 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRIVET: Robust Idempotent Voice Attribute Editing
Jun 17, 2026Voice attribute editing models modify characteristics such as age and gender while preserving speaker identity. In large-scale speech datasets, however, attribute annotations are often noisy or inconsistent, which can cause conditional generative models to produce unstable edits. In this work, we show that idempotency provides an effective mechanism for improving robustness to noisy labels. An idempotent operator is one for which repeated application does not change the result, i.e., f(f(x)) = f(x). Enforcing this property acts as an implicit regularizer that reduces sensitivity to mislabeled examples. We introduce RIVET, a training framework that incorporates an idempotency objective to improve robustness to label noise. We evaluate RIVET under controlled label noise and on the GLOBE dataset with naturally noisy annotations. RIVET improves editing success and better preserves speaker identity than standard training, showing that idempotency improves robustness in voice editing models.
What and When to Learn: CURriculum Ranking Loss for Large-Scale Speaker Verification
Mar 25, 2026Speaker verification at large scale remains an open challenge as fixed-margin losses treat all samples equally regardless of quality. We hypothesize that mislabeled or degraded samples introduce noisy gradients that disrupt compact speaker manifolds. We propose Curry (CURriculum Ranking), an adaptive loss that estimates sample difficulty online via Sub-center ArcFace: confidence scores from dominant sub-center cosine similarity rank samples into easy, medium, and hard tiers using running batch statistics, without auxiliary annotations. Learnable weights guide the model from stable identity foundations through manifold refinement to boundary sharpening. To our knowledge, this is the largest-scale speaker verification system trained to date. Evaluated on VoxCeleb1-O, and SITW, Curry reduces EER by 86.8\% and 60.0\% over the Sub-center ArcFace baseline, establishing a new paradigm for robust speaker verification on imperfect large-scale data.
$φ$-DPO: Fairness Direct Preference Optimization Approach to Continual Learning in Large Multimodal Models
Feb 26, 2026Fairness in Continual Learning for Large Multimodal Models (LMMs) is an emerging yet underexplored challenge, particularly in the presence of imbalanced data distributions that can lead to biased model updates and suboptimal performance across tasks. While recent continual learning studies have made progress in addressing catastrophic forgetting, the problem of fairness caused the imbalanced data remains largely underexplored. This paper presents a novel Fairness Direct Preference Optimization (FaiDPO or $φ$-DPO) framework for continual learning in LMMs. In particular, we first propose a new continual learning paradigm based on Direct Preference Optimization (DPO) to mitigate catastrophic forgetting by aligning learning with pairwise preference signals. Then, we identify the limitations of conventional DPO in imbalanced data and present a new $φ$-DPO loss that explicitly addresses distributional biases. We provide a comprehensive theoretical analysis demonstrating that our approach addresses both forgetting and data imbalance. Additionally, to enable $φ$-DPO-based continual learning, we construct pairwise preference annotations for existing benchmarks in the context of continual learning. Extensive experiments and ablation studies show the proposed $φ$-DPO achieves State-of-the-Art performance across multiple benchmarks, outperforming prior continual learning methods of LMMs.
VerLM: Explaining Face Verification Using Natural Language
Jan 05, 2026Face verification systems have seen substantial advancements; however, they often lack transparency in their decision-making processes. In this paper, we introduce an innovative Vision-Language Model (VLM) for Face Verification, which not only accurately determines if two face images depict the same individual but also explicitly explains the rationale behind its decisions. Our model is uniquely trained using two complementary explanation styles: (1) concise explanations that summarize the key factors influencing its decision, and (2) comprehensive explanations detailing the specific differences observed between the images. We adapt and enhance a state-of-the-art modeling approach originally designed for audio-based differentiation to suit visual inputs effectively. This cross-modal transfer significantly improves our model's accuracy and interpretability. The proposed VLM integrates sophisticated feature extraction techniques with advanced reasoning capabilities, enabling clear articulation of its verification process. Our approach demonstrates superior performance, surpassing baseline methods and existing models. These findings highlight the immense potential of vision language models in face verification set up, contributing to more transparent, reliable, and explainable face verification systems.
AURA Score: A Metric For Holistic Audio Question Answering Evaluation
Oct 06, 2025Audio Question Answering (AQA) is a key task for evaluating Audio-Language Models (ALMs), yet assessing open-ended responses remains challenging. Existing metrics used for AQA such as BLEU, METEOR and BERTScore, mostly adapted from NLP and audio captioning, rely on surface similarity and fail to account for question context, reasoning, and partial correctness. To address the gap in literature, we make three contributions in this work. First, we introduce AQEval to enable systematic benchmarking of AQA metrics. It is the first benchmark of its kind, consisting of 10k model responses annotated by multiple humans for their correctness and relevance. Second, we conduct a comprehensive analysis of existing AQA metrics on AQEval, highlighting weak correlation with human judgment, especially for longer answers. Third, we propose a new metric - AURA score, to better evaluate open-ended model responses. On AQEval, AURA achieves state-of-the-art correlation with human ratings, significantly outperforming all baselines. Through this work, we aim to highlight the limitations of current AQA evaluation methods and motivate better metrics. We release both the AQEval benchmark and the AURA metric to support future research in holistic AQA evaluation.
Image Tokenizer Needs Post-Training
Sep 15, 2025Recent image generative models typically capture the image distribution in a pre-constructed latent space, relying on a frozen image tokenizer. However, there exists a significant discrepancy between the reconstruction and generation distribution, where current tokenizers only prioritize the reconstruction task that happens before generative training without considering the generation errors during sampling. In this paper, we comprehensively analyze the reason for this discrepancy in a discrete latent space, and, from which, we propose a novel tokenizer training scheme including both main-training and post-training, focusing on improving latent space construction and decoding respectively. During the main training, a latent perturbation strategy is proposed to simulate sampling noises, \ie, the unexpected tokens generated in generative inference. Specifically, we propose a plug-and-play tokenizer training scheme, which significantly enhances the robustness of tokenizer, thus boosting the generation quality and convergence speed, and a novel tokenizer evaluation metric, \ie, pFID, which successfully correlates the tokenizer performance to generation quality. During post-training, we further optimize the tokenizer decoder regarding a well-trained generative model to mitigate the distribution difference between generated and reconstructed tokens. With a $\sim$400M generator, a discrete tokenizer trained with our proposed main training achieves a notable 1.60 gFID and further obtains 1.36 gFID with the additional post-training. Further experiments are conducted to broadly validate the effectiveness of our post-training strategy on off-the-shelf discrete and continuous tokenizers, coupled with autoregressive and diffusion-based generators.
Less is More Tokens: Efficient Math Reasoning via Difficulty-Aware Chain-of-Thought Distillation
Sep 05, 2025



Chain-of-thought reasoning, while powerful, can produce unnecessarily verbose output for simpler problems. We present a framework for difficulty-aware reasoning that teaches models to dynamically adjust reasoning depth based on problem complexity. Remarkably, we show that models can be endowed with such dynamic inference pathways without any architectural modifications; we simply post-train on data that is carefully curated to include chain-of-thought traces that are proportional in length to problem difficulty. Our analysis reveals that post-training via supervised fine-tuning (SFT) primarily captures patterns like reasoning length and format, while direct preference optimization (DPO) preserves reasoning accuracy, with their combination reducing length and maintaining or improving performance. Both quantitative metrics and qualitative assessments confirm that models can learn to "think proportionally", reasoning minimally on simple problems while maintaining depth for complex ones.
OleSpeech-IV: A Large-Scale Multispeaker and Multilingual Conversational Speech Dataset with Diverse Topics
Sep 04, 2025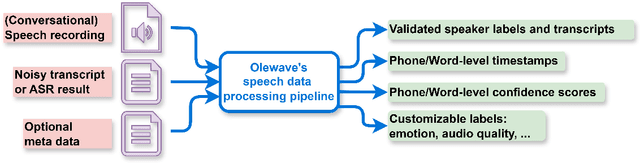
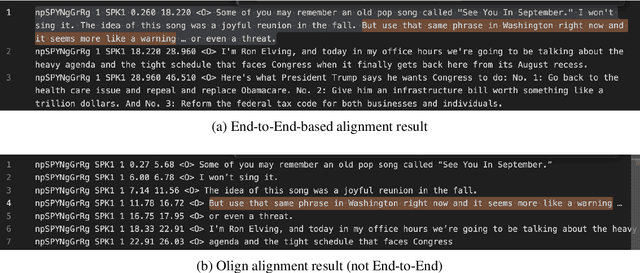
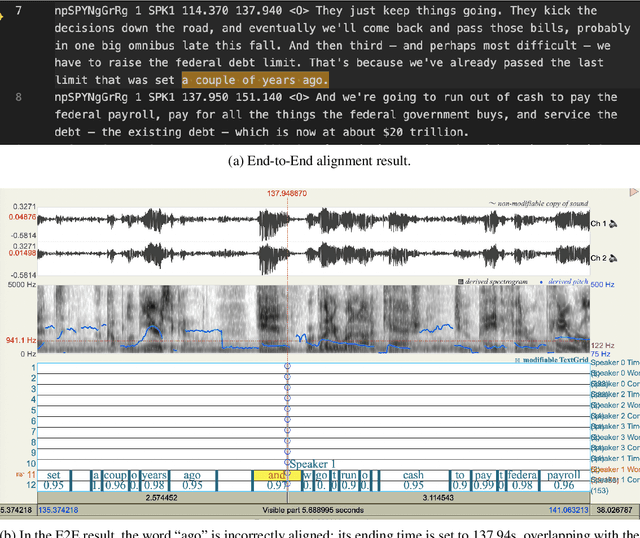
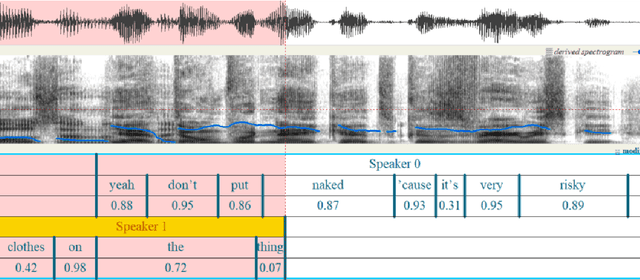
OleSpeech-IV dataset is a large-scale multispeaker and multilingual conversational speech dataset with diverse topics. The audio content comes from publicly-available English podcasts, talk shows, teleconferences, and other conversations. Speaker names, turns, and transcripts are human-sourced and refined by a proprietary pipeline, while additional information such as timestamps and confidence scores is derived from the pipeline. The IV denotes its position as Tier IV in the Olewave dataset series. In addition, we have open-sourced a subset, OleSpeech-IV-2025-EN-AR-100, for non-commercial research use.
Directed-Tokens: A Robust Multi-Modality Alignment Approach to Large Language-Vision Models
Aug 19, 2025Large multimodal models (LMMs) have gained impressive performance due to their outstanding capability in various understanding tasks. However, these models still suffer from some fundamental limitations related to robustness and generalization due to the alignment and correlation between visual and textual features. In this paper, we introduce a simple but efficient learning mechanism for improving the robust alignment between visual and textual modalities by solving shuffling problems. In particular, the proposed approach can improve reasoning capability, visual understanding, and cross-modality alignment by introducing two new tasks: reconstructing the image order and the text order into the LMM's pre-training and fine-tuning phases. In addition, we propose a new directed-token approach to capture visual and textual knowledge, enabling the capability to reconstruct the correct order of visual inputs. Then, we introduce a new Image-to-Response Guided loss to further improve the visual understanding of the LMM in its responses. The proposed approach consistently achieves state-of-the-art (SoTA) performance compared with prior LMMs on academic task-oriented and instruction-following LMM benchmarks.
CarelessWhisper: Turning Whisper into a Causal Streaming Model
Aug 17, 2025Automatic Speech Recognition (ASR) has seen remarkable progress, with models like OpenAI Whisper and NVIDIA Canary achieving state-of-the-art (SOTA) performance in offline transcription. However, these models are not designed for streaming (online or real-time) transcription, due to limitations in their architecture and training methodology. We propose a method to turn the transformer encoder-decoder model into a low-latency streaming model that is careless about future context. We present an analysis explaining why it is not straightforward to convert an encoder-decoder transformer to a low-latency streaming model. Our proposed method modifies the existing (non-causal) encoder to a causal encoder by fine-tuning both the encoder and decoder using Low-Rank Adaptation (LoRA) and a weakly aligned dataset. We then propose an updated inference mechanism that utilizes the fine-tune causal encoder and decoder to yield greedy and beam-search decoding, and is shown to be locally optimal. Experiments on low-latency chunk sizes (less than 300 msec) show that our fine-tuned model outperforms existing non-fine-tuned streaming approaches in most cases, while using a lower complexity. Additionally, we observe that our training process yields better alignment, enabling a simple method for extracting word-level timestamps. We release our training and inference code, along with the fine-tuned models, to support further research and development in streaming ASR.