 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNotes2Skills: From Lab Notebooks to Certainty-Aware Scientific Agent Skills
Jun 10, 2026Scientific discovery workflows usually contain and rely heavily on lab notes, where researchers record observations, interpret uncertain results, and plan follow-up experiments. Such informative lab notes preserve evolving scientific reasoning and author uncertainty, rather than polished final results exhibited in publications, providing a valuable opportunity for AI to engage in scientific exploration at a more comprehensive and deeper level. However, most prior work on scientific text focuses on papers, protocols, or structured databases, leaving informal laboratory notes underexplored as inputs to AI agents for science. This gap matters because lab notes often intermingle validated observations, tentative judgments, and possible experimental next steps within the same passage. If these signals are conflated, an AI agent may mistake uncertain scientific judgments for confirmed conclusions or executable actions. To this end, we present Notes2Skills, a two-stage framework for turning lab notebooks into verifiable skills for scientific AI agents while preserving the author's certainty. Across seven conditions and three wet-lab sessions, Notes2Skills is the only configuration that neither mistakes uncertain notes for firm instructions nor discards firm ones. We show that certainty preservation is the missing piece between lab notebooks and reliable agent skills, opening a path toward safer AI co-scientist systems.
StatefulDiscovery: Evidence-Calibrated Claim Formation in Open-Ended Scientific Discovery
Jun 10, 2026Open-ended scientific discovery asks agents to move beyond executing analyses for predefined questions. Across multiple rounds of exploration, a discovery agent must decide which phenomena warrant investigation while avoiding overinterpretation, where emerging claims exceed the evidential scope of the analyses supporting them. This creates an evidence-calibration problem: the exploration trajectory must be coupled with claim status so that evidence can guide both what to investigate next and what can be claimed. We introduce StatefulDiscovery, a discovery framework that externalizes investigation state and uses it to coordinate frontier selection, evidence acquisition, and claim adjudication. We evaluate StatefulDiscovery across 40 real-data discovery tasks. Compared with several baselines, StatefulDiscovery produces more claims overall judged to be both well-supported and high-value. Ablations indicate that structured hypotheses, local adjudication, and frontier control contribute to performance. Together, these results suggest that explicit discovery state can couple exploration with evidence-calibrated claim formation.
PreAct-Bench: Benchmarking Predictive Monitoring in LLMs
Jun 03, 2026Large language models (LLMs) are increasingly deployed as autonomous agents capable of executing multi-step action trajectories toward a given objective. While existing safety research has focused on detecting unethical behavior from complete trajectories, this paradigm is fundamentally retrospective: it identifies harm only after it has already occurred. In this work, we study a critical yet overlooked safety task, which we term Predictive Monitoring: given only a partial action trajectory, can a model infer whether it will culminate in an unethical action before the overt action is executed? To support this task, we present PreActBench, a benchmark of 1,000 paired ethical and unethical action trajectories spanning five domains. We evaluate a range of LLMs, safety guardrail models, and latent probing methods across varying fractions of the action trajectory using our Prefix Foresight F1 metric. Results show that while humans achieve promising performance, predictive monitoring remains challenging even for strong models, highlighting the need for future-oriented risk reasoning in LLM safety.
CreativeBench: Benchmarking and Enhancing Machine Creativity via Self-Evolving Challenges
Mar 12, 2026The saturation of high-quality pre-training data has shifted research focus toward evolutionary systems capable of continuously generating novel artifacts, leading to the success of AlphaEvolve. However, the progress of such systems is hindered by the lack of rigorous, quantitative evaluation. To tackle this challenge, we introduce CreativeBench, a benchmark for evaluating machine creativity in code generation, grounded in a classical cognitive framework. Comprising two subsets -- CreativeBench-Combo and CreativeBench-Explore -- the benchmark targets combinatorial and exploratory creativity through an automated pipeline utilizing reverse engineering and self-play. By leveraging executable code, CreativeBench objectively distinguishes creativity from hallucination via a unified metric defined as the product of quality and novelty. Our analysis of state-of-the-art models reveals distinct behaviors: (1) scaling significantly improves combinatorial creativity but yields diminishing returns for exploration; (2) larger models exhibit ``convergence-by-scaling,'' becoming more correct but less divergent; and (3) reasoning capabilities primarily benefit constrained exploration rather than combination. Finally, we propose EvoRePE, a plug-and-play inference-time steering strategy that internalizes evolutionary search patterns to consistently enhance machine creativity.
MemPot: Defending Against Memory Extraction Attack with Optimized Honeypots
Feb 07, 2026Large Language Model (LLM)-based agents employ external and internal memory systems to handle complex, goal-oriented tasks, yet this exposes them to severe extraction attacks, and effective defenses remain lacking. In this paper, we propose MemPot, the first theoretically verified defense framework against memory extraction attacks by injecting optimized honeypots into the memory. Through a two-stage optimization process, MemPot generates trap documents that maximize the retrieval probability for attackers while remaining inconspicuous to benign users. We model the detection process as Wald's Sequential Probability Ratio Test (SPRT) and theoretically prove that MemPot achieves a lower average number of sampling rounds compared to optimal static detectors. Empirically, MemPot significantly outperforms state-of-the-art baselines, achieving a 50% improvement in detection AUROC and an 80% increase in True Positive Rate under low False Positive Rate constraints. Furthermore, our experiments confirm that MemPot incurs zero additional online inference latency and preserves the agent's utility on standard tasks, verifying its superiority in safety, harmlessness, and efficiency.
AMA: Adaptive Memory via Multi-Agent Collaboration
Jan 28, 2026The rapid evolution of Large Language Model (LLM) agents has necessitated robust memory systems to support cohesive long-term interaction and complex reasoning. Benefiting from the strong capabilities of LLMs, recent research focus has shifted from simple context extension to the development of dedicated agentic memory systems. However, existing approaches typically rely on rigid retrieval granularity, accumulation-heavy maintenance strategies, and coarse-grained update mechanisms. These design choices create a persistent mismatch between stored information and task-specific reasoning demands, while leading to the unchecked accumulation of logical inconsistencies over time. To address these challenges, we propose Adaptive Memory via Multi-Agent Collaboration (AMA), a novel framework that leverages coordinated agents to manage memory across multiple granularities. AMA employs a hierarchical memory design that dynamically aligns retrieval granularity with task complexity. Specifically, the Constructor and Retriever jointly enable multi-granularity memory construction and adaptive query routing. The Judge verifies the relevance and consistency of retrieved content, triggering iterative retrieval when evidence is insufficient or invoking the Refresher upon detecting logical conflicts. The Refresher then enforces memory consistency by performing targeted updates or removing outdated entries. Extensive experiments on challenging long-context benchmarks show that AMA significantly outperforms state-of-the-art baselines while reducing token consumption by approximately 80% compared to full-context methods, demonstrating its effectiveness in maintaining retrieval precision and long-term memory consistency.
Jailbreaking Attacks vs. Content Safety Filters: How Far Are We in the LLM Safety Arms Race?
Dec 30, 2025As large language models (LLMs) are increasingly deployed, ensuring their safe use is paramount. Jailbreaking, adversarial prompts that bypass model alignment to trigger harmful outputs, present significant risks, with existing studies reporting high success rates in evading common LLMs. However, previous evaluations have focused solely on the models, neglecting the full deployment pipeline, which typically incorporates additional safety mechanisms like content moderation filters. To address this gap, we present the first systematic evaluation of jailbreak attacks targeting LLM safety alignment, assessing their success across the full inference pipeline, including both input and output filtering stages. Our findings yield two key insights: first, nearly all evaluated jailbreak techniques can be detected by at least one safety filter, suggesting that prior assessments may have overestimated the practical success of these attacks; second, while safety filters are effective in detection, there remains room to better balance recall and precision to further optimize protection and user experience. We highlight critical gaps and call for further refinement of detection accuracy and usability in LLM safety systems.
See-Control: A Multimodal Agent Framework for Smartphone Interaction with a Robotic Arm
Dec 09, 2025Recent advances in Multimodal Large Language Models (MLLMs) have enabled their use as intelligent agents for smartphone operation. However, existing methods depend on the Android Debug Bridge (ADB) for data transmission and action execution, limiting their applicability to Android devices. In this work, we introduce the novel Embodied Smartphone Operation (ESO) task and present See-Control, a framework that enables smartphone operation via direct physical interaction with a low-DoF robotic arm, offering a platform-agnostic solution. See-Control comprises three key components: (1) an ESO benchmark with 155 tasks and corresponding evaluation metrics; (2) an MLLM-based embodied agent that generates robotic control commands without requiring ADB or system back-end access; and (3) a richly annotated dataset of operation episodes, offering valuable resources for future research. By bridging the gap between digital agents and the physical world, See-Control provides a concrete step toward enabling home robots to perform smartphone-dependent tasks in realistic environments.
Causal Sufficiency and Necessity Improves Chain-of-Thought Reasoning
Jun 11, 2025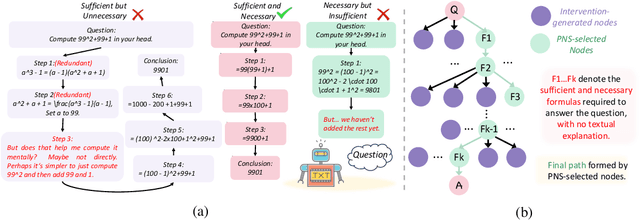
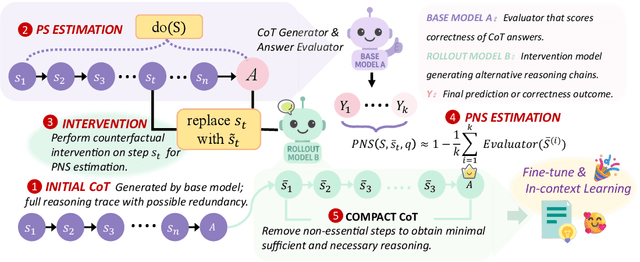
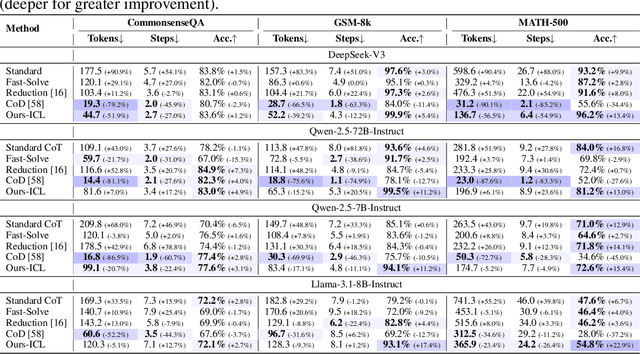
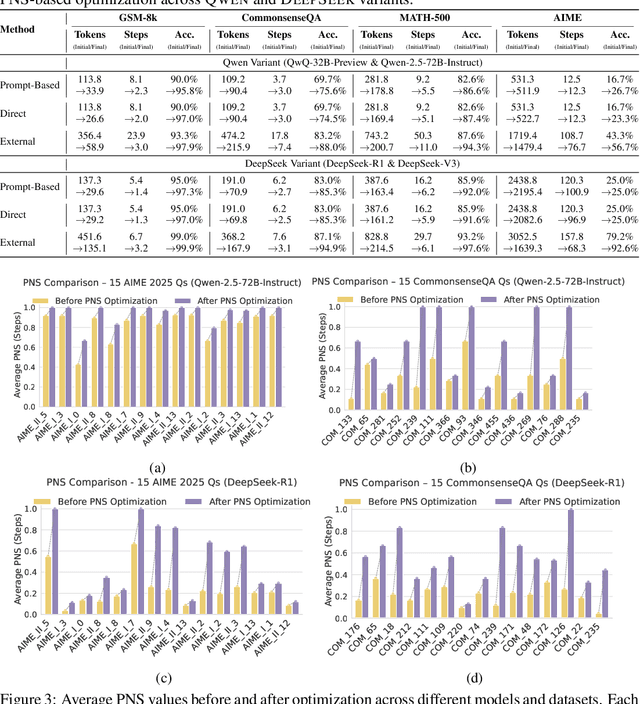
Chain-of-Thought (CoT) prompting plays an indispensable role in endowing large language models (LLMs) with complex reasoning capabilities. However, CoT currently faces two fundamental challenges: (1) Sufficiency, which ensures that the generated intermediate inference steps comprehensively cover and substantiate the final conclusion; and (2) Necessity, which identifies the inference steps that are truly indispensable for the soundness of the resulting answer. We propose a causal framework that characterizes CoT reasoning through the dual lenses of sufficiency and necessity. Incorporating causal Probability of Sufficiency and Necessity allows us not only to determine which steps are logically sufficient or necessary to the prediction outcome, but also to quantify their actual influence on the final reasoning outcome under different intervention scenarios, thereby enabling the automated addition of missing steps and the pruning of redundant ones. Extensive experimental results on various mathematical and commonsense reasoning benchmarks confirm substantial improvements in reasoning efficiency and reduced token usage without sacrificing accuracy. Our work provides a promising direction for improving LLM reasoning performance and cost-effectiveness.
ReMA: Learning to Meta-think for LLMs with Multi-Agent Reinforcement Learning
Mar 12, 2025Recent research on Reasoning of Large Language Models (LLMs) has sought to further enhance their performance by integrating meta-thinking -- enabling models to monitor, evaluate, and control their reasoning processes for more adaptive and effective problem-solving. However, current single-agent work lacks a specialized design for acquiring meta-thinking, resulting in low efficacy. To address this challenge, we introduce Reinforced Meta-thinking Agents (ReMA), a novel framework that leverages Multi-Agent Reinforcement Learning (MARL) to elicit meta-thinking behaviors, encouraging LLMs to think about thinking. ReMA decouples the reasoning process into two hierarchical agents: a high-level meta-thinking agent responsible for generating strategic oversight and plans, and a low-level reasoning agent for detailed executions. Through iterative reinforcement learning with aligned objectives, these agents explore and learn collaboration, leading to improved generalization and robustness. Experimental results demonstrate that ReMA outperforms single-agent RL baselines on complex reasoning tasks, including competitive-level mathematical benchmarks and LLM-as-a-Judge benchmarks. Comprehensive ablation studies further illustrate the evolving dynamics of each distinct agent, providing valuable insights into how the meta-thinking reasoning process enhances the reasoning capabilities of LLMs.