 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeECon: On the Detection and Resolution of Evidence Conflicts
Oct 05, 2024



The rise of large language models (LLMs) has significantly influenced the quality of information in decision-making systems, leading to the prevalence of AI-generated content and challenges in detecting misinformation and managing conflicting information, or "inter-evidence conflicts." This study introduces a method for generating diverse, validated evidence conflicts to simulate real-world misinformation scenarios. We evaluate conflict detection methods, including Natural Language Inference (NLI) models, factual consistency (FC) models, and LLMs, on these conflicts (RQ1) and analyze LLMs' conflict resolution behaviors (RQ2). Our key findings include: (1) NLI and LLM models exhibit high precision in detecting answer conflicts, though weaker models suffer from low recall; (2) FC models struggle with lexically similar answer conflicts, while NLI and LLM models handle these better; and (3) stronger models like GPT-4 show robust performance, especially with nuanced conflicts. For conflict resolution, LLMs often favor one piece of conflicting evidence without justification and rely on internal knowledge if they have prior beliefs.
SPARTUN3D: Situated Spatial Understanding of 3D World in Large Language Models
Oct 04, 2024Integrating the 3D world into large language models (3D-based LLMs) has been a promising research direction for 3D scene understanding. However, current 3D-based LLMs fall short in situated understanding due to two key limitations: 1) existing 3D datasets are constructed from a global perspective of the 3D scenes and lack situated context. 2) the architectures of existing 3D-based LLMs lack explicit alignment between the spatial representations of 3D scenes and natural language, limiting their performance in tasks requiring precise spatial reasoning. We address these issues by introducing a scalable situated 3D dataset, named Spartun3D, that incorporates various situated spatial reasoning tasks. Furthermore, we propose Spartun3D-LLM, built on an existing 3D-based LLM but integrated with a novel situated spatial alignment module, aiming to enhance the alignment between 3D visual representations and their corresponding textual descriptions. Experimental results demonstrate that both our proposed dataset and alignment module significantly enhance the situated spatial understanding of 3D-based LLMs.
Modeling Layout Reading Order as Ordering Relations for Visually-rich Document Understanding
Sep 29, 2024Modeling and leveraging layout reading order in visually-rich documents (VrDs) is critical in document intelligence as it captures the rich structure semantics within documents. Previous works typically formulated layout reading order as a permutation of layout elements, i.e. a sequence containing all the layout elements. However, we argue that this formulation does not adequately convey the complete reading order information in the layout, which may potentially lead to performance decline in downstream VrD tasks. To address this issue, we propose to model the layout reading order as ordering relations over the set of layout elements, which have sufficient expressive capability for the complete reading order information. To enable empirical evaluation on methods towards the improved form of reading order prediction (ROP), we establish a comprehensive benchmark dataset including the reading order annotation as relations over layout elements, together with a relation-extraction-based method that outperforms previous methods. Moreover, to highlight the practical benefits of introducing the improved form of layout reading order, we propose a reading-order-relation-enhancing pipeline to improve model performance on any arbitrary VrD task by introducing additional reading order relation inputs. Comprehensive results demonstrate that the pipeline generally benefits downstream VrD tasks: (1) with utilizing the reading order relation information, the enhanced downstream models achieve SOTA results on both two task settings of the targeted dataset; (2) with utilizing the pseudo reading order information generated by the proposed ROP model, the performance of the enhanced models has improved across all three models and eight cross-domain VrD-IE/QA task settings without targeted optimization.
A Unified Hallucination Mitigation Framework for Large Vision-Language Models
Sep 24, 2024



Hallucination is a common problem for Large Vision-Language Models (LVLMs) with long generations which is difficult to eradicate. The generation with hallucinations is partially inconsistent with the image content. To mitigate hallucination, current studies either focus on the process of model inference or the results of model generation, but the solutions they design sometimes do not deal appropriately with various types of queries and the hallucinations of the generations about these queries. To accurately deal with various hallucinations, we present a unified framework, Dentist, for hallucination mitigation. The core step is to first classify the queries, then perform different processes of hallucination mitigation based on the classification result, just like a dentist first observes the teeth and then makes a plan. In a simple deployment, Dentist can classify queries as perception or reasoning and easily mitigate potential hallucinations in answers which has been demonstrated in our experiments. On MMbench, we achieve a 13.44%/10.2%/15.8% improvement in accuracy on Image Quality, a Coarse Perception visual question answering (VQA) task, over the baseline InstructBLIP/LLaVA/VisualGLM.
Learning Task Planning from Multi-Modal Demonstration for Multi-Stage Contact-Rich Manipulation
Sep 18, 2024



Large Language Models (LLMs) have gained popularity in task planning for long-horizon manipulation tasks. To enhance the validity of LLM-generated plans, visual demonstrations and online videos have been widely employed to guide the planning process. However, for manipulation tasks involving subtle movements but rich contact interactions, visual perception alone may be insufficient for the LLM to fully interpret the demonstration. Additionally, visual data provides limited information on force-related parameters and conditions, which are crucial for effective execution on real robots. In this paper, we introduce an in-context learning framework that incorporates tactile and force-torque information from human demonstrations to enhance LLMs' ability to generate plans for new task scenarios. We propose a bootstrapped reasoning pipeline that sequentially integrates each modality into a comprehensive task plan. This task plan is then used as a reference for planning in new task configurations. Real-world experiments on two different sequential manipulation tasks demonstrate the effectiveness of our framework in improving LLMs' understanding of multi-modal demonstrations and enhancing the overall planning performance.
Semformer: Transformer Language Models with Semantic Planning
Sep 17, 2024



Next-token prediction serves as the dominant component in current neural language models. During the training phase, the model employs teacher forcing, which predicts tokens based on all preceding ground truth tokens. However, this approach has been found to create shortcuts, utilizing the revealed prefix to spuriously fit future tokens, potentially compromising the accuracy of the next-token predictor. In this paper, we introduce Semformer, a novel method of training a Transformer language model that explicitly models the semantic planning of response. Specifically, we incorporate a sequence of planning tokens into the prefix, guiding the planning token representations to predict the latent semantic representations of the response, which are induced by an autoencoder. In a minimal planning task (i.e., graph path-finding), our model exhibits near-perfect performance and effectively mitigates shortcut learning, a feat that standard training methods and baseline models have been unable to accomplish. Furthermore, we pretrain Semformer from scratch with 125M parameters, demonstrating its efficacy through measures of perplexity, in-context learning, and fine-tuning on summarization tasks.
Gated Slot Attention for Efficient Linear-Time Sequence Modeling
Sep 11, 2024



Linear attention Transformers and their gated variants, celebrated for enabling parallel training and efficient recurrent inference, still fall short in recall-intensive tasks compared to traditional Transformers and demand significant resources for training from scratch. This paper introduces Gated Slot Attention (GSA), which enhances Attention with Bounded-memory-Control (ABC) by incorporating a gating mechanism inspired by Gated Linear Attention (GLA). Essentially, GSA comprises a two-layer GLA linked via softmax, utilizing context-aware memory reading and adaptive forgetting to improve memory capacity while maintaining compact recurrent state size. This design greatly enhances both training and inference efficiency through GLA's hardware-efficient training algorithm and reduced state size. Additionally, retaining the softmax operation is particularly beneficial in "finetuning pretrained Transformers to RNNs" (T2R) settings, reducing the need for extensive training from scratch. Extensive experiments confirm GSA's superior performance in scenarios requiring in-context recall and in T2R settings.
Deep Self-cleansing for Medical Image Segmentation with Noisy Labels
Sep 08, 2024



Medical image segmentation is crucial in the field of medical imaging, aiding in disease diagnosis and surgical planning. Most established segmentation methods rely on supervised deep learning, in which clean and precise labels are essential for supervision and significantly impact the performance of models. However, manually delineated labels often contain noise, such as missing labels and inaccurate boundary delineation, which can hinder networks from correctly modeling target characteristics. In this paper, we propose a deep self-cleansing segmentation framework that can preserve clean labels while cleansing noisy ones in the training phase. To achieve this, we devise a gaussian mixture model-based label filtering module that distinguishes noisy labels from clean labels. Additionally, we develop a label cleansing module to generate pseudo low-noise labels for identified noisy samples. The preserved clean labels and pseudo-labels are then used jointly to supervise the network. Validated on a clinical liver tumor dataset and a public cardiac diagnosis dataset, our method can effectively suppress the interference from noisy labels and achieve prominent segmentation performance.
LAKD-Activation Mapping Distillation Based on Local Learning
Aug 22, 2024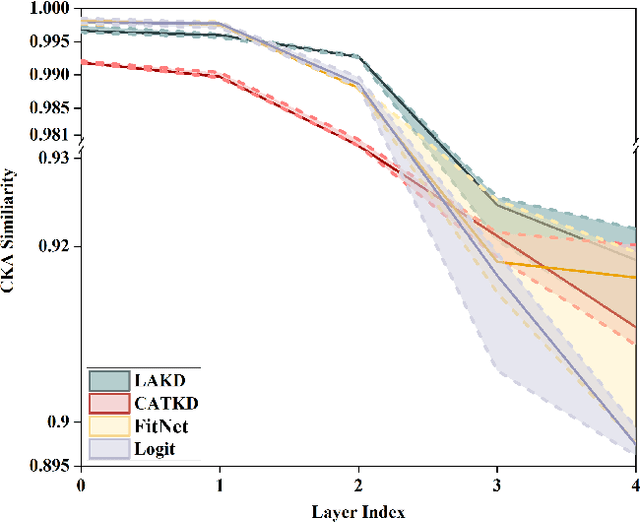
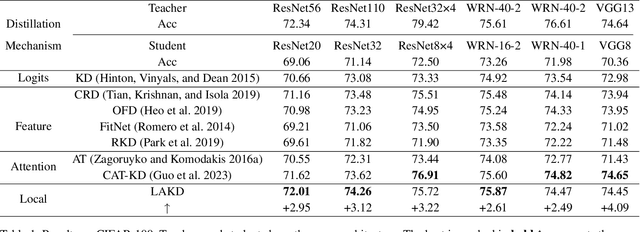
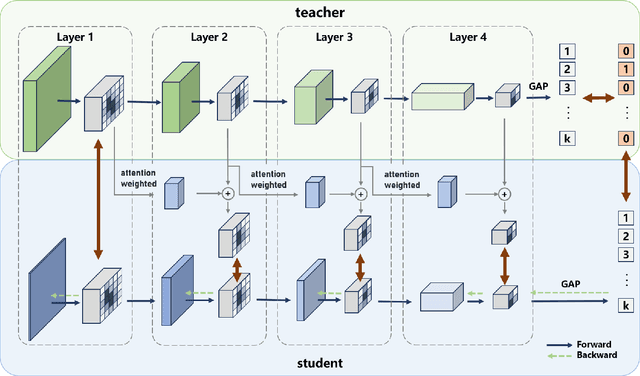

Knowledge distillation is widely applied in various fundamental vision models to enhance the performance of compact models. Existing knowledge distillation methods focus on designing different distillation targets to acquire knowledge from teacher models. However, these methods often overlook the efficient utilization of distilled information, crudely coupling different types of information, making it difficult to explain how the knowledge from the teacher network aids the student network in learning. This paper proposes a novel knowledge distillation framework, Local Attention Knowledge Distillation (LAKD), which more efficiently utilizes the distilled information from teacher networks, achieving higher interpretability and competitive performance. The framework establishes an independent interactive training mechanism through a separation-decoupling mechanism and non-directional activation mapping. LAKD decouples the teacher's features and facilitates progressive interaction training from simple to complex. Specifically, the student network is divided into local modules with independent gradients to decouple the knowledge transferred from the teacher. The non-directional activation mapping helps the student network integrate knowledge from different local modules by learning coarse-grained feature knowledge. We conducted experiments on the CIFAR-10, CIFAR-100, and ImageNet datasets, and the results show that our LAKD method significantly outperforms existing methods, consistently achieving state-of-the-art performance across different datasets.
Personality Alignment of Large Language Models
Aug 21, 2024Current methods for aligning large language models (LLMs) typically aim to reflect general human values and behaviors, but they often fail to capture the unique characteristics and preferences of individual users. To address this gap, we introduce the concept of Personality Alignment. This approach tailors LLMs' responses and decisions to match the specific preferences of individual users or closely related groups. Inspired by psychometrics, we created the Personality Alignment with Personality Inventories (PAPI) dataset, which includes data from 300,000 real subjects, each providing behavioral preferences based on the Big Five Personality Factors. This dataset allows us to quantitatively evaluate the extent to which LLMs can align with each subject's behavioral patterns. Recognizing the challenges of personality alignments: such as limited personal data, diverse preferences, and scalability requirements: we developed an activation intervention optimization method. This method enhances LLMs' ability to efficiently align with individual behavioral preferences using minimal data and computational resources. Remarkably, our method, PAS, achieves superior performance while requiring only 1/5 of the optimization time compared to DPO, offering practical value for personality alignment. Our work paves the way for future AI systems to make decisions and reason in truly personality ways, enhancing the relevance and meaning of AI interactions for each user and advancing human-centered artificial intelligence.The code has released in \url{https://github.com/zhu-minjun/PAlign}.