 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTIDES: Time-Derivative Event Simulation via Deformable Reconstruction
Jun 01, 2026Event cameras emit asynchronous events in response to environmental appearance changes. The scarcity of real-world event datasets makes simulation essential. However, most simulators infer event timestamps from frame sequences, forcing many threshold crossings to share a small set of discrete times; a failure mode we term timestamp batching that worsens under fast motion and occlusion. We present TIDES, a continuous-time event simulator built on dynamic Gaussian splatting. Because TIDES operates on an explicit 3D scene representation with learnt geometry and motion, it can derive per-pixel intensity dynamics directly from the scene, rather than by differencing rendered frames. This enables accurate threshold-crossing prediction, including multiple crossings per rendering step, without temporal upsampling or frame interpolation. The same 3D scene model reveals where objects partially occlude one another; TIDES uses this to guide adaptive time stepping, concentrating computation only in regions where occlusion dynamics make simple models of brightness change unreliable. Finally, we model finite sensor bandwidth using a tile-level arbiter whose throughput, jitter, and event drops reproduce realistic sensor artifacts. Across paired RGB-event benchmarks, TIDES attains state-of-the-art event-stream fidelity. We also show that events simulated by TIDES transfer more effectively to real downstream tasks than competitors'.
Two-stream Multi-dimensional Convolutional Network for Real-time Violence Detection
Nov 08, 2022



The increasing number of surveillance cameras and security concerns have made automatic violent activity detection from surveillance footage an active area for research. Modern deep learning methods have achieved good accuracy in violence detection and proved to be successful because of their applicability in intelligent surveillance systems. However, the models are computationally expensive and large in size because of their inefficient methods for feature extraction. This work presents a novel architecture for violence detection called Two-stream Multi-dimensional Convolutional Network (2s-MDCN), which uses RGB frames and optical flow to detect violence. Our proposed method extracts temporal and spatial information independently by 1D, 2D, and 3D convolutions. Despite combining multi-dimensional convolutional networks, our models are lightweight and efficient due to reduced channel capacity, yet they learn to extract meaningful spatial and temporal information. Additionally, combining RGB frames and optical flow yields 2.2% more accuracy than a single RGB stream. Regardless of having less complexity, our models obtained state-of-the-art accuracy of 89.7% on the largest violence detection benchmark dataset.
Reversed Image Signal Processing and RAW Reconstruction. AIM 2022 Challenge Report
Oct 20, 2022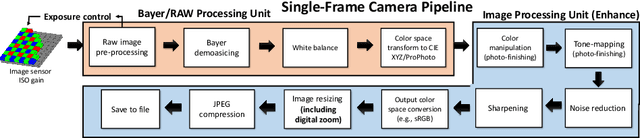
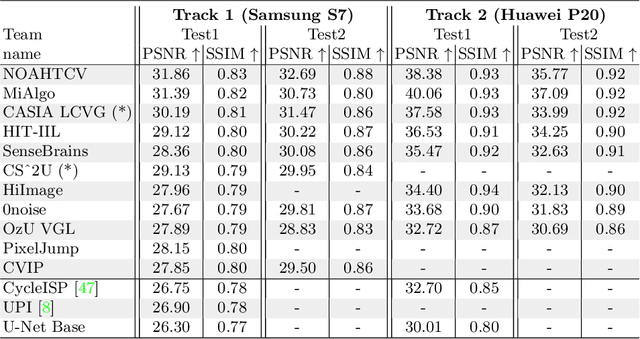
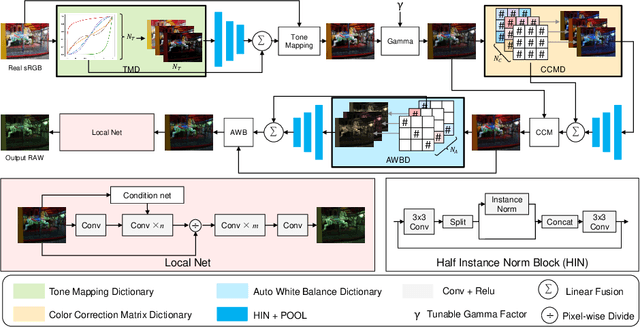
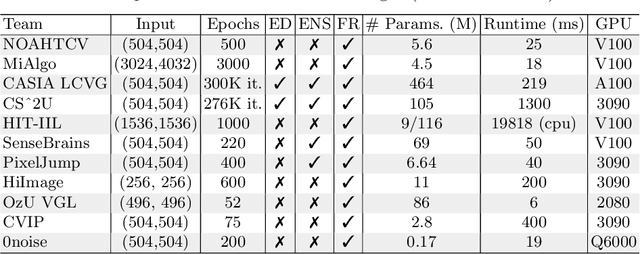
Cameras capture sensor RAW images and transform them into pleasant RGB images, suitable for the human eyes, using their integrated Image Signal Processor (ISP). Numerous low-level vision tasks operate in the RAW domain (e.g. image denoising, white balance) due to its linear relationship with the scene irradiance, wide-range of information at 12bits, and sensor designs. Despite this, RAW image datasets are scarce and more expensive to collect than the already large and public RGB datasets. This paper introduces the AIM 2022 Challenge on Reversed Image Signal Processing and RAW Reconstruction. We aim to recover raw sensor images from the corresponding RGBs without metadata and, by doing this, "reverse" the ISP transformation. The proposed methods and benchmark establish the state-of-the-art for this low-level vision inverse problem, and generating realistic raw sensor readings can potentially benefit other tasks such as denoising and super-resolution.