. The promising results come at the cost of slow inference, as each denoising step requires running the whole transformer model with a large amount of parameters. In this paper, we show that performing the full computation of the model at each diffusion step is unnecessary, as some computations can be skipped by lazily reusing the results of previous steps. Furthermore, we show that the lower bound of similarity between outputs at consecutive steps is notably high, and this similarity can be linearly approximated using the inputs. To verify our demonstrations, we propose the \textbf{LazyDiT}, a lazy learning framework that efficiently leverages cached results from earlier steps to skip redundant computations. Specifically, we incorporate lazy learning layers into the model, effectively trained to maximize laziness, enabling dynamic skipping of redundant computations. Experimental results show that LazyDiT outperforms the DDIM sampler across multiple diffusion transformer models at various resolutions. Furthermore, we implement our method on mobile devices, achieving better performance than DDIM with similar latency.