 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgetttLRM: Test-Time Training for Long Context and Autoregressive 3D Reconstruction
Feb 23, 2026We propose tttLRM, a novel large 3D reconstruction model that leverages a Test-Time Training (TTT) layer to enable long-context, autoregressive 3D reconstruction with linear computational complexity, further scaling the model's capability. Our framework efficiently compresses multiple image observations into the fast weights of the TTT layer, forming an implicit 3D representation in the latent space that can be decoded into various explicit formats, such as Gaussian Splats (GS) for downstream applications. The online learning variant of our model supports progressive 3D reconstruction and refinement from streaming observations. We demonstrate that pretraining on novel view synthesis tasks effectively transfers to explicit 3D modeling, resulting in improved reconstruction quality and faster convergence. Extensive experiments show that our method achieves superior performance in feedforward 3D Gaussian reconstruction compared to state-of-the-art approaches on both objects and scenes.
E-RayZer: Self-supervised 3D Reconstruction as Spatial Visual Pre-training
Dec 11, 2025



Self-supervised pre-training has revolutionized foundation models for languages, individual 2D images and videos, but remains largely unexplored for learning 3D-aware representations from multi-view images. In this paper, we present E-RayZer, a self-supervised large 3D Vision model that learns truly 3D-aware representations directly from unlabeled images. Unlike prior self-supervised methods such as RayZer that infer 3D indirectly through latent-space view synthesis, E-RayZer operates directly in 3D space, performing self-supervised 3D reconstruction with Explicit geometry. This formulation eliminates shortcut solutions and yields representations that are geometrically grounded. To ensure convergence and scalability, we introduce a novel fine-grained learning curriculum that organizes training from easy to hard samples and harmonizes heterogeneous data sources in an entirely unsupervised manner. Experiments demonstrate that E-RayZer significantly outperforms RayZer on pose estimation, matches or sometimes surpasses fully supervised reconstruction models such as VGGT. Furthermore, its learned representations outperform leading visual pre-training models (e.g., DINOv3, CroCo v2, VideoMAE V2, and RayZer) when transferring to 3D downstream tasks, establishing E-RayZer as a new paradigm for 3D-aware visual pre-training.
pi-Flow: Policy-Based Few-Step Generation via Imitation Distillation
Oct 16, 2025Few-step diffusion or flow-based generative models typically distill a velocity-predicting teacher into a student that predicts a shortcut towards denoised data. This format mismatch has led to complex distillation procedures that often suffer from a quality-diversity trade-off. To address this, we propose policy-based flow models ($\pi$-Flow). $\pi$-Flow modifies the output layer of a student flow model to predict a network-free policy at one timestep. The policy then produces dynamic flow velocities at future substeps with negligible overhead, enabling fast and accurate ODE integration on these substeps without extra network evaluations. To match the policy's ODE trajectory to the teacher's, we introduce a novel imitation distillation approach, which matches the policy's velocity to the teacher's along the policy's trajectory using a standard $\ell_2$ flow matching loss. By simply mimicking the teacher's behavior, $\pi$-Flow enables stable and scalable training and avoids the quality-diversity trade-off. On ImageNet 256$^2$, it attains a 1-NFE FID of 2.85, outperforming MeanFlow of the same DiT architecture. On FLUX.1-12B and Qwen-Image-20B at 4 NFEs, $\pi$-Flow achieves substantially better diversity than state-of-the-art few-step methods, while maintaining teacher-level quality.
4D-LRM: Large Space-Time Reconstruction Model From and To Any View at Any Time
Jun 23, 2025Can we scale 4D pretraining to learn general space-time representations that reconstruct an object from a few views at some times to any view at any time? We provide an affirmative answer with 4D-LRM, the first large-scale 4D reconstruction model that takes input from unconstrained views and timestamps and renders arbitrary novel view-time combinations. Unlike prior 4D approaches, e.g., optimization-based, geometry-based, or generative, that struggle with efficiency, generalization, or faithfulness, 4D-LRM learns a unified space-time representation and directly predicts per-pixel 4D Gaussian primitives from posed image tokens across time, enabling fast, high-quality rendering at, in principle, infinite frame rate. Our results demonstrate that scaling spatiotemporal pretraining enables accurate and efficient 4D reconstruction. We show that 4D-LRM generalizes to novel objects, interpolates across time, and handles diverse camera setups. It reconstructs 24-frame sequences in one forward pass with less than 1.5 seconds on a single A100 GPU.
Test-Time Training Done Right
May 29, 2025



Test-Time Training (TTT) models context dependencies by adapting part of the model's weights (referred to as fast weights) during inference. This fast weight, akin to recurrent states in RNNs, stores temporary memories of past tokens in the current sequence. Existing TTT methods struggled to show effectiveness in handling long-context data, due to their inefficiency on modern GPUs. The TTT layers in many of these approaches operate with extremely low FLOPs utilization (often <5%) because they deliberately apply small online minibatch sizes (e.g., updating fast weights every 16 or 64 tokens). Moreover, a small minibatch implies fine-grained block-wise causal dependencies in the data, unsuitable for data beyond 1D ordered sequences, like sets or N-dimensional grids such as images or videos. In contrast, we pursue the opposite direction by using an extremely large chunk update, ranging from 2K to 1M tokens across tasks of varying modalities, which we refer to as Large Chunk Test-Time Training (LaCT). It improves hardware utilization by orders of magnitude, and more importantly, facilitates scaling of nonlinear state size (up to 40% of model parameters), hence substantially improving state capacity, all without requiring cumbersome and error-prone kernel implementations. It also allows easy integration of sophisticated optimizers, e.g. Muon for online updates. We validate our approach across diverse modalities and tasks, including novel view synthesis with image set, language models, and auto-regressive video diffusion. Our approach can scale up to 14B-parameter AR video diffusion model on sequences up to 56K tokens. In our longest sequence experiment, we perform novel view synthesis with 1 million context length. We hope this work will inspire and accelerate new research in the field of long-context modeling and test-time training. Website: https://tianyuanzhang.com/projects/ttt-done-right
Neural BRDF Importance Sampling by Reparameterization
May 13, 2025Neural bidirectional reflectance distribution functions (BRDFs) have emerged as popular material representations for enhancing realism in physically-based rendering. Yet their importance sampling remains a significant challenge. In this paper, we introduce a reparameterization-based formulation of neural BRDF importance sampling that seamlessly integrates into the standard rendering pipeline with precise generation of BRDF samples. The reparameterization-based formulation transfers the distribution learning task to a problem of identifying BRDF integral substitutions. In contrast to previous methods that rely on invertible networks and multi-step inference to reconstruct BRDF distributions, our model removes these constraints, which offers greater flexibility and efficiency. Our variance and performance analysis demonstrates that our reparameterization method achieves the best variance reduction in neural BRDF renderings while maintaining high inference speeds compared to existing baselines.
RayZer: A Self-supervised Large View Synthesis Model
May 01, 2025



We present RayZer, a self-supervised multi-view 3D Vision model trained without any 3D supervision, i.e., camera poses and scene geometry, while exhibiting emerging 3D awareness. Concretely, RayZer takes unposed and uncalibrated images as input, recovers camera parameters, reconstructs a scene representation, and synthesizes novel views. During training, RayZer relies solely on its self-predicted camera poses to render target views, eliminating the need for any ground-truth camera annotations and allowing RayZer to be trained with 2D image supervision. The emerging 3D awareness of RayZer is attributed to two key factors. First, we design a self-supervised framework, which achieves 3D-aware auto-encoding of input images by disentangling camera and scene representations. Second, we design a transformer-based model in which the only 3D prior is the ray structure, connecting camera, pixel, and scene simultaneously. RayZer demonstrates comparable or even superior novel view synthesis performance than ``oracle'' methods that rely on pose annotations in both training and testing. Project: https://hwjiang1510.github.io/RayZer/
Gaussian Mixture Flow Matching Models
Apr 07, 2025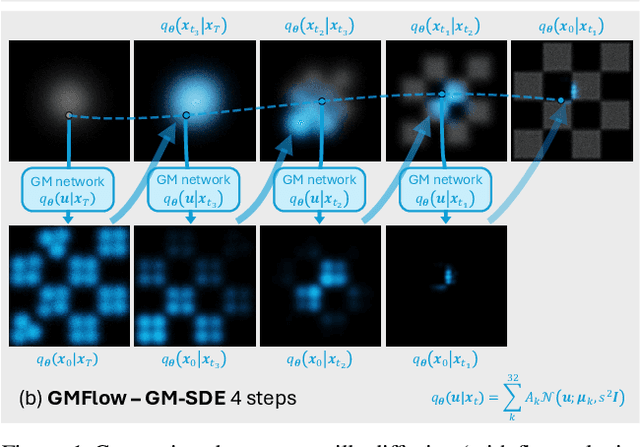
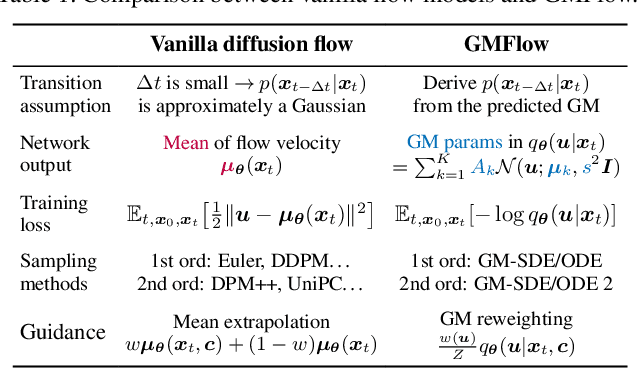
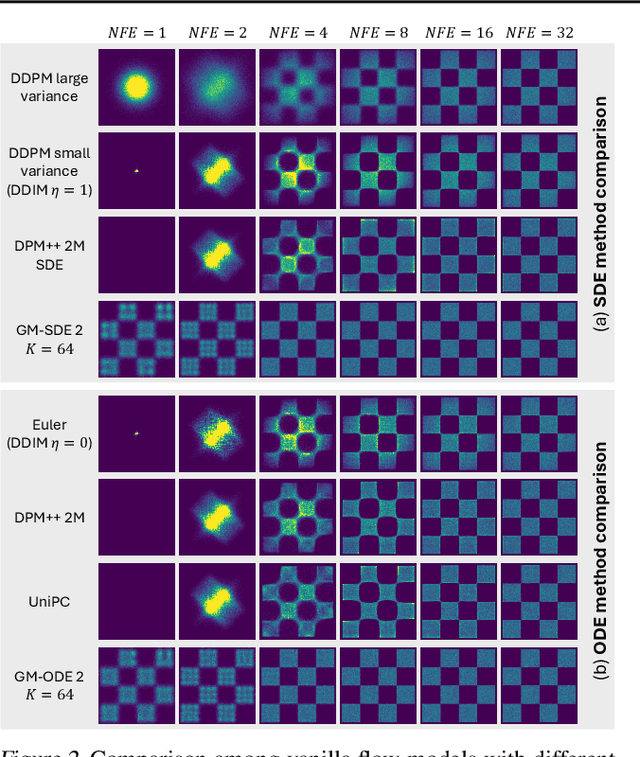
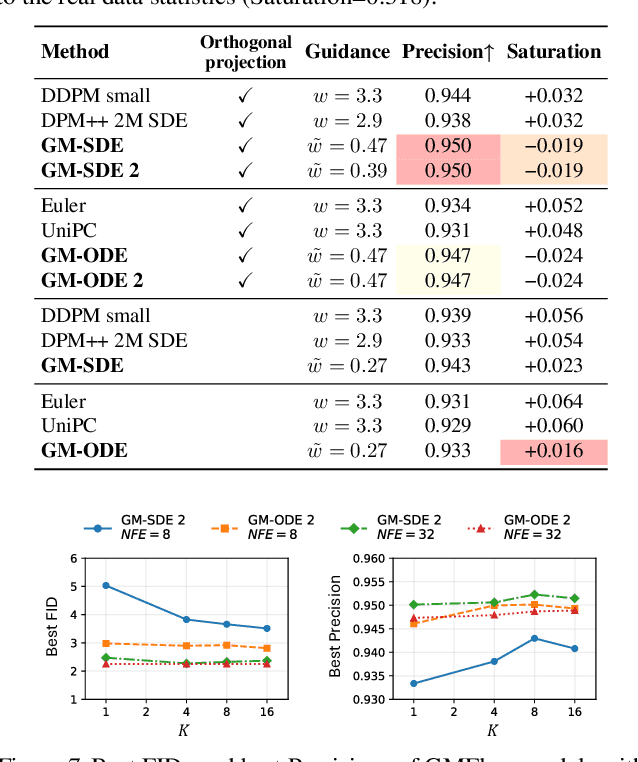
Diffusion models approximate the denoising distribution as a Gaussian and predict its mean, whereas flow matching models reparameterize the Gaussian mean as flow velocity. However, they underperform in few-step sampling due to discretization error and tend to produce over-saturated colors under classifier-free guidance (CFG). To address these limitations, we propose a novel Gaussian mixture flow matching (GMFlow) model: instead of predicting the mean, GMFlow predicts dynamic Gaussian mixture (GM) parameters to capture a multi-modal flow velocity distribution, which can be learned with a KL divergence loss. We demonstrate that GMFlow generalizes previous diffusion and flow matching models where a single Gaussian is learned with an $L_2$ denoising loss. For inference, we derive GM-SDE/ODE solvers that leverage analytic denoising distributions and velocity fields for precise few-step sampling. Furthermore, we introduce a novel probabilistic guidance scheme that mitigates the over-saturation issues of CFG and improves image generation quality. Extensive experiments demonstrate that GMFlow consistently outperforms flow matching baselines in generation quality, achieving a Precision of 0.942 with only 6 sampling steps on ImageNet 256$\times$256.
MegaSynth: Scaling Up 3D Scene Reconstruction with Synthesized Data
Dec 18, 2024



We propose scaling up 3D scene reconstruction by training with synthesized data. At the core of our work is MegaSynth, a procedurally generated 3D dataset comprising 700K scenes - over 50 times larger than the prior real dataset DL3DV - dramatically scaling the training data. To enable scalable data generation, our key idea is eliminating semantic information, removing the need to model complex semantic priors such as object affordances and scene composition. Instead, we model scenes with basic spatial structures and geometry primitives, offering scalability. Besides, we control data complexity to facilitate training while loosely aligning it with real-world data distribution to benefit real-world generalization. We explore training LRMs with both MegaSynth and available real data. Experiment results show that joint training or pre-training with MegaSynth improves reconstruction quality by 1.2 to 1.8 dB PSNR across diverse image domains. Moreover, models trained solely on MegaSynth perform comparably to those trained on real data, underscoring the low-level nature of 3D reconstruction. Additionally, we provide an in-depth analysis of MegaSynth's properties for enhancing model capability, training stability, and generalization.
EP-CFG: Energy-Preserving Classifier-Free Guidance
Dec 13, 2024



Classifier-free guidance (CFG) is widely used in diffusion models but often introduces over-contrast and over-saturation artifacts at higher guidance strengths. We present EP-CFG (Energy-Preserving Classifier-Free Guidance), which addresses these issues by preserving the energy distribution of the conditional prediction during the guidance process. Our method simply rescales the energy of the guided output to match that of the conditional prediction at each denoising step, with an optional robust variant for improved artifact suppression. Through experiments, we show that EP-CFG maintains natural image quality and preserves details across guidance strengths while retaining CFG's semantic alignment benefits, all with minimal computational overhead.